 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReddit-Impacts: A Named Entity Recognition Dataset for Analyzing Clinical and Social Effects of Substance Use Derived from Social Media
May 09, 2024



Substance use disorders (SUDs) are a growing concern globally, necessitating enhanced understanding of the problem and its trends through data-driven research. Social media are unique and important sources of information about SUDs, particularly since the data in such sources are often generated by people with lived experiences. In this paper, we introduce Reddit-Impacts, a challenging Named Entity Recognition (NER) dataset curated from subreddits dedicated to discussions on prescription and illicit opioids, as well as medications for opioid use disorder. The dataset specifically concentrates on the lesser-studied, yet critically important, aspects of substance use--its clinical and social impacts. We collected data from chosen subreddits using the publicly available Application Programming Interface for Reddit. We manually annotated text spans representing clinical and social impacts reported by people who also reported personal nonmedical use of substances including but not limited to opioids, stimulants and benzodiazepines. Our objective is to create a resource that can enable the development of systems that can automatically detect clinical and social impacts of substance use from text-based social media data. The successful development of such systems may enable us to better understand how nonmedical use of substances affects individual health and societal dynamics, aiding the development of effective public health strategies. In addition to creating the annotated data set, we applied several machine learning models to establish baseline performances. Specifically, we experimented with transformer models like BERT, and RoBERTa, one few-shot learning model DANN by leveraging the full training dataset, and GPT-3.5 by using one-shot learning, for automatic NER of clinical and social impacts. The dataset has been made available through the 2024 SMM4H shared tasks.
Evaluating Large Language Models for Health-Related Text Classification Tasks with Public Social Media Data
Mar 27, 2024



Large language models (LLMs) have demonstrated remarkable success in NLP tasks. However, there is a paucity of studies that attempt to evaluate their performances on social media-based health-related natural language processing tasks, which have traditionally been difficult to achieve high scores in. We benchmarked one supervised classic machine learning model based on Support Vector Machines (SVMs), three supervised pretrained language models (PLMs) based on RoBERTa, BERTweet, and SocBERT, and two LLM based classifiers (GPT3.5 and GPT4), across 6 text classification tasks. We developed three approaches for leveraging LLMs for text classification: employing LLMs as zero-shot classifiers, us-ing LLMs as annotators to annotate training data for supervised classifiers, and utilizing LLMs with few-shot examples for augmentation of manually annotated data. Our comprehensive experiments demonstrate that employ-ing data augmentation using LLMs (GPT-4) with relatively small human-annotated data to train lightweight supervised classification models achieves superior results compared to training with human-annotated data alone. Supervised learners also outperform GPT-4 and GPT-3.5 in zero-shot settings. By leveraging this data augmentation strategy, we can harness the power of LLMs to develop smaller, more effective domain-specific NLP models. LLM-annotated data without human guidance for training light-weight supervised classification models is an ineffective strategy. However, LLM, as a zero-shot classifier, shows promise in excluding false negatives and potentially reducing the human effort required for data annotation. Future investigations are imperative to explore optimal training data sizes and the optimal amounts of augmented data.
Explainable Machine Learning-Based Security and Privacy Protection Framework for Internet of Medical Things Systems
Mar 14, 2024The Internet of Medical Things (IoMT) transcends traditional medical boundaries, enabling a transition from reactive treatment to proactive prevention. This innovative method revolutionizes healthcare by facilitating early disease detection and tailored care, particularly in chronic disease management, where IoMT automates treatments based on real-time health data collection. Nonetheless, its benefits are countered by significant security challenges that endanger the lives of its users due to the sensitivity and value of the processed data, thereby attracting malicious interests. Moreover, the utilization of wireless communication for data transmission exposes medical data to interception and tampering by cybercriminals. Additionally, anomalies may arise due to human errors, network interference, or hardware malfunctions. In this context, anomaly detection based on Machine Learning (ML) is an interesting solution, but it comes up against obstacles in terms of explicability and protection of privacy. To address these challenges, a new framework for Intrusion Detection Systems (IDS) is introduced, leveraging Artificial Neural Networks (ANN) for intrusion detection while utilizing Federated Learning (FL) for privacy preservation. Additionally, eXplainable Artificial Intelligence (XAI) methods are incorporated to enhance model explanation and interpretation. The efficacy of the proposed framework is evaluated and compared with centralized approaches using multiple datasets containing network and medical data, simulating various attack types impacting the confidentiality, integrity, and availability of medical and physiological data. The results obtained offer compelling evidence that the FL method performs comparably to the centralized method, demonstrating high performance. Additionally, it affords the dual advantage of safeguarding privacy and providing model explanation.
Machine Learning Applications in Studying Mental Health Among Immigrants and Racial and Ethnic Minorities: A Systematic Review
Apr 18, 2023Background: The use of machine learning (ML) in mental health (MH) research is increasing, especially as new, more complex data types become available to analyze. By systematically examining the published literature, this review aims to uncover potential gaps in the current use of ML to study MH in vulnerable populations of immigrants, refugees, migrants, and racial and ethnic minorities. Methods: In this systematic review, we queried Google Scholar for ML-related terms, MH-related terms, and a population of a focus search term strung together with Boolean operators. Backward reference searching was also conducted. Included peer-reviewed studies reported using a method or application of ML in an MH context and focused on the populations of interest. We did not have date cutoffs. Publications were excluded if they were narrative or did not exclusively focus on a minority population from the respective country. Data including study context, the focus of mental healthcare, sample, data type, type of ML algorithm used, and algorithm performance was extracted from each. Results: Our search strategies resulted in 67,410 listed articles from Google Scholar. Ultimately, 12 were included. All the articles were published within the last 6 years, and half of them studied populations within the US. Most reviewed studies used supervised learning to explain or predict MH outcomes. Some publications used up to 16 models to determine the best predictive power. Almost half of the included publications did not discuss their cross-validation method. Conclusions: The included studies provide proof-of-concept for the potential use of ML algorithms to address MH concerns in these special populations, few as they may be. Our systematic review finds that the clinical application of these models for classifying and predicting MH disorders is still under development.
Adopting the Multi-answer Questioning Task with an Auxiliary Metric for Extreme Multi-label Text Classification Utilizing the Label Hierarchy
Mar 02, 2023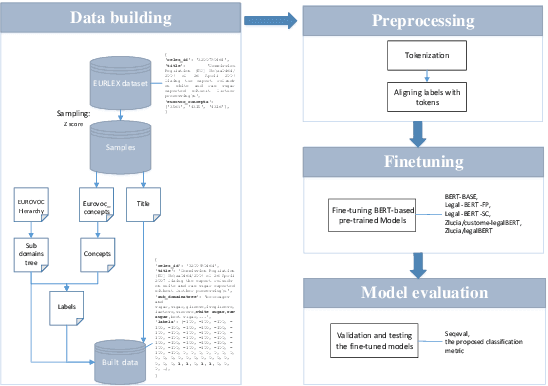

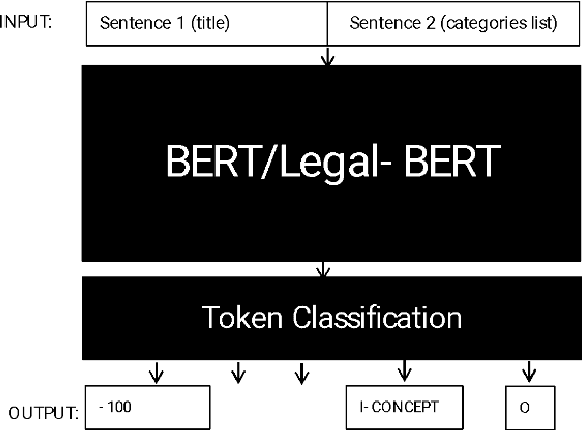
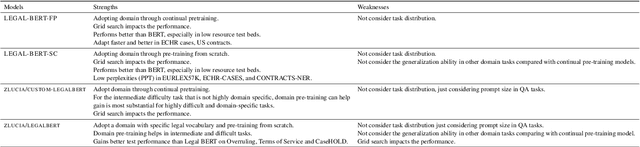
Extreme multi-label text classification utilizes the label hierarchy to partition extreme labels into multiple label groups, turning the task into simple multi-group multi-label classification tasks. Current research encodes labels as a vector with fixed length which needs establish multiple classifiers for different label groups. The problem is how to build only one classifier without sacrificing the label relationship in the hierarchy. This paper adopts the multi-answer questioning task for extreme multi-label classification. This paper also proposes an auxiliary classification evaluation metric. This study adopts the proposed method and the evaluation metric to the legal domain. The utilization of legal Berts and the study on task distribution are discussed. The experiment results show that the proposed hierarchy and multi-answer questioning task can do extreme multi-label classification for EURLEX dataset. And in minor/fine-tuning the multi-label classification task, the domain adapted BERT models could not show apparent advantages in this experiment. The method is also theoretically applicable to zero-shot learning.
Few-shot learning for medical text: A systematic review
Apr 21, 2022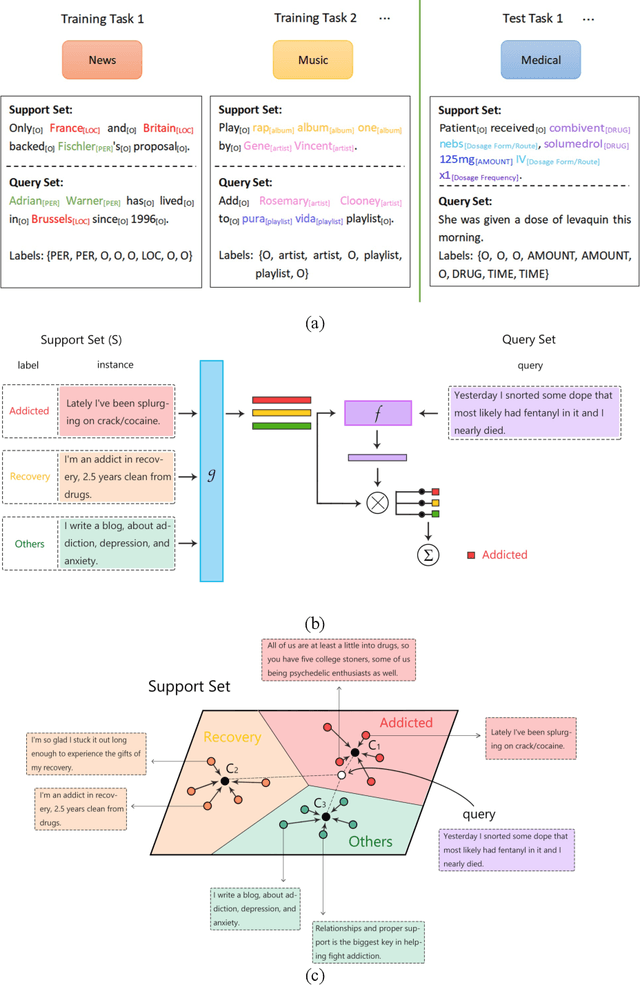
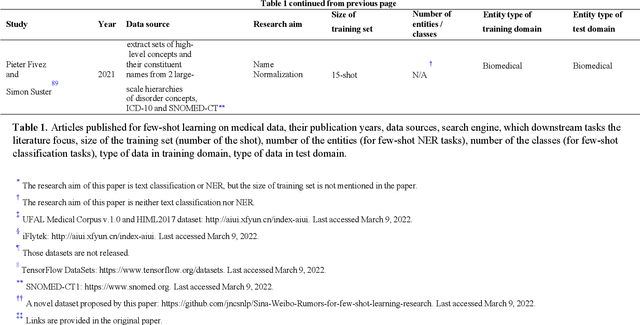
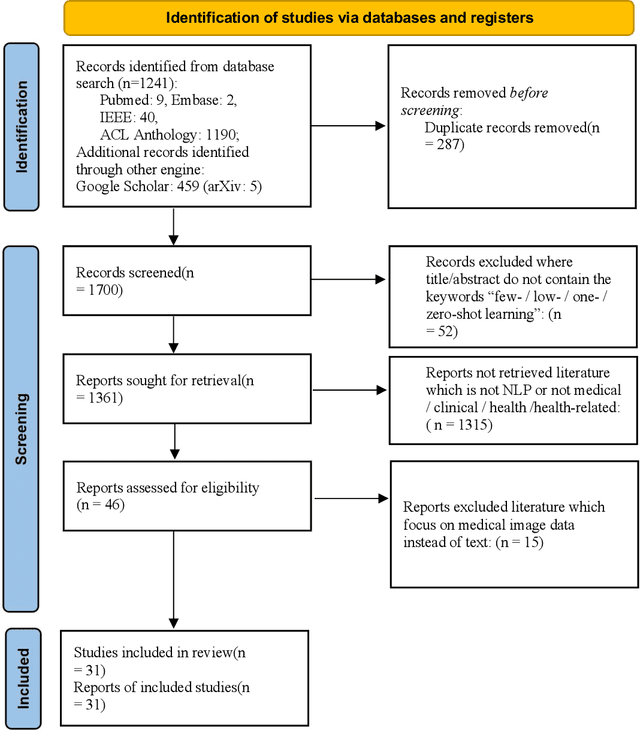
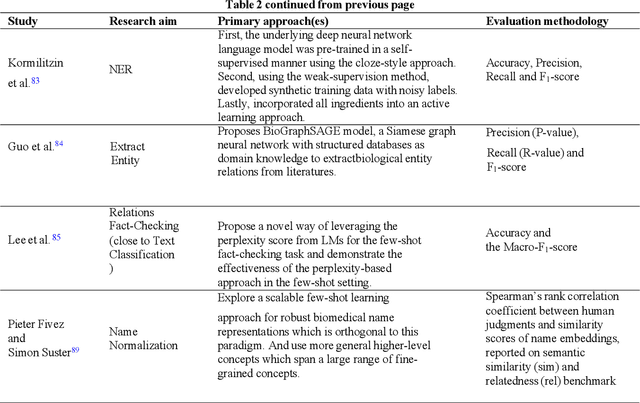
Objective: Few-shot learning (FSL) methods require small numbers of labeled instances for training. As many medical topics have limited annotated textual data in practical settings, FSL-based natural language processing (NLP) methods hold substantial promise. We aimed to conduct a systematic review to explore the state of FSL methods for medical NLP. Materials and Methods: We searched for articles published between January 2016 and August 2021 using PubMed/Medline, Embase, ACL Anthology, and IEEE Xplore Digital Library. To identify the latest relevant methods, we also searched other sources such as preprint servers (eg., medRxiv) via Google Scholar. We included all articles that involved FSL and any type of medical text. We abstracted articles based on data source(s), aim(s), training set size(s), primary method(s)/approach(es), and evaluation method(s). Results: 31 studies met our inclusion criteria-all published after 2018; 22 (71%) since 2020. Concept extraction/named entity recognition was the most frequently addressed task (13/31; 42%), followed by text classification (10/31; 32%). Twenty-one (68%) studies reconstructed existing datasets to create few-shot scenarios synthetically, and MIMIC-III was the most frequently used dataset (7/31; 23%). Common methods included FSL with attention mechanisms (12/31; 39%), prototypical networks (8/31; 26%), and meta-learning (6/31; 19%). Discussion: Despite the potential for FSL in biomedical NLP, progress has been limited compared to domain-independent FSL. This may be due to the paucity of standardized, public datasets, and the relative underperformance of FSL methods on biomedical topics. Creation and release of specialized datasets for biomedical FSL may aid method development by enabling comparative analyses.
Survey of Machine Learning Based Intrusion Detection Methods for Internet of Medical Things
Feb 19, 2022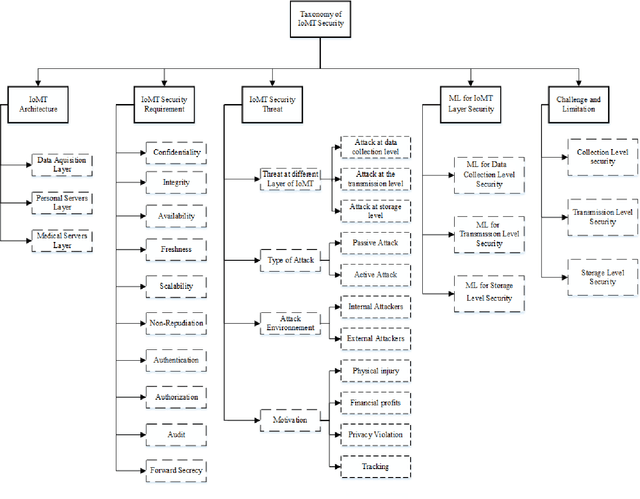

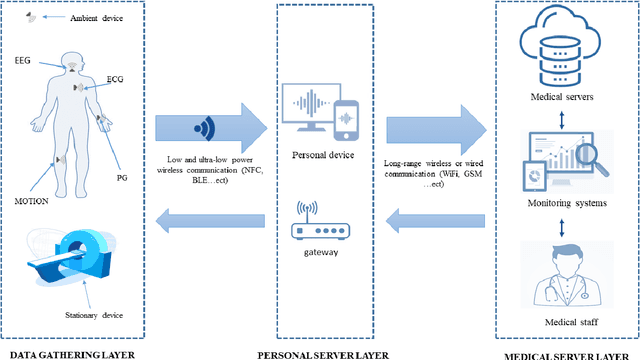
Internet of Medical Things (IoMT) represents an application of the Internet of Things, where health professionals perform remote analysis of physiological data collected using sensors that are associated with patients, allowing real-time and permanent monitoring of the patient's health condition and the detection of possible diseases at an early stage. However, the use of wireless communication for data transfer exposes this data to cyberattacks, and the sensitive and private nature of this data may represent a prime interest for attackers. The use of traditional security methods on equipment that is limited in terms of storage and computing capacity is ineffective. In this context, we have performed a comprehensive survey to investigate the use of the intrusion detection system based on machine learning (ML) for IoMT security. We presented the generic three-layer architecture of IoMT, the security requirement of IoMT security. We review the various threats that can affect IoMT security and identify the advantage, disadvantages, methods, and datasets used in each solution based on ML. Then we provide some challenges and limitations of applying ML on each layer of IoMT, which can serve as direction for future study.
Design Challenges of Multi-UAV Systems in Cyber-Physical Applications: A Comprehensive Survey, and Future Directions
Oct 23, 2018
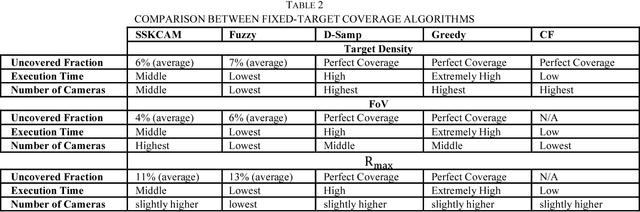
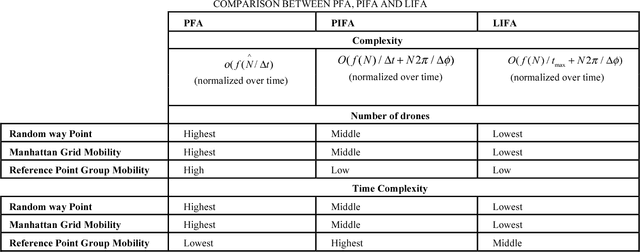
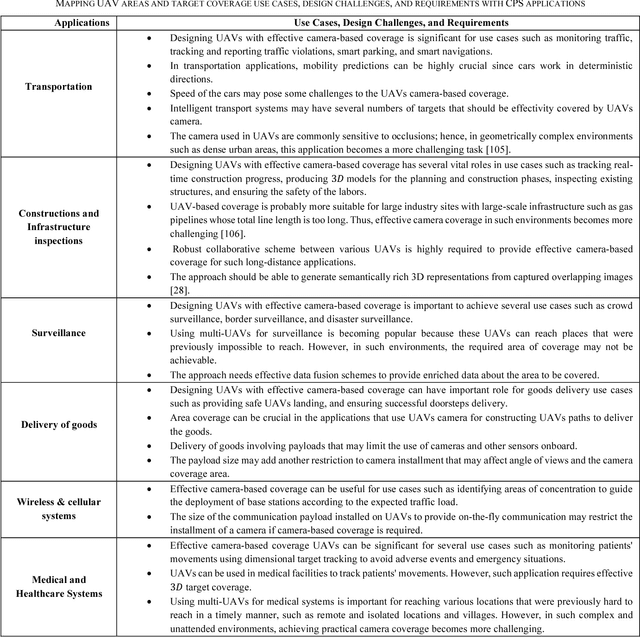
Unmanned Aerial Vehicles (UAVs) have recently rapidly grown to facilitate a wide range of innovative applications that can fundamentally change the way cyber-physical systems (CPSs) are designed. CPSs are a modern generation of systems with synergic cooperation between computational and physical potentials that can interact with humans through several new mechanisms. The main advantages of using UAVs in CPS application is their exceptional features, including their mobility, dynamism, effortless deployment, adaptive altitude, agility, adjustability, and effective appraisal of real-world functions anytime and anywhere. Furthermore, from the technology perspective, UAVs are predicted to be a vital element of the development of advanced CPSs. Therefore, in this survey, we aim to pinpoint the most fundamental and important design challenges of multi-UAV systems for CPS applications. We highlight key and versatile aspects that span the coverage and tracking of targets and infrastructure objects, energy-efficient navigation, and image analysis using machine learning for fine-grained CPS applications. Key prototypes and testbeds are also investigated to show how these practical technologies can facilitate CPS applications. We present and propose state-of-the-art algorithms to address design challenges with both quantitative and qualitative methods and map these challenges with important CPS applications to draw insightful conclusions on the challenges of each application. Finally, we summarize potential new directions and ideas that could shape future research in these areas.
A Survey of Machine and Deep Learning Methods for Internet of Things Security
Jul 29, 2018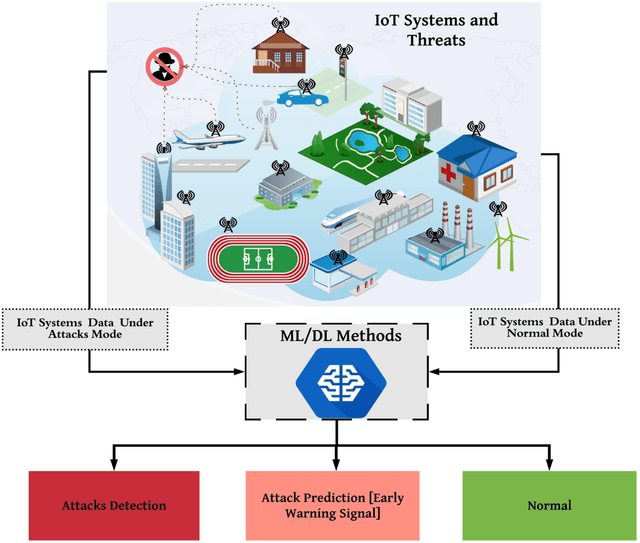
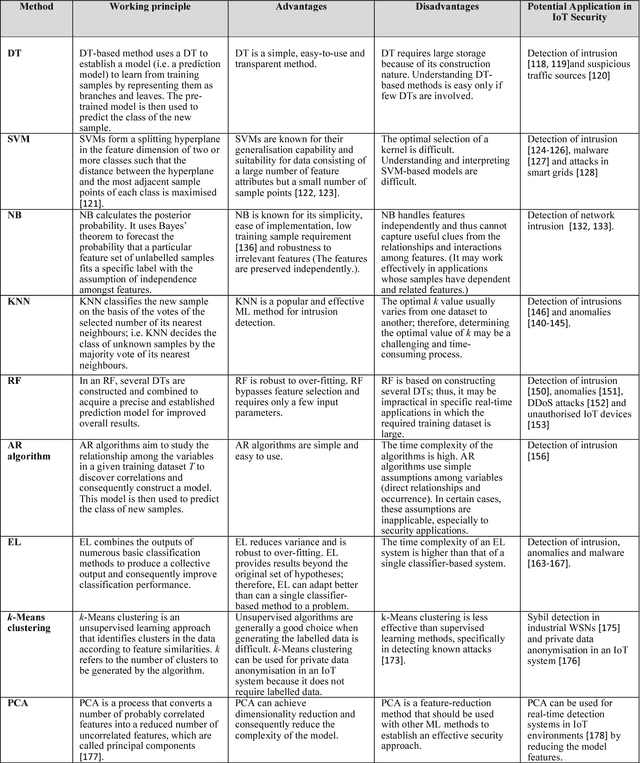
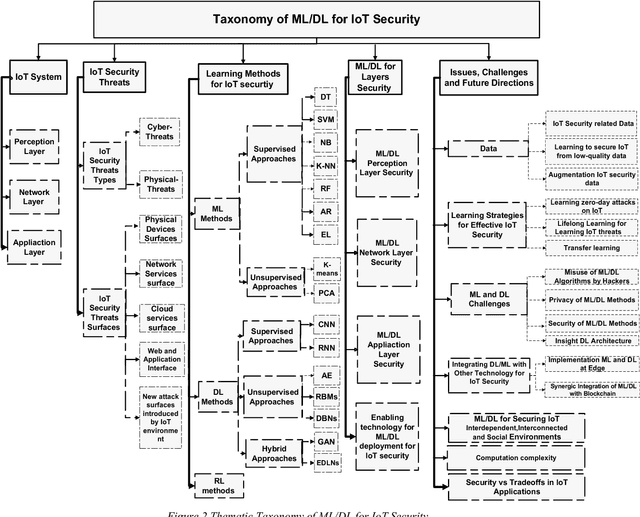
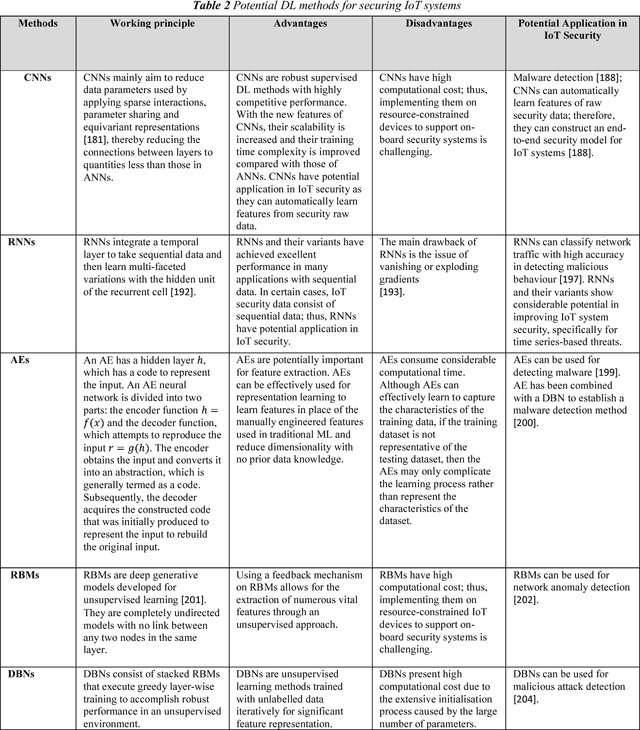
The Internet of Things (IoT) integrates billions of smart devices that can communicate with one another with minimal human intervention. It is one of the fastest developing fields in the history of computing, with an estimated 50 billion devices by the end of 2020. On the one hand, IoT play a crucial role in enhancing several real-life smart applications that can improve life quality. On the other hand, the crosscutting nature of IoT systems and the multidisciplinary components involved in the deployment of such systems introduced new security challenges. Implementing security measures, such as encryption, authentication, access control, network security and application security, for IoT devices and their inherent vulnerabilities is ineffective. Therefore, existing security methods should be enhanced to secure the IoT system effectively. Machine learning and deep learning (ML/DL) have advanced considerably over the last few years, and machine intelligence has transitioned from laboratory curiosity to practical machinery in several important applications. Consequently, ML/DL methods are important in transforming the security of IoT systems from merely facilitating secure communication between devices to security-based intelligence systems. The goal of this work is to provide a comprehensive survey of ML /DL methods that can be used to develop enhanced security methods for IoT systems. IoT security threats that are related to inherent or newly introduced threats are presented, and various potential IoT system attack surfaces and the possible threats related to each surface are discussed. We then thoroughly review ML/DL methods for IoT security and present the opportunities, advantages and shortcomings of each method. We discuss the opportunities and challenges involved in applying ML/DL to IoT security. These opportunities and challenges can serve as potential future research directions.