 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Prediction of Liver Cirrhosis Up to Three Years in Advance: A Machine Learning Study Benchmarking Against the FIB-4 Score
Jan 01, 2026Objective: Develop and evaluate machine learning (ML) models for predicting incident liver cirrhosis one, two, and three years prior to diagnosis using routinely collected electronic health record (EHR) data, and to benchmark their performance against the FIB-4 score. Methods: We conducted a retrospective cohort study using de-identified EHR data from a large academic health system. Patients with fatty liver disease were identified and categorized into cirrhosis and non-cirrhosis cohorts based on ICD-9/10 codes. Prediction scenarios were constructed using observation and prediction windows to emulate real-world clinical use. Demographics, diagnoses, laboratory results, vital signs, and comorbidity indices were aggregated from the observation window. XGBoost models were trained for 1-, 2-, and 3-year prediction horizons and evaluated on held-out test sets. Model performance was compared with FIB-4 using area under the receiver operating characteristic curve (AUC). Results: Final cohorts included 3,043 patients for the 1-year prediction, 1,981 for the 2-year prediction, and 1,470 for the 3-year prediction. Across all prediction windows, ML models consistently outperformed FIB-4. The XGBoost models achieved AUCs of 0.81, 0.73, and 0.69 for 1-, 2-, and 3-year predictions, respectively, compared with 0.71, 0.63, and 0.57 for FIB-4. Performance gains persisted with longer prediction horizons, indicating improved early risk discrimination. Conclusions: Machine learning models leveraging routine EHR data substantially outperform the traditional FIB-4 score for early prediction of liver cirrhosis. These models enable earlier and more accurate risk stratification and can be integrated into clinical workflows as automated decision-support tools to support proactive cirrhosis prevention and management.
Deep Learning-Based Forecasting of Boarding Patient Counts to Address ED Overcrowding
May 20, 2025This study develops deep learning models to forecast the number of patients in the emergency department (ED) boarding phase six hours in advance, aiming to support proactive operational decision-making using only non-clinical, operational, and contextual features. Data were collected from five sources: ED tracking systems, inpatient census records, weather reports, federal holiday calendars, and local event schedules. After feature engineering, the data were aggregated at an hourly level, cleaned, and merged into a unified dataset for model training. Several time series deep learning models, including ResNetPlus, TSTPlus, TSiTPlus (from the tsai library), and N-BEATSx, were trained using Optuna and grid search for hyperparameter tuning. The average ED boarding count was 28.7, with a standard deviation of 11.2. N-BEATSx achieved the best performance, with a mean absolute error of 2.10, mean squared error of 7.08, root mean squared error of 2.66, and a coefficient of determination of 0.95. The model maintained stable accuracy even during periods of extremely high boarding counts, defined as values exceeding one, two, or three standard deviations above the mean. Results show that accurate six-hour-ahead forecasts are achievable without using patient-level clinical data. While strong performance was observed even with a basic feature set, the inclusion of additional features improved prediction stability under extreme conditions. This framework offers a practical and generalizable approach for hospital systems to anticipate boarding levels and help mitigate ED overcrowding.
An Artificial Intelligence-Based Framework for Predicting Emergency Department Overcrowding: Development and Evaluation Study
Apr 23, 2025Background: Emergency department (ED) overcrowding remains a major challenge, causing delays in care and increased operational strain. Hospital management often reacts to congestion after it occurs. Machine learning predictive modeling offers a proactive approach by forecasting patient flow metrics, such as waiting count, to improve resource planning and hospital efficiency. Objective: This study develops machine learning models to predict ED waiting room occupancy at two time scales. The hourly model forecasts the waiting count six hours ahead (e.g., a 1 PM prediction for 7 PM), while the daily model estimates the average waiting count for the next 24 hours (e.g., a 5 PM prediction for the following day's average). These tools support staffing decisions and enable earlier interventions to reduce overcrowding. Methods: Data from a partner hospital's ED in the southeastern United States were used, integrating internal metrics and external features. Eleven machine learning algorithms, including traditional and deep learning models, were trained and evaluated. Feature combinations were optimized, and performance was assessed across varying patient volumes and hours. Results: TSiTPlus achieved the best hourly prediction (MAE: 4.19, MSE: 29.32). The mean hourly waiting count was 18.11, with a standard deviation of 9.77. Accuracy varied by hour, with MAEs ranging from 2.45 (11 PM) to 5.45 (8 PM). Extreme case analysis at one, two, and three standard deviations above the mean showed MAEs of 6.16, 10.16, and 15.59, respectively. For daily predictions, XCMPlus performed best (MAE: 2.00, MSE: 6.64), with a daily mean of 18.11 and standard deviation of 4.51. Conclusions: These models accurately forecast ED waiting room occupancy and support proactive resource allocation. Their implementation has the potential to improve patient flow and reduce overcrowding in emergency care settings.
Machine Learning Applications in Studying Mental Health Among Immigrants and Racial and Ethnic Minorities: A Systematic Review
Apr 18, 2023Background: The use of machine learning (ML) in mental health (MH) research is increasing, especially as new, more complex data types become available to analyze. By systematically examining the published literature, this review aims to uncover potential gaps in the current use of ML to study MH in vulnerable populations of immigrants, refugees, migrants, and racial and ethnic minorities. Methods: In this systematic review, we queried Google Scholar for ML-related terms, MH-related terms, and a population of a focus search term strung together with Boolean operators. Backward reference searching was also conducted. Included peer-reviewed studies reported using a method or application of ML in an MH context and focused on the populations of interest. We did not have date cutoffs. Publications were excluded if they were narrative or did not exclusively focus on a minority population from the respective country. Data including study context, the focus of mental healthcare, sample, data type, type of ML algorithm used, and algorithm performance was extracted from each. Results: Our search strategies resulted in 67,410 listed articles from Google Scholar. Ultimately, 12 were included. All the articles were published within the last 6 years, and half of them studied populations within the US. Most reviewed studies used supervised learning to explain or predict MH outcomes. Some publications used up to 16 models to determine the best predictive power. Almost half of the included publications did not discuss their cross-validation method. Conclusions: The included studies provide proof-of-concept for the potential use of ML algorithms to address MH concerns in these special populations, few as they may be. Our systematic review finds that the clinical application of these models for classifying and predicting MH disorders is still under development.
An Adaptive Simulated Annealing-Based Machine Learning Approach for Developing an E-Triage Tool for Hospital Emergency Operations
Dec 22, 2022Patient triage at emergency departments (EDs) is necessary to prioritize care for patients with critical and time-sensitive conditions. Different tools are used for patient triage and one of the most common ones is the emergency severity index (ESI), which has a scale of five levels, where level 1 is the most urgent and level 5 is the least urgent. This paper proposes a framework for utilizing machine learning to develop an e-triage tool that can be used at EDs. A large retrospective dataset of ED patient visits is obtained from the electronic health record of a healthcare provider in the Midwest of the US for three years. However, the main challenge of using machine learning algorithms is that most of them have many parameters and without optimizing these parameters, developing a high-performance model is not possible. This paper proposes an approach to optimize the hyperparameters of machine learning. The metaheuristic optimization algorithms simulated annealing (SA) and adaptive simulated annealing (ASA) are proposed to optimize the parameters of extreme gradient boosting (XGB) and categorical boosting (CaB). The newly proposed algorithms are SA-XGB, ASA-XGB, SA-CaB, ASA-CaB. Grid search (GS), which is a traditional approach used for machine learning fine-tunning is also used to fine-tune the parameters of XGB and CaB, which are named GS-XGB and GS-CaB. The six algorithms are trained and tested using eight data groups obtained from the feature selection phase. The results show ASA-CaB outperformed all the proposed algorithms with accuracy, precision, recall, and f1 of 83.3%, 83.2%, 83.3%, 83.2%, respectively.
A Study of Left Before Treatment Complete Emergency Department Patients: An Optimized Explanatory Machine Learning Framework
Dec 22, 2022The issue of left before treatment complete (LBTC) patients is common in emergency departments (EDs). This issue represents a medico-legal risk and may cause a revenue loss. Thus, understanding the factors that cause patients to leave before treatment is complete is vital to mitigate and potentially eliminate these adverse effects. This paper proposes a framework for studying the factors that affect LBTC outcomes in EDs. The framework integrates machine learning, metaheuristic optimization, and model interpretation techniques. Metaheuristic optimization is used for hyperparameter optimization--one of the main challenges of machine learning model development. Three metaheuristic optimization algorithms are employed for optimizing the parameters of extreme gradient boosting (XGB), which are simulated annealing (SA), adaptive simulated annealing (ASA), and adaptive tabu simulated annealing (ATSA). The optimized XGB models are used to predict the LBTC outcomes for the patients under treatment in ED. The designed algorithms are trained and tested using four data groups resulting from the feature selection phase. The model with the best predictive performance is interpreted using SHaply Additive exPlanations (SHAP) method. The findings show that ATSA-XGB outperformed other mode configurations with an accuracy, area under the curve (AUC), sensitivity, specificity, and F1-score of 86.61%, 87.50%, 85.71%, 87.51%, and 86.60%, respectively. The degree and the direction of effects of each feature were determined and explained using the SHAP method.
An Integrated Optimization and Machine Learning Models to Predict the Admission Status of Emergency Patients
Feb 18, 2022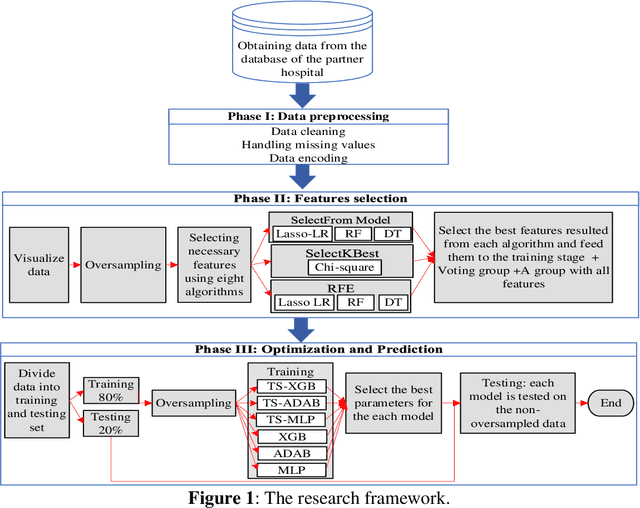

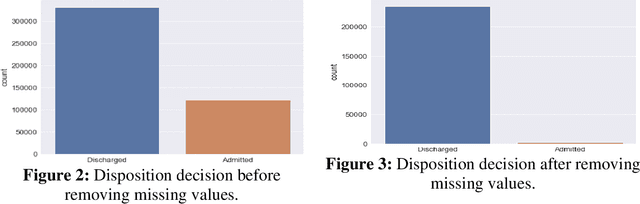
This work proposes a framework for optimizing machine learning algorithms. The practicality of the framework is illustrated using an important case study from the healthcare domain, which is predicting the admission status of emergency department (ED) patients (e.g., admitted vs. discharged) using patient data at the time of triage. The proposed framework can mitigate the crowding problem by proactively planning the patient boarding process. A large retrospective dataset of patient records is obtained from the electronic health record database of all ED visits over three years from three major locations of a healthcare provider in the Midwest of the US. Three machine learning algorithms are proposed: T-XGB, T-ADAB, and T-MLP. T-XGB integrates extreme gradient boosting (XGB) and Tabu Search (TS), T-ADAB integrates Adaboost and TS, and T-MLP integrates multi-layer perceptron (MLP) and TS. The proposed algorithms are compared with the traditional algorithms: XGB, ADAB, and MLP, in which their parameters are tunned using grid search. The three proposed algorithms and the original ones are trained and tested using nine data groups that are obtained from different feature selection methods. In other words, 54 models are developed. Performance was evaluated using five measures: Area under the curve (AUC), sensitivity, specificity, F1, and accuracy. The results show that the newly proposed algorithms resulted in high AUC and outperformed the traditional algorithms. The T-ADAB performs the best among the newly developed algorithms. The AUC, sensitivity, specificity, F1, and accuracy of the best model are 95.4%, 99.3%, 91.4%, 95.2%, 97.2%, respectively.