 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging large language models and traditional machine learning ensembles for ADHD detection from narrative transcripts
May 27, 2025Despite rapid advances in large language models (LLMs), their integration with traditional supervised machine learning (ML) techniques that have proven applicability to medical data remains underexplored. This is particularly true for psychiatric applications, where narrative data often exhibit nuanced linguistic and contextual complexity, and can benefit from the combination of multiple models with differing characteristics. In this study, we introduce an ensemble framework for automatically classifying Attention-Deficit/Hyperactivity Disorder (ADHD) diagnosis (binary) using narrative transcripts. Our approach integrates three complementary models: LLaMA3, an open-source LLM that captures long-range semantic structure; RoBERTa, a pre-trained transformer model fine-tuned on labeled clinical narratives; and a Support Vector Machine (SVM) classifier trained using TF-IDF-based lexical features. These models are aggregated through a majority voting mechanism to enhance predictive robustness. The dataset includes 441 instances, including 352 for training and 89 for validation. Empirical results show that the ensemble outperforms individual models, achieving an F$_1$ score of 0.71 (95\% CI: [0.60-0.80]). Compared to the best-performing individual model (SVM), the ensemble improved recall while maintaining competitive precision. This indicates the strong sensitivity of the ensemble in identifying ADHD-related linguistic cues. These findings demonstrate the promise of hybrid architectures that leverage the semantic richness of LLMs alongside the interpretability and pattern recognition capabilities of traditional supervised ML, offering a new direction for robust and generalizable psychiatric text classification.
LMME3DHF: Benchmarking and Evaluating Multimodal 3D Human Face Generation with LMMs
May 05, 2025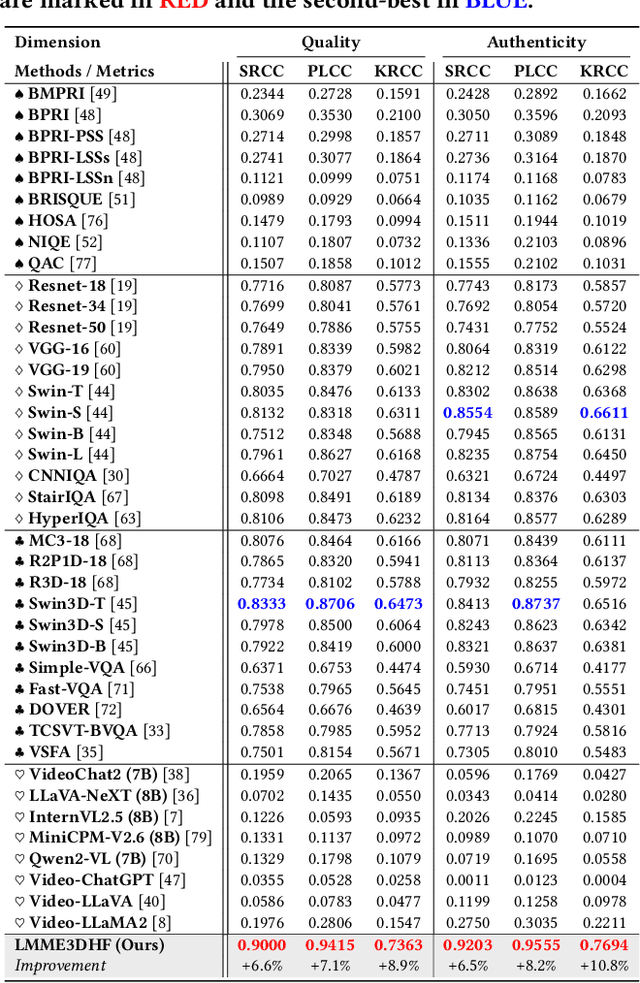
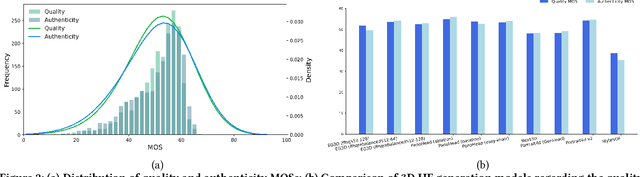

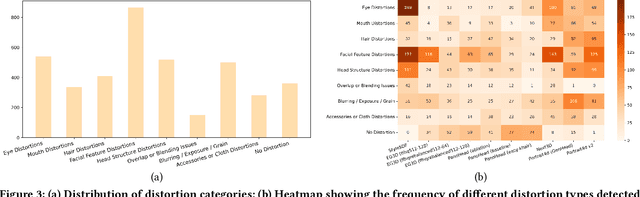
The rapid advancement in generative artificial intelligence have enabled the creation of 3D human faces (HFs) for applications including media production, virtual reality, security, healthcare, and game development, etc. However, assessing the quality and realism of these AI-generated 3D human faces remains a significant challenge due to the subjective nature of human perception and innate perceptual sensitivity to facial features. To this end, we conduct a comprehensive study on the quality assessment of AI-generated 3D human faces. We first introduce Gen3DHF, a large-scale benchmark comprising 2,000 videos of AI-Generated 3D Human Faces along with 4,000 Mean Opinion Scores (MOS) collected across two dimensions, i.e., quality and authenticity, 2,000 distortion-aware saliency maps and distortion descriptions. Based on Gen3DHF, we propose LMME3DHF, a Large Multimodal Model (LMM)-based metric for Evaluating 3DHF capable of quality and authenticity score prediction, distortion-aware visual question answering, and distortion-aware saliency prediction. Experimental results show that LMME3DHF achieves state-of-the-art performance, surpassing existing methods in both accurately predicting quality scores for AI-generated 3D human faces and effectively identifying distortion-aware salient regions and distortion types, while maintaining strong alignment with human perceptual judgments. Both the Gen3DHF database and the LMME3DHF will be released upon the publication.
LMM4Gen3DHF: Benchmarking and Evaluating Multimodal 3D Human Face Generation with LMMs
Apr 29, 2025The rapid advancement in generative artificial intelligence have enabled the creation of 3D human faces (HFs) for applications including media production, virtual reality, security, healthcare, and game development, etc. However, assessing the quality and realism of these AI-generated 3D human faces remains a significant challenge due to the subjective nature of human perception and innate perceptual sensitivity to facial features. To this end, we conduct a comprehensive study on the quality assessment of AI-generated 3D human faces. We first introduce Gen3DHF, a large-scale benchmark comprising 2,000 videos of AI-Generated 3D Human Faces along with 4,000 Mean Opinion Scores (MOS) collected across two dimensions, i.e., quality and authenticity, 2,000 distortion-aware saliency maps and distortion descriptions. Based on Gen3DHF, we propose LMME3DHF, a Large Multimodal Model (LMM)-based metric for Evaluating 3DHF capable of quality and authenticity score prediction, distortion-aware visual question answering, and distortion-aware saliency prediction. Experimental results show that LMME3DHF achieves state-of-the-art performance, surpassing existing methods in both accurately predicting quality scores for AI-generated 3D human faces and effectively identifying distortion-aware salient regions and distortion types, while maintaining strong alignment with human perceptual judgments. Both the Gen3DHF database and the LMME3DHF will be released upon the publication.
Exploring Foundation Models in Remote Sensing Image Change Detection: A Comprehensive Survey
Oct 10, 2024Change detection, as an important and widely applied technique in the field of remote sensing, aims to analyze changes in surface areas over time and has broad applications in areas such as environmental monitoring, urban development, and land use analysis.In recent years, deep learning, especially the development of foundation models, has provided more powerful solutions for feature extraction and data fusion, effectively addressing these complexities. This paper systematically reviews the latest advancements in the field of change detection, with a focus on the application of foundation models in remote sensing tasks.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024
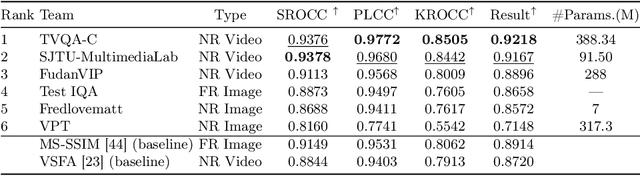
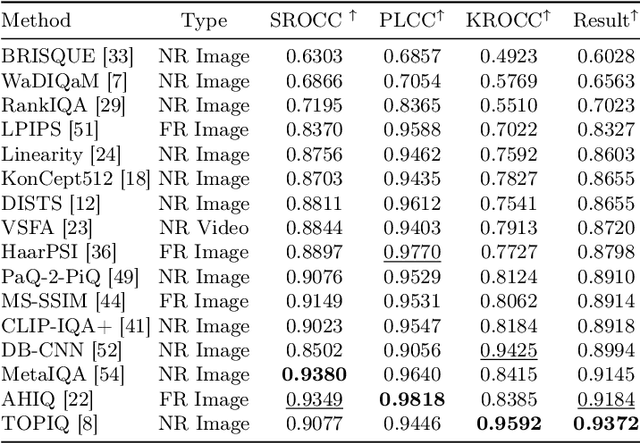
Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
How Does Audio Influence Visual Attention in Omnidirectional Videos? Database and Model
Aug 10, 2024



Understanding and predicting viewer attention in omnidirectional videos (ODVs) is crucial for enhancing user engagement in virtual and augmented reality applications. Although both audio and visual modalities are essential for saliency prediction in ODVs, the joint exploitation of these two modalities has been limited, primarily due to the absence of large-scale audio-visual saliency databases and comprehensive analyses. This paper comprehensively investigates audio-visual attention in ODVs from both subjective and objective perspectives. Specifically, we first introduce a new audio-visual saliency database for omnidirectional videos, termed AVS-ODV database, containing 162 ODVs and corresponding eye movement data collected from 60 subjects under three audio modes including mute, mono, and ambisonics. Based on the constructed AVS-ODV database, we perform an in-depth analysis of how audio influences visual attention in ODVs. To advance the research on audio-visual saliency prediction for ODVs, we further establish a new benchmark based on the AVS-ODV database by testing numerous state-of-the-art saliency models, including visual-only models and audio-visual models. In addition, given the limitations of current models, we propose an innovative omnidirectional audio-visual saliency prediction network (OmniAVS), which is built based on the U-Net architecture, and hierarchically fuses audio and visual features from the multimodal aligned embedding space. Extensive experimental results demonstrate that the proposed OmniAVS model outperforms other state-of-the-art models on both ODV AVS prediction and traditional AVS predcition tasks. The AVS-ODV database and OmniAVS model will be released to facilitate future research.
Audio-visual Saliency for Omnidirectional Videos
Nov 09, 2023Visual saliency prediction for omnidirectional videos (ODVs) has shown great significance and necessity for omnidirectional videos to help ODV coding, ODV transmission, ODV rendering, etc.. However, most studies only consider visual information for ODV saliency prediction while audio is rarely considered despite its significant influence on the viewing behavior of ODV. This is mainly due to the lack of large-scale audio-visual ODV datasets and corresponding analysis. Thus, in this paper, we first establish the largest audio-visual saliency dataset for omnidirectional videos (AVS-ODV), which comprises the omnidirectional videos, audios, and corresponding captured eye-tracking data for three video sound modalities including mute, mono, and ambisonics. Then we analyze the visual attention behavior of the observers under various omnidirectional audio modalities and visual scenes based on the AVS-ODV dataset. Furthermore, we compare the performance of several state-of-the-art saliency prediction models on the AVS-ODV dataset and construct a new benchmark. Our AVS-ODV datasets and the benchmark will be released to facilitate future research.
Perceptual Quality Assessment of Omnidirectional Audio-visual Signals
Jul 20, 2023Omnidirectional videos (ODVs) play an increasingly important role in the application fields of medical, education, advertising, tourism, etc. Assessing the quality of ODVs is significant for service-providers to improve the user's Quality of Experience (QoE). However, most existing quality assessment studies for ODVs only focus on the visual distortions of videos, while ignoring that the overall QoE also depends on the accompanying audio signals. In this paper, we first establish a large-scale audio-visual quality assessment dataset for omnidirectional videos, which includes 375 distorted omnidirectional audio-visual (A/V) sequences generated from 15 high-quality pristine omnidirectional A/V contents, and the corresponding perceptual audio-visual quality scores. Then, we design three baseline methods for full-reference omnidirectional audio-visual quality assessment (OAVQA), which combine existing state-of-the-art single-mode audio and video QA models via multimodal fusion strategies. We validate the effectiveness of the A/V multimodal fusion method for OAVQA on our dataset, which provides a new benchmark for omnidirectional QoE evaluation. Our dataset is available at https://github.com/iamazxl/OAVQA.