 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEmo-Logic: A Unified Dataset and Multi-Stage Framework for Comprehensive Image-Evoked Emotion Assessment
Feb 01, 2026Understanding the multi-dimensional attributes and intensity nuances of image-evoked emotions is pivotal for advancing machine empathy and empowering diverse human-computer interaction applications. However, existing models are still limited to coarse-grained emotion perception or deficient reasoning capabilities. To bridge this gap, we introduce EEmoDB, the largest image-evoked emotion understanding dataset to date. It features $5$ analysis dimensions spanning $5$ distinct task categories, facilitating comprehensive interpretation. Specifically, we compile $1.2M$ question-answering (QA) pairs (EEmoDB-QA) from $125k$ images via automated generation, alongside a $36k$ dataset (EEmoDB-Assess) curated from $25k$ images for fine-grained assessment. Furthermore, we propose EEmo-Logic, an all-in-one multimodal large language model (MLLM) developed via instruction fine-tuning and task-customized group relative preference optimization (GRPO) with novel reward design. Extensive experiments demonstrate that EEmo-Logic achieves robust performance in in-domain and cross-domain datasets, excelling in emotion QA and fine-grained assessment. The code is available at https://anonymous.4open.science/r/EEmoLogic.
VideoAesBench: Benchmarking the Video Aesthetics Perception Capabilities of Large Multimodal Models
Jan 29, 2026Large multimodal models (LMMs) have demonstrated outstanding capabilities in various visual perception tasks, which has in turn made the evaluation of LMMs significant. However, the capability of video aesthetic quality assessment, which is a fundamental ability for human, remains underexplored for LMMs. To address this, we introduce VideoAesBench, a comprehensive benchmark for evaluating LMMs' understanding of video aesthetic quality. VideoAesBench has several significant characteristics: (1) Diverse content including 1,804 videos from multiple video sources including user-generated (UGC), AI-generated (AIGC), compressed, robotic-generated (RGC), and game videos. (2) Multiple question formats containing traditional single-choice questions, multi-choice questions, True or False questions, and a novel open-ended questions for video aesthetics description. (3) Holistic video aesthetics dimensions including visual form related questions from 5 aspects, visual style related questions from 4 aspects, and visual affectiveness questions from 3 aspects. Based on VideoAesBench, we benchmark 23 open-source and commercial large multimodal models. Our findings show that current LMMs only contain basic video aesthetics perception ability, their performance remains incomplete and imprecise. We hope our VideoAesBench can be served as a strong testbed and offer insights for explainable video aesthetics assessment.
Q-Bench-Portrait: Benchmarking Multimodal Large Language Models on Portrait Image Quality Perception
Jan 26, 2026Recent advances in multimodal large language models (MLLMs) have demonstrated impressive performance on existing low-level vision benchmarks, which primarily focus on generic images. However, their capabilities to perceive and assess portrait images, a domain characterized by distinct structural and perceptual properties, remain largely underexplored. To this end, we introduce Q-Bench-Portrait, the first holistic benchmark specifically designed for portrait image quality perception, comprising 2,765 image-question-answer triplets and featuring (1) diverse portrait image sources, including natural, synthetic distortion, AI-generated, artistic, and computer graphics images; (2) comprehensive quality dimensions, covering technical distortions, AIGC-specific distortions, and aesthetics; and (3) a range of question formats, including single-choice, multiple-choice, true/false, and open-ended questions, at both global and local levels. Based on Q-Bench-Portrait, we evaluate 20 open-source and 5 closed-source MLLMs, revealing that although current models demonstrate some competence in portrait image perception, their performance remains limited and imprecise, with a clear gap relative to human judgments. We hope that the proposed benchmark will foster further research into enhancing the portrait image perception capabilities of both general-purpose and domain-specific MLLMs.
Fine-Grained Human Pose Editing Assessment via Layer-Selective MLLMs
Jan 15, 2026Text-guided human pose editing has gained significant traction in AIGC applications. However,it remains plagued by structural anomalies and generative artifacts. Existing evaluation metrics often isolate authenticity detection from quality assessment, failing to provide fine-grained insights into pose-specific inconsistencies. To address these limitations, we introduce HPE-Bench, a specialized benchmark comprising 1,700 standardized samples from 17 state-of-the-art editing models, offering both authenticity labels and multi-dimensional quality scores. Furthermore, we propose a unified framework based on layer-selective multimodal large language models (MLLMs). By employing contrastive LoRA tuning and a novel layer sensitivity analysis (LSA) mechanism, we identify the optimal feature layer for pose evaluation. Our framework achieves superior performance in both authenticity detection and multi-dimensional quality regression, effectively bridging the gap between forensic detection and quality assessment.
Enhancing Image Quality Assessment Ability of LMMs via Retrieval-Augmented Generation
Jan 13, 2026Large Multimodal Models (LMMs) have recently shown remarkable promise in low-level visual perception tasks, particularly in Image Quality Assessment (IQA), demonstrating strong zero-shot capability. However, achieving state-of-the-art performance often requires computationally expensive fine-tuning methods, which aim to align the distribution of quality-related token in output with image quality levels. Inspired by recent training-free works for LMM, we introduce IQARAG, a novel, training-free framework that enhances LMMs' IQA ability. IQARAG leverages Retrieval-Augmented Generation (RAG) to retrieve some semantically similar but quality-variant reference images with corresponding Mean Opinion Scores (MOSs) for input image. These retrieved images and input image are integrated into a specific prompt. Retrieved images provide the LMM with a visual perception anchor for IQA task. IQARAG contains three key phases: Retrieval Feature Extraction, Image Retrieval, and Integration & Quality Score Generation. Extensive experiments across multiple diverse IQA datasets, including KADID, KonIQ, LIVE Challenge, and SPAQ, demonstrate that the proposed IQARAG effectively boosts the IQA performance of LMMs, offering a resource-efficient alternative to fine-tuning for quality assessment.
Agentic Retoucher for Text-To-Image Generation
Jan 08, 2026Text-to-image (T2I) diffusion models such as SDXL and FLUX have achieved impressive photorealism, yet small-scale distortions remain pervasive in limbs, face, text and so on. Existing refinement approaches either perform costly iterative re-generation or rely on vision-language models (VLMs) with weak spatial grounding, leading to semantic drift and unreliable local edits. To close this gap, we propose Agentic Retoucher, a hierarchical decision-driven framework that reformulates post-generation correction as a human-like perception-reasoning-action loop. Specifically, we design (1) a perception agent that learns contextual saliency for fine-grained distortion localization under text-image consistency cues, (2) a reasoning agent that performs human-aligned inferential diagnosis via progressive preference alignment, and (3) an action agent that adaptively plans localized inpainting guided by user preference. This design integrates perceptual evidence, linguistic reasoning, and controllable correction into a unified, self-corrective decision process. To enable fine-grained supervision and quantitative evaluation, we further construct GenBlemish-27K, a dataset of 6K T2I images with 27K annotated artifact regions across 12 categories. Extensive experiments demonstrate that Agentic Retoucher consistently outperforms state-of-the-art methods in perceptual quality, distortion localization and human preference alignment, establishing a new paradigm for self-corrective and perceptually reliable T2I generation.
VTONQA: A Multi-Dimensional Quality Assessment Dataset for Virtual Try-on
Jan 06, 2026With the rapid development of e-commerce and digital fashion, image-based virtual try-on (VTON) has attracted increasing attention. However, existing VTON models often suffer from artifacts such as garment distortion and body inconsistency, highlighting the need for reliable quality evaluation of VTON-generated images. To this end, we construct VTONQA, the first multi-dimensional quality assessment dataset specifically designed for VTON, which contains 8,132 images generated by 11 representative VTON models, along with 24,396 mean opinion scores (MOSs) across three evaluation dimensions (i.e., clothing fit, body compatibility, and overall quality). Based on VTONQA, we benchmark both VTON models and a diverse set of image quality assessment (IQA) metrics, revealing the limitations of existing methods and highlighting the value of the proposed dataset. We believe that the VTONQA dataset and corresponding benchmarks will provide a solid foundation for perceptually aligned evaluation, benefiting both the development of quality assessment methods and the advancement of VTON models.
Robust Mesh Saliency GT Acquisition in VR via View Cone Sampling and Geometric Smoothing
Jan 06, 2026Reliable 3D mesh saliency ground truth (GT) is essential for human-centric visual modeling in virtual reality (VR). However, current 3D mesh saliency GT acquisition methods are generally consistent with 2D image methods, ignoring the differences between 3D geometry topology and 2D image array. Current VR eye-tracking pipelines rely on single ray sampling and Euclidean smoothing, triggering texture attention and signal leakage across gaps. This paper proposes a robust framework to address these limitations. We first introduce a view cone sampling (VCS) strategy, which simulates the human foveal receptive field via Gaussian-distributed ray bundles to improve sampling robustness for complex topologies. Furthermore, a hybrid Manifold-Euclidean constrained diffusion (HCD) algorithm is developed, fusing manifold geodesic constraints with Euclidean scales to ensure topologically-consistent saliency propagation. By mitigating "topological short-circuits" and aliasing, our framework provides a high-fidelity 3D attention acquisition paradigm that aligns with natural human perception, offering a more accurate and robust baseline for 3D mesh saliency research.
Generative Human-Object Interaction Detection via Differentiable Cognitive Steering of Multi-modal LLMs
Dec 19, 2025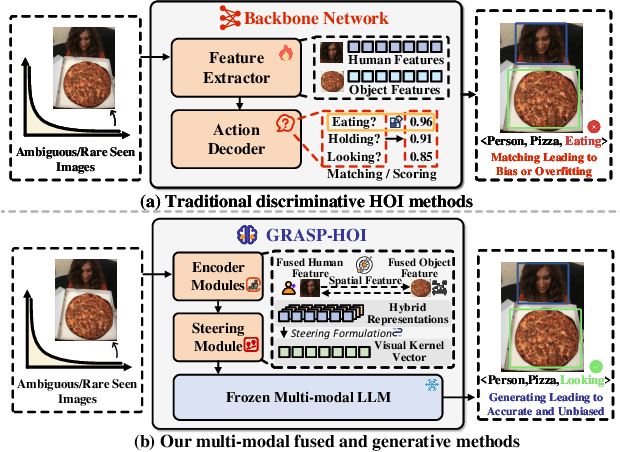
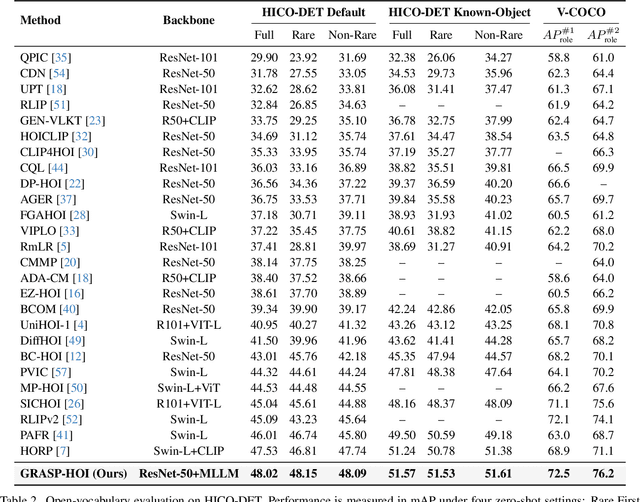
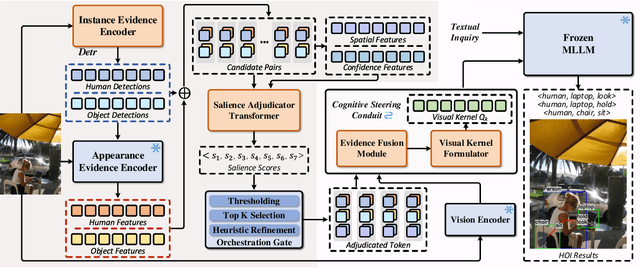
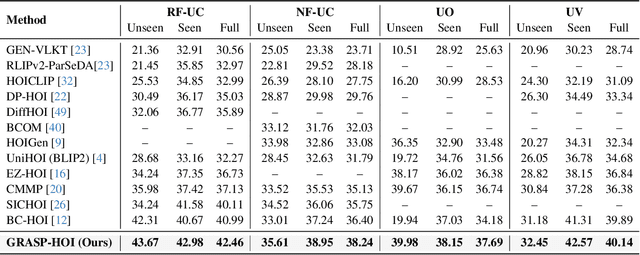
Human-object interaction (HOI) detection aims to localize human-object pairs and the interactions between them. Existing methods operate under a closed-world assumption, treating the task as a classification problem over a small, predefined verb set, which struggles to generalize to the long-tail of unseen or ambiguous interactions in the wild. While recent multi-modal large language models (MLLMs) possess the rich world knowledge required for open-vocabulary understanding, they remain decoupled from existing HOI detectors since fine-tuning them is computationally prohibitive. To address these constraints, we propose \GRASP-HO}, a novel Generative Reasoning And Steerable Perception framework that reformulates HOI detection from the closed-set classification task to the open-vocabulary generation problem. To bridge the vision and cognitive, we first extract hybrid interaction representations, then design a lightweight learnable cognitive steering conduit (CSC) module to inject the fine-grained visual evidence into a frozen MLLM for effective reasoning. To address the supervision mismatch between classification-based HOI datasets and open-vocabulary generative models, we introduce a hybrid guidance strategy that coupling the language modeling loss and auxiliary classification loss, enabling discriminative grounding without sacrificing generative flexibility. Experiments demonstrate state-of-the-art closed-set performance and strong zero-shot generalization, achieving a unified paradigm that seamlessly bridges discriminative perception and generative reasoning for open-world HOI detection.
ManipShield: A Unified Framework for Image Manipulation Detection, Localization and Explanation
Nov 18, 2025
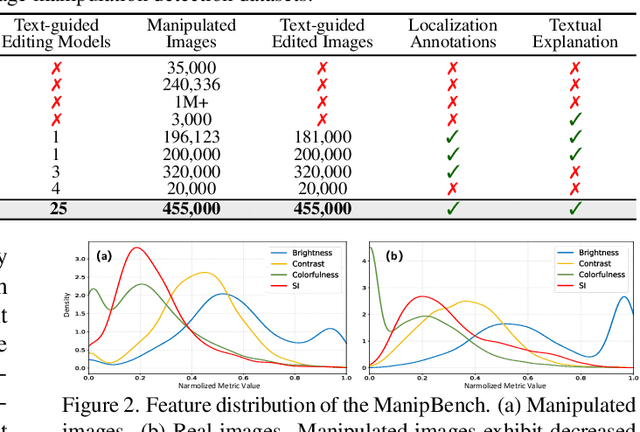

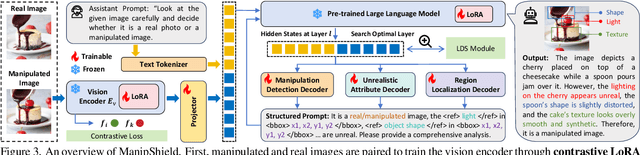
With the rapid advancement of generative models, powerful image editing methods now enable diverse and highly realistic image manipulations that far surpass traditional deepfake techniques, posing new challenges for manipulation detection. Existing image manipulation detection and localization (IMDL) benchmarks suffer from limited content diversity, narrow generative-model coverage, and insufficient interpretability, which hinders the generalization and explanation capabilities of current manipulation detection methods. To address these limitations, we introduce \textbf{ManipBench}, a large-scale benchmark for image manipulation detection and localization focusing on AI-edited images. ManipBench contains over 450K manipulated images produced by 25 state-of-the-art image editing models across 12 manipulation categories, among which 100K images are further annotated with bounding boxes, judgment cues, and textual explanations to support interpretable detection. Building upon ManipBench, we propose \textbf{ManipShield}, an all-in-one model based on a Multimodal Large Language Model (MLLM) that leverages contrastive LoRA fine-tuning and task-specific decoders to achieve unified image manipulation detection, localization, and explanation. Extensive experiments on ManipBench and several public datasets demonstrate that ManipShield achieves state-of-the-art performance and exhibits strong generality to unseen manipulation models. Both ManipBench and ManipShield will be released upon publication.