 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-of-Causal Evolution: Challenging Chain-of-Model for Reasoning
Jun 09, 2025In view of the problem that each subchain in the chain-of-model (CoM) relies only on the information of the previous subchain and may lose long-range dependencies due to the causal mask blocking the global context flow between multi-level subchains, this work proposes a graph of causal evolution (GoCE). Its core principle is to map the implicit token representation into a differentiable and sparse causal adjacency matrix, then permeate causal constraints through each layer of calculation using causal-masked attention and causal-MoE. By combining intervention consistency loss test and self-evolution gate, the dynamic balance between causal structure learning and adaptive updating of transformer architecture is realized. The researcher built experimental environments in sandboxes built with Claude Sonnet 4, o4-mini-high, and DeepSeek R1 respectively with the transformer variant architecture introduced in GoCE. It is evaluated on publicly available datasets including CLUTRR, CLADDER, EX-FEVER, and CausalQA and compared with the baseline LLMs. The finding proves that GoCE strengthens the transformer's ability to capture long-range causal dependencies, while the ability to self-evolve is improved. It not only surpasses the design of CoM in terms of design principles, but also provides experience for future research on causal learning and continuous adaptive improvement.
Towards Humanoid Robot Autonomy: A Dynamic Architecture Integrating Continuous thought Machines (CTM) and Model Context Protocol (MCP)
May 25, 2025To address the gaps between the static pre-set "thinking-planning-action" of humanoid robots in unfamiliar scenarios and the highly programmed "call tool-return result" due to the lack of autonomous coding capabilities, this work designs a dynamic architecture connecting continuous thought machines (CTM) and model context protocol (MCP). It proposes a theoretical parallel solution through tick-slab and uses rank compression to achieve parameter suppression to provide a solution for achieving autonomous actions due to autonomous coding. The researcher used a simulation-based experiment using OpenAI's o4-mini-high as a tool to build the experimental environment, and introduced the extended SayCan dataset to conduct nine epochs of experiments. The experimental results show that the CTM-MCP architecture is feasible and effective through the data results of seven metrics: task success rate (TSR), execution success rate (ESR), average episode length (AEL), ROSCOE, REVEAL, proficiency self-assessment (PSA), task effectiveness (TE). In practice, it provides a reference experience for exploring the autonomous dynamic coding of humanoid robots based on continuous thinking to achieve human-like autonomous actions.
Wormhole Memory: A Rubik's Cube for Cross-Dialogue Retrieval
Jan 24, 2025

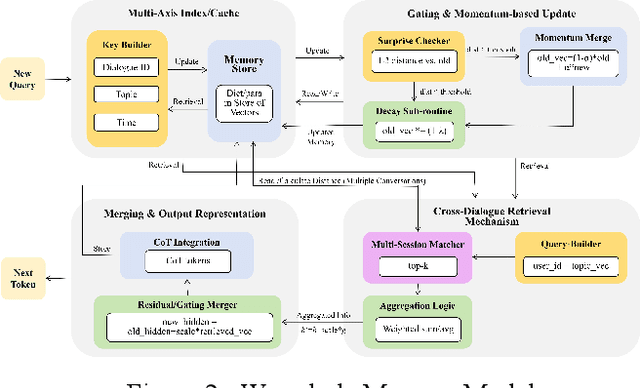

In view of the gap in the current large language model in sharing memory across dialogues, this research proposes a wormhole memory module (WMM) to realize memory as a Rubik's cube that can be arbitrarily retrieved between different dialogues. Through simulation experiments, the researcher built an experimental framework based on the Python environment and used setting memory barriers to simulate the current situation where memories between LLMs dialogues are difficult to share. The CoQA development data set was imported into the experiment, and the feasibility of its cross-dialogue memory retrieval function was verified for WMM's nonlinear indexing and dynamic retrieval, and a comparative analysis was conducted with the capabilities of Titans and MemGPT memory modules. Experimental results show that WMM demonstrated the ability to retrieve memory across dialogues and the stability of quantitative indicators in eight experiments. It contributes new technical approaches to the optimization of memory management of LLMs and provides experience for the practical application in the future.
Facial Attractiveness Prediction in Live Streaming: A New Benchmark and Multi-modal Method
Jan 05, 2025



Facial attractiveness prediction (FAP) has long been an important computer vision task, which could be widely applied in live streaming for facial retouching, content recommendation, etc. However, previous FAP datasets are either small, closed-source, or lack diversity. Moreover, the corresponding FAP models exhibit limited generalization and adaptation ability. To overcome these limitations, in this paper we present LiveBeauty, the first large-scale live-specific FAP dataset, in a more challenging application scenario, i.e., live streaming. 10,000 face images are collected from a live streaming platform directly, with 200,000 corresponding attractiveness annotations obtained from a well-devised subjective experiment, making LiveBeauty the largest open-access FAP dataset in the challenging live scenario. Furthermore, a multi-modal FAP method is proposed to measure the facial attractiveness in live streaming. Specifically, we first extract holistic facial prior knowledge and multi-modal aesthetic semantic features via a Personalized Attractiveness Prior Module (PAPM) and a Multi-modal Attractiveness Encoder Module (MAEM), respectively, then integrate the extracted features through a Cross-Modal Fusion Module (CMFM). Extensive experiments conducted on both LiveBeauty and other open-source FAP datasets demonstrate that our proposed method achieves state-of-the-art performance. Dataset will be available soon.
Multi-Scenario Reasoning: Unlocking Cognitive Autonomy in Humanoid Robots for Multimodal Understanding
Dec 29, 2024

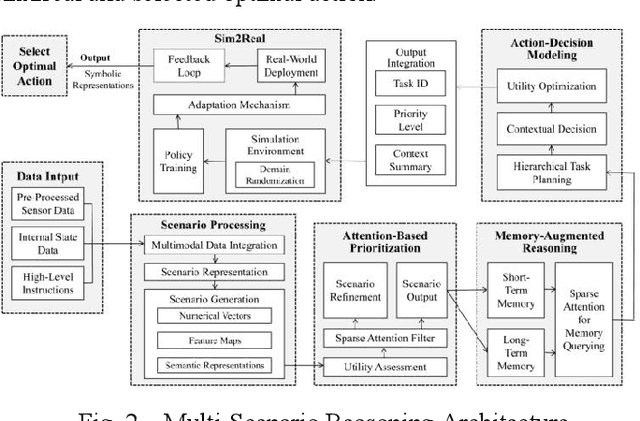

To improve the cognitive autonomy of humanoid robots, this research proposes a multi-scenario reasoning architecture to solve the technical shortcomings of multi-modal understanding in this field. It draws on simulation based experimental design that adopts multi-modal synthesis (visual, auditory, tactile) and builds a simulator "Maha" to perform the experiment. The findings demonstrate the feasibility of this architecture in multimodal data. It provides reference experience for the exploration of cross-modal interaction strategies for humanoid robots in dynamic environments.
"Moralized" Multi-Step Jailbreak Prompts: Black-Box Testing of Guardrails in Large Language Models for Verbal Attacks
Nov 23, 2024



As the application of large language models continues to expand in various fields, it poses higher challenges to the effectiveness of identifying harmful content generation and guardrail mechanisms. This research aims to evaluate the effectiveness of guardrails in the face of multi-step jailbreak prompt-generated verbal attacks, through black-box testing of seemingly ethical prompt simulations. The experimental subjects were selected GPT-4o, Grok-2 Beta, Llama 3.1 (405B), Gemini 1.5 and Claude 3.5 Sonnet. The researcher used the same multi-step prompt to simulate moral attacks by designing a scenario of "enterprise middle managers competing for promotion" and observed the model's response at each step. During the experiment, the guardrails of the above model were all bypassed in this experiment and the content of verbal attacks was generated. The data results show that Claude 3.5 Sonnet performs better than other models in terms of its tendency to identify jailbreak prompts. The researcher hopes to use this to remind developers and future research that guardrails not only inappropriately play the role of content filters, but should also have a preventive function. In order to ensure the objectivity and generalizability of the experiment, the researcher has uploaded the experimental process, black box test code, and enhanced guardrail code to GitHub to promote cooperation in the development community: https://github.com/brucewang123456789/GeniusTrail.git.
Mitigating Sycophancy in Decoder-Only Transformer Architectures: Synthetic Data Intervention
Nov 15, 2024

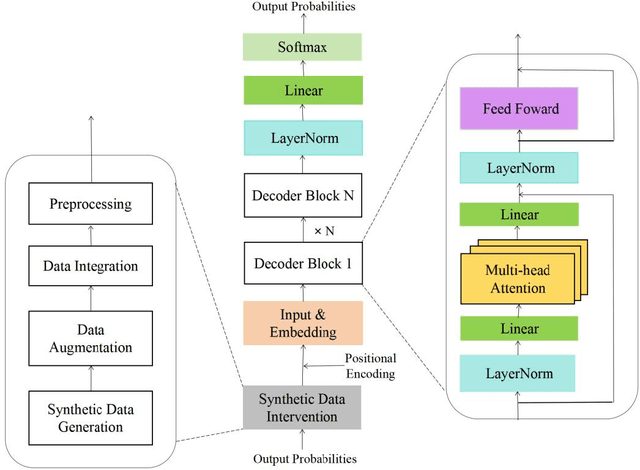

To address the sycophancy problem caused by reinforcement learning from human feedback in large language models, this research applies synthetic data intervention technology to the decoder-only transformer architecture. Based on the research gaps in the existing literature, the researcher designed an experimental process to reduce the tendency of models to cater by generating diversified data, and used GPT4o as an experimental tool for verification. The experiment used 100 true and false questions, and compared the performance of the model trained with synthetic data intervention and the original untrained model on multiple indicators. The results show that the SDI training model supports the technology in terms of accuracy rate and sycophancy rate and has significant effectiveness in reducing sycophancy phenomena. Notably, the data set, experimental process, code and data results have been uploaded to Github, the link is https://github.com/brucewang123456789/GeniusTrail.git.
Reducing Reasoning Costs -- The Path of Optimization for Chain of Thought via Sparse Attention Mechanism
Nov 14, 2024In order to address the chain of thought in the large language model inference cost surge, this research proposes to use a sparse attention mechanism that only focuses on a few relevant tokens. The researcher constructed a new attention mechanism and used GiantRabbit trained with custom GPTs as an experimental tool. The experiment tested and compared the reasoning time, correctness score and chain of thought length of this model and o1 Preview in solving the linear algebra test questions of MIT OpenCourseWare. The results show that GiantRabbit's reasoning time and chain of thought length are significantly lower than o1 Preview, confirming the feasibility of the sparse attention mechanism in reducing chain of thought reasoning. Detailed architectural details and experimental process have been uploaded to Github, the link is:https://github.com/brucewang123456789/GeniusTrail.git.
PyramidMamba: Rethinking Pyramid Feature Fusion with Selective Space State Model for Semantic Segmentation of Remote Sensing Imagery
Jun 16, 2024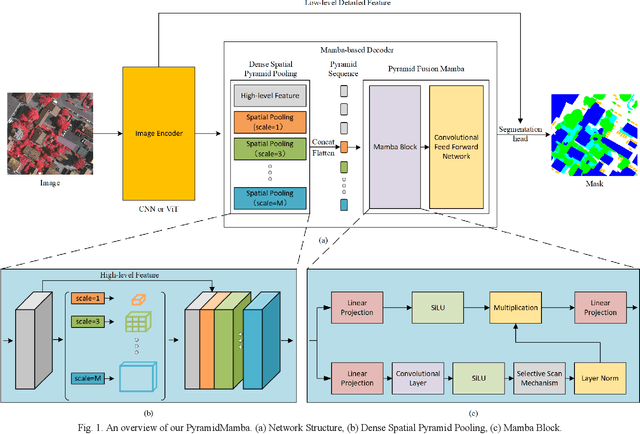
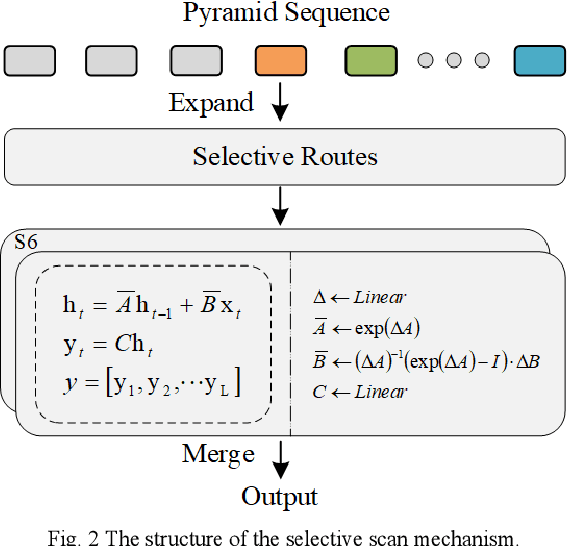
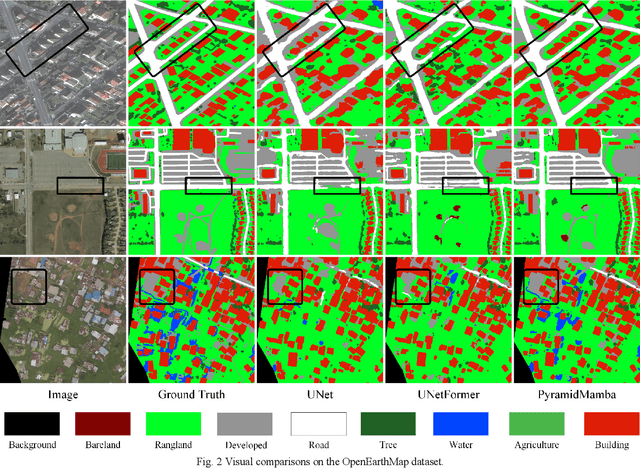
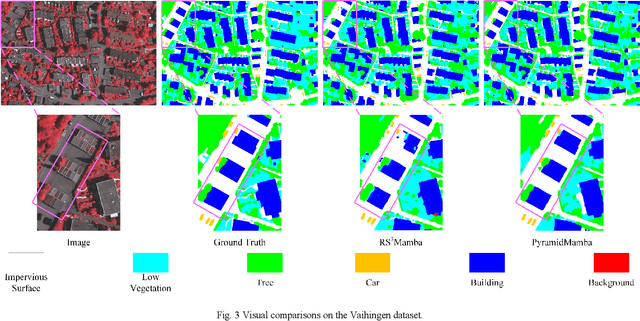
Semantic segmentation, as a basic tool for intelligent interpretation of remote sensing images, plays a vital role in many Earth Observation (EO) applications. Nowadays, accurate semantic segmentation of remote sensing images remains a challenge due to the complex spatial-temporal scenes and multi-scale geo-objects. Driven by the wave of deep learning (DL), CNN- and Transformer-based semantic segmentation methods have been explored widely, and these two architectures both revealed the importance of multi-scale feature representation for strengthening semantic information of geo-objects. However, the actual multi-scale feature fusion often comes with the semantic redundancy issue due to homogeneous semantic contents in pyramid features. To handle this issue, we propose a novel Mamba-based segmentation network, namely PyramidMamba. Specifically, we design a plug-and-play decoder, which develops a dense spatial pyramid pooling (DSPP) to encode rich multi-scale semantic features and a pyramid fusion Mamba (PFM) to reduce semantic redundancy in multi-scale feature fusion. Comprehensive ablation experiments illustrate the effectiveness and superiority of the proposed method in enhancing multi-scale feature representation as well as the great potential for real-time semantic segmentation. Moreover, our PyramidMamba yields state-of-the-art performance on three publicly available datasets, i.e. the OpenEarthMap (70.8% mIoU), ISPRS Vaihingen (84.8% mIoU) and Potsdam (88.0% mIoU) datasets. The code will be available at https://github.com/WangLibo1995/GeoSeg.
MetaSegNet: Metadata-collaborative Vision-Language Representation Learning for Semantic Segmentation of Remote Sensing Images
Dec 20, 2023Semantic segmentation of remote sensing images plays a vital role in a wide range of Earth Observation (EO) applications, such as land use land cover mapping, environment monitoring, and sustainable development. Driven by rapid developments in Artificial Intelligence (AI), deep learning (DL) has emerged as the mainstream tool for semantic segmentation and achieved many breakthroughs in the field of remote sensing. However, the existing DL-based methods mainly focus on unimodal visual data while ignoring the rich multimodal information involved in the real world, usually demonstrating weak reliability and generlization. Inspired by the success of Vision Transformers and large language models, we propose a novel metadata-collaborative multimodal segmentation network (MetaSegNet) that applies vision-language representation learning for semantic segmentation of remote sensing images. Unlike the common model structure that only uses unimodal visual data, we extract the key characteristic (i.e. the climate zone) from freely available remote sensing image metadata and transfer it into knowledge-based text prompts via the generic ChatGPT. Then, we construct an image encoder, a text encoder and a crossmodal attention fusion subnetwork to extract the image and text feature and apply image-text interaction. Benefiting from such a design, the proposed MetaSegNet demonstrates superior generalization and achieves competitive accuracy with state-of-the-art semantic segmentation methods on the large-scale OpenEarthMap dataset (68.6% mIoU) and Potsdam dataset (93.3% mean F1 score) as well as LoveDA dataset (52.2% mIoU).