 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSegNet: Metadata-collaborative Vision-Language Representation Learning for Semantic Segmentation of Remote Sensing Images
Dec 20, 2023Semantic segmentation of remote sensing images plays a vital role in a wide range of Earth Observation (EO) applications, such as land use land cover mapping, environment monitoring, and sustainable development. Driven by rapid developments in Artificial Intelligence (AI), deep learning (DL) has emerged as the mainstream tool for semantic segmentation and achieved many breakthroughs in the field of remote sensing. However, the existing DL-based methods mainly focus on unimodal visual data while ignoring the rich multimodal information involved in the real world, usually demonstrating weak reliability and generlization. Inspired by the success of Vision Transformers and large language models, we propose a novel metadata-collaborative multimodal segmentation network (MetaSegNet) that applies vision-language representation learning for semantic segmentation of remote sensing images. Unlike the common model structure that only uses unimodal visual data, we extract the key characteristic (i.e. the climate zone) from freely available remote sensing image metadata and transfer it into knowledge-based text prompts via the generic ChatGPT. Then, we construct an image encoder, a text encoder and a crossmodal attention fusion subnetwork to extract the image and text feature and apply image-text interaction. Benefiting from such a design, the proposed MetaSegNet demonstrates superior generalization and achieves competitive accuracy with state-of-the-art semantic segmentation methods on the large-scale OpenEarthMap dataset (68.6% mIoU) and Potsdam dataset (93.3% mean F1 score) as well as LoveDA dataset (52.2% mIoU).
Efficient Hybrid Transformer: Learning Global-local Context for Urban Scene Segmentation
Oct 13, 2021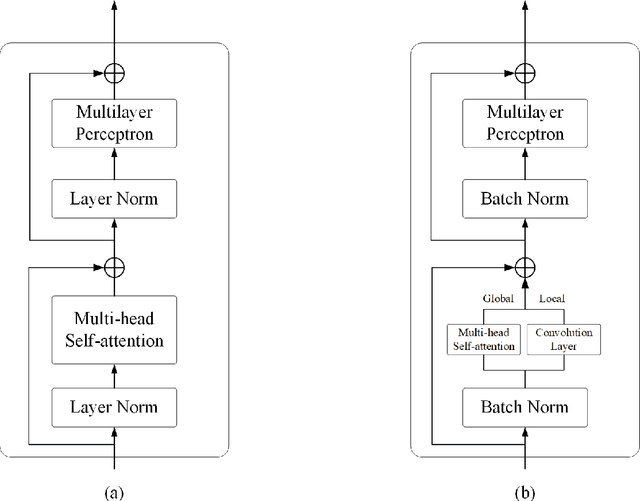

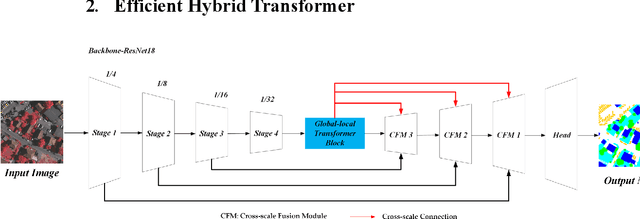
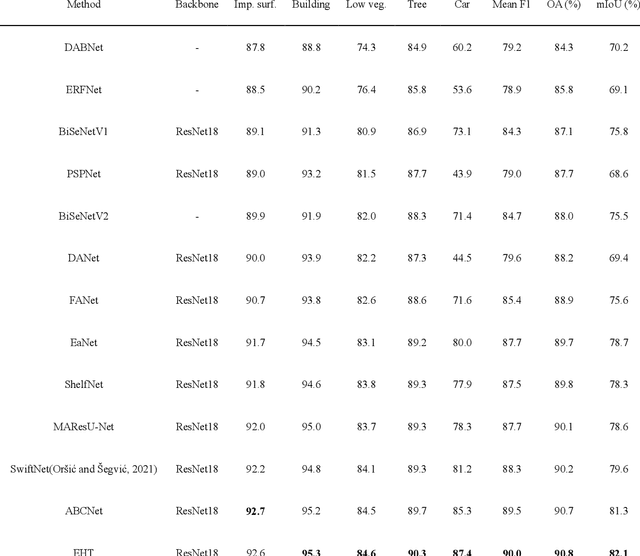
Semantic segmentation of fine-resolution urban scene images plays a vital role in extensive practical applications, such as land cover mapping, urban change detection, environmental protection and economic assessment. Driven by rapid developments in deep learning technologies, the convolutional neural network (CNN) has dominated the semantic segmentation task for many years. Convolutional neural networks adopt hierarchical feature representation, demonstrating strong local information extraction. However, the local property of the convolution layer limits the network from capturing global context that is crucial for precise segmentation. Recently, Transformer comprise a hot topic in the computer vision domain. Transformer demonstrates the great capability of global information modelling, boosting many vision tasks, such as image classification, object detection and especially semantic segmentation. In this paper, we propose an efficient hybrid Transformer (EHT) for real-time urban scene segmentation. The EHT adopts a hybrid structure with and CNN-based encoder and a transformer-based decoder, learning global-local context with lower computation. Extensive experiments demonstrate that our EHT has faster inference speed with competitive accuracy compared with state-of-the-art lightweight models. Specifically, the proposed EHT achieves a 66.9% mIoU on the UAVid test set and outperforms other benchmark networks significantly. The code will be available soon.
A Novel Transformer based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images
May 11, 2021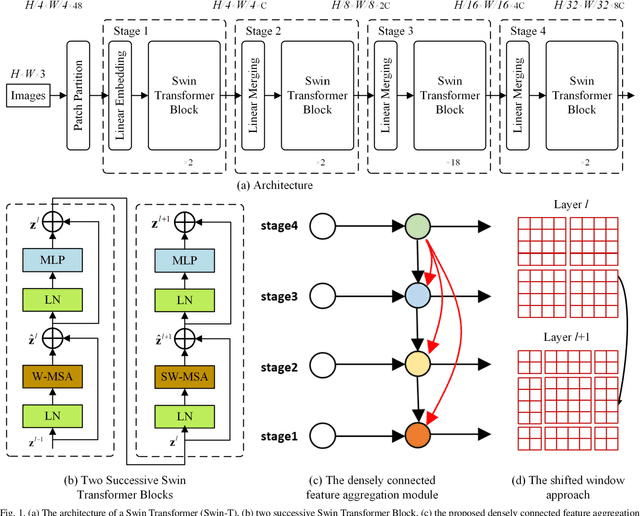
The fully-convolutional network (FCN) with an encoder-decoder architecture has been the standard paradigm for semantic segmentation. The encoder-decoder architecture utilizes an encoder to capture multi-level feature maps, which are incorporated into the final prediction by a decoder. As the context is crucial for precise segmentation, tremendous effort has been made to extract such information in an intelligent fashion, including employing dilated/atrous convolutions or inserting attention modules. However, these endeavours are all based on the FCN architecture with ResNet or other backbones, which cannot fully exploit the context from the theoretical concept. By contrast, we propose the Swin Transformer as the backbone to extract the context information and design a novel decoder of densely connected feature aggregation module (DCFAM) to restore the resolution and produce the segmentation map. The experimental results on two remotely sensed semantic segmentation datasets demonstrate the effectiveness of the proposed scheme.
SaNet: Scale-aware Neural Network for Semantic Labelling of Multiple Spatial Resolution Aerial Images
Apr 10, 2021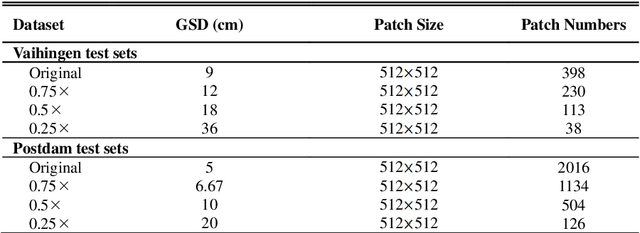


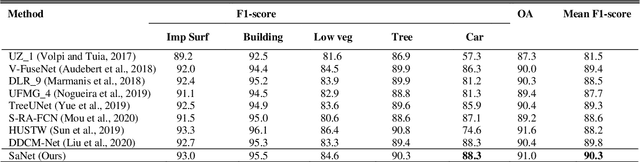
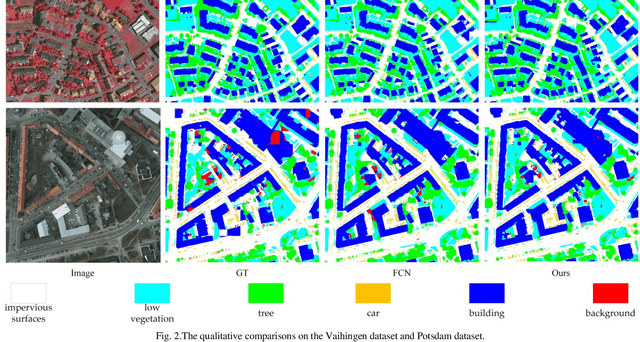
Assigning geospatial objects of aerial images with specific categories at the pixel level is a fundamental task in urban scene interpretation. Along with rapid developments in sensor technologies, aerial images can be captured at multiple spatial resolutions (MSR) with information content manifested at different scales. Extracting information from these MSR aerial images represents huge opportunities for enhanced feature representation and characterisation. However, MSR images suffer from two critical issues: 1) increased variation in the sizes of geospatial objects and 2) information and informative feature loss at coarse spatial resolutions. In this paper, we propose a novel scale-aware neural network (SaNet) for semantic labelling of MSR aerial images to address these two issues. SaNet deploys a densely connected feature network (DCFPN) module to capture high-quality multi-scale context, such as to address the scale variation issue and increase the quality of segmentation for both large and small objects simultaneously. A spatial feature recalibration (SFR) module is further incorporated into the network to learn complete semantic features with enhanced spatial relationships, where the effects of information and informative feature loss are addressed. The combination of DCFPN and SFR allows the proposed SaNet to learn scale-aware features from MSR aerial images. Extensive experiments undertaken on ISPRS semantic segmentation datasets demonstrated the outstanding accuracy of the proposed SaNet in cross-resolution segmentation, with an average OA of 83.4% on the Vaihingen dataset and an average F1 score of 80.4% on the Potsdam dataset, outperforming state-of-the-art deep learning approaches, including FPN (80.2% and 76.6%), PSPNet (79.8% and 76.2%) and Deeplabv3+ (80.8% and 76.1%) as well as DDCM-Net (81.7% and 77.6%) and EaNet (81.5% and 78.3%).