 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Transformer based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images
Paper and Code
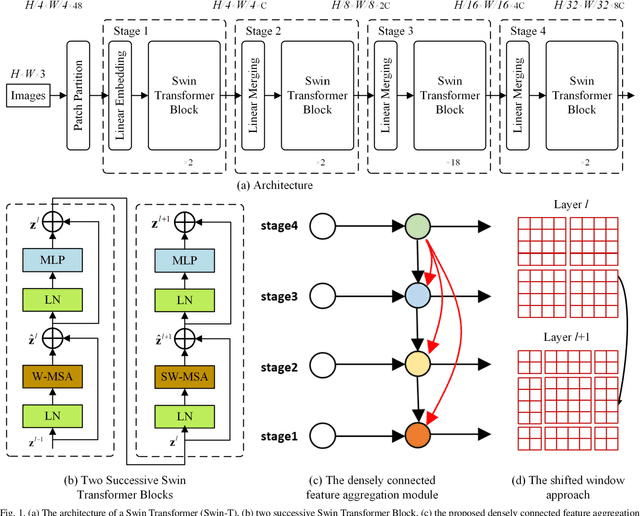
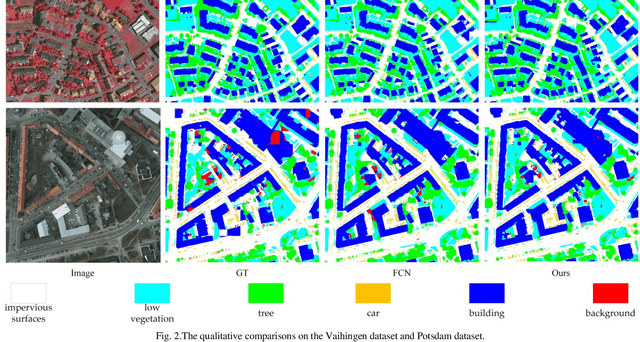
The fully-convolutional network (FCN) with an encoder-decoder architecture has been the standard paradigm for semantic segmentation. The encoder-decoder architecture utilizes an encoder to capture multi-level feature maps, which are incorporated into the final prediction by a decoder. As the context is crucial for precise segmentation, tremendous effort has been made to extract such information in an intelligent fashion, including employing dilated/atrous convolutions or inserting attention modules. However, these endeavours are all based on the FCN architecture with ResNet or other backbones, which cannot fully exploit the context from the theoretical concept. By contrast, we propose the Swin Transformer as the backbone to extract the context information and design a novel decoder of densely connected feature aggregation module (DCFAM) to restore the resolution and produce the segmentation map. The experimental results on two remotely sensed semantic segmentation datasets demonstrate the effectiveness of the proposed scheme.