 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExchange Is All You Need for Remote Sensing Change Detection
Jan 12, 2026Remote sensing change detection fundamentally relies on the effective fusion and discrimination of bi-temporal features. Prevailing paradigms typically utilize Siamese encoders bridged by explicit difference computation modules, such as subtraction or concatenation, to identify changes. In this work, we challenge this complexity with SEED (Siamese Encoder-Exchange-Decoder), a streamlined paradigm that replaces explicit differencing with parameter-free feature exchange. By sharing weights across both Siamese encoders and decoders, SEED effectively operates as a single parameter set model. Theoretically, we formalize feature exchange as an orthogonal permutation operator and prove that, under pixel consistency, this mechanism preserves mutual information and Bayes optimal risk, whereas common arithmetic fusion methods often introduce information loss. Extensive experiments across five benchmarks, including SYSU-CD, LEVIR-CD, PX-CLCD, WaterCD, and CDD, and three backbones, namely SwinT, EfficientNet, and ResNet, demonstrate that SEED matches or surpasses state of the art methods despite its simplicity. Furthermore, we reveal that standard semantic segmentation models can be transformed into competitive change detectors solely by inserting this exchange mechanism, referred to as SEG2CD. The proposed paradigm offers a robust, unified, and interpretable framework for change detection, demonstrating that simple feature exchange is sufficient for high performance information fusion. Code and full training and evaluation protocols will be released at https://github.com/dyzy41/open-rscd.
PeftCD: Leveraging Vision Foundation Models with Parameter-Efficient Fine-Tuning for Remote Sensing Change Detection
Sep 11, 2025To tackle the prevalence of pseudo changes, the scarcity of labeled samples, and the difficulty of cross-domain generalization in multi-temporal and multi-source remote sensing imagery, we propose PeftCD, a change detection framework built upon Vision Foundation Models (VFMs) with Parameter-Efficient Fine-Tuning (PEFT). At its core, PeftCD employs a weight-sharing Siamese encoder derived from a VFM, into which LoRA and Adapter modules are seamlessly integrated. This design enables highly efficient task adaptation by training only a minimal set of additional parameters. To fully unlock the potential of VFMs, we investigate two leading backbones: the Segment Anything Model v2 (SAM2), renowned for its strong segmentation priors, and DINOv3, a state-of-the-art self-supervised representation learner. The framework is complemented by a deliberately lightweight decoder, ensuring the focus remains on the powerful feature representations from the backbones. Extensive experiments demonstrate that PeftCD achieves state-of-the-art performance across multiple public datasets, including SYSU-CD (IoU 73.81%), WHUCD (92.05%), MSRSCD (64.07%), MLCD (76.89%), CDD (97.01%), S2Looking (52.25%) and LEVIR-CD (85.62%), with notably precise boundary delineation and strong suppression of pseudo-changes. In summary, PeftCD presents an optimal balance of accuracy, efficiency, and generalization. It offers a powerful and scalable paradigm for adapting large-scale VFMs to real-world remote sensing change detection applications. The code and pretrained models will be released at https://github.com/dyzy41/PeftCD.
CFNet: Optimizing Remote Sensing Change Detection through Content-Aware Enhancement
Mar 11, 2025Change detection is a crucial and widely applied task in remote sensing, aimed at identifying and analyzing changes occurring in the same geographical area over time. Due to variability in acquisition conditions, bi-temporal remote sensing images often exhibit significant differences in image style. Even with the powerful generalization capabilities of DNNs, these unpredictable style variations between bi-temporal images inevitably affect model's ability to accurately detect changed areas. To address issue above, we propose the Content Focuser Network (CFNet), which takes content-aware strategy as a key insight. CFNet employs EfficientNet-B5 as the backbone for feature extraction. To enhance the model's focus on the content features of images while mitigating the misleading effects of style features, we develop a constraint strategy that prioritizes the content features of bi-temporal images, termed Content-Aware. Furthermore, to enable the model to flexibly focus on changed and unchanged areas according to the requirements of different stages, we design a reweighting module based on the cosine distance between bi-temporal image features, termed Focuser. CFNet achieve outstanding performance across three well-known change detection datasets: CLCD (F1: 81.41%, IoU: 68.65%), LEVIR-CD (F1: 92.18%, IoU: 85.49%), and SYSU-CD (F1: 82.89%, IoU: 70.78%). The code and pretrained models of CFNet are publicly released at https://github.com/wifiBlack/CFNet.
A Remote Sensing Image Change Detection Method Integrating Layer Exchange and Channel-Spatial Differences
Jan 19, 2025



Change detection in remote sensing imagery is a critical technique for Earth observation, primarily focusing on pixel-level segmentation of change regions between bi-temporal images. The essence of pixel-level change detection lies in determining whether corresponding pixels in bi-temporal images have changed. In deep learning, the spatial and channel dimensions of feature maps represent different information from the original images. In this study, we found that in change detection tasks, difference information can be computed not only from the spatial dimension of bi-temporal features but also from the channel dimension. Therefore, we designed the Channel-Spatial Difference Weighting (CSDW) module as an aggregation-distribution mechanism for bi-temporal features in change detection. This module enhances the sensitivity of the change detection model to difference features. Additionally, bi-temporal images share the same geographic location and exhibit strong inter-image correlations. To construct the correlation between bi-temporal images, we designed a decoding structure based on the Layer-Exchange (LE) method to enhance the interaction of bi-temporal features. Comprehensive experiments on the CLCD, PX-CLCD, LEVIR-CD, and S2Looking datasets demonstrate that the proposed LENet model significantly improves change detection performance. The code and pre-trained models will be available at: https://github.com/dyzy41/lenet.
EfficientCD: A New Strategy For Change Detection Based With Bi-temporal Layers Exchanged
Jul 22, 2024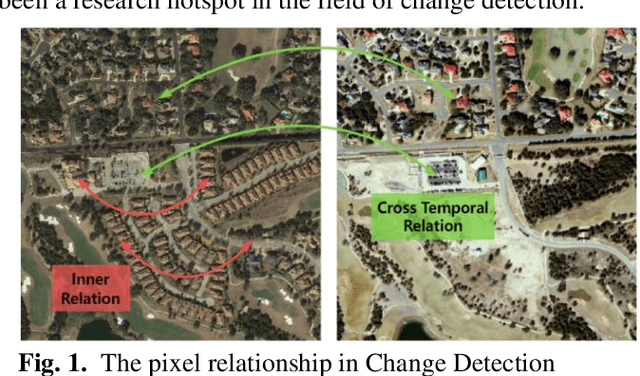

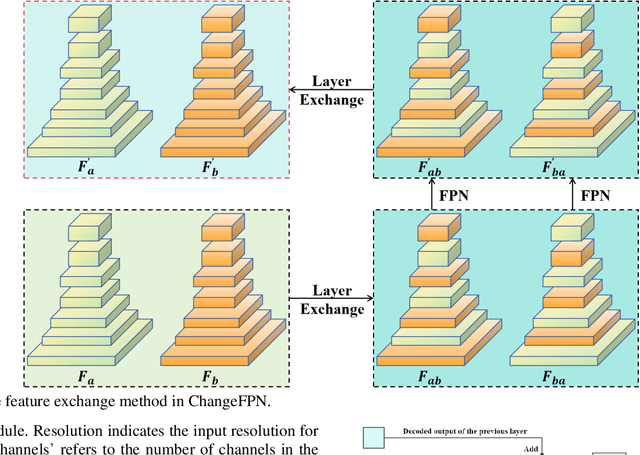
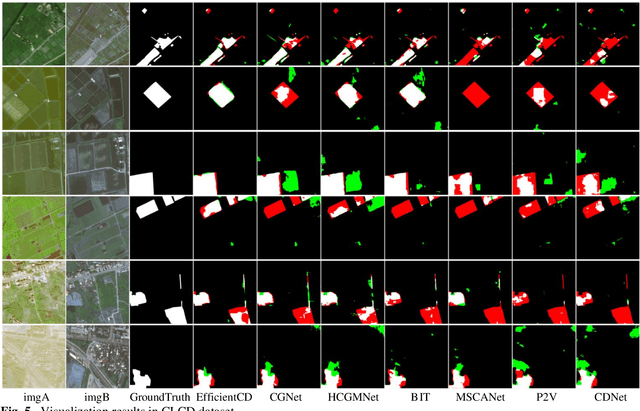
With the widespread application of remote sensing technology in environmental monitoring, the demand for efficient and accurate remote sensing image change detection (CD) for natural environments is growing. We propose a novel deep learning framework named EfficientCD, specifically designed for remote sensing image change detection. The framework employs EfficientNet as its backbone network for feature extraction. To enhance the information exchange between bi-temporal image feature maps, we have designed a new Feature Pyramid Network module targeted at remote sensing change detection, named ChangeFPN. Additionally, to make full use of the multi-level feature maps in the decoding stage, we have developed a layer-by-layer feature upsampling module combined with Euclidean distance to improve feature fusion and reconstruction during the decoding stage. The EfficientCD has been experimentally validated on four remote sensing datasets: LEVIR-CD, SYSU-CD, CLCD, and WHUCD. The experimental results demonstrate that EfficientCD exhibits outstanding performance in change detection accuracy. The code and pretrained models will be released at https://github.com/dyzy41/mmrscd.
PyramidMamba: Rethinking Pyramid Feature Fusion with Selective Space State Model for Semantic Segmentation of Remote Sensing Imagery
Jun 16, 2024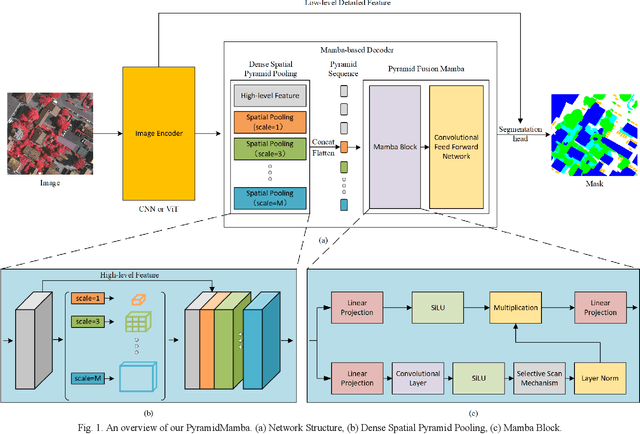
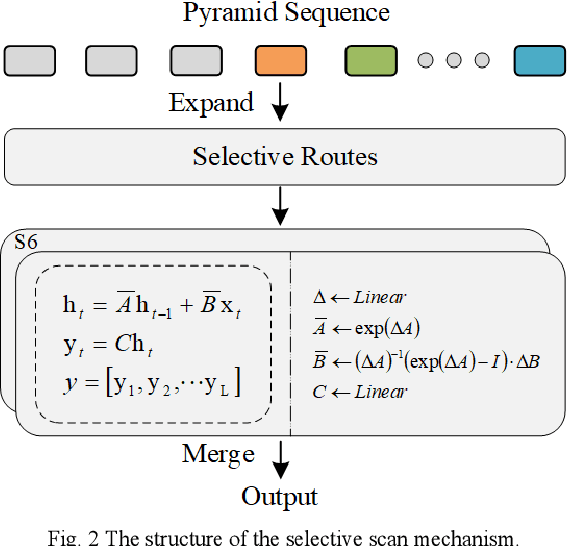
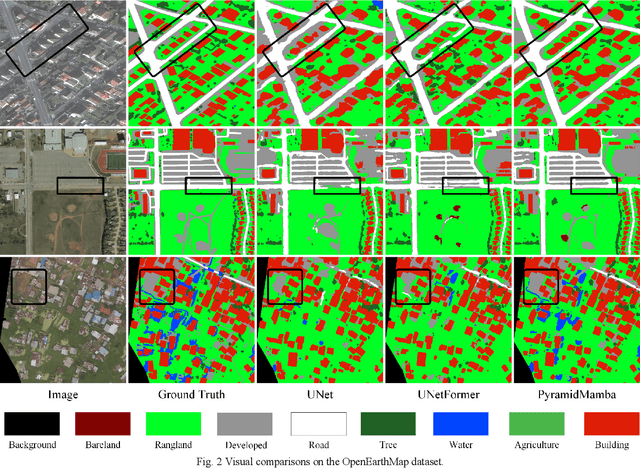
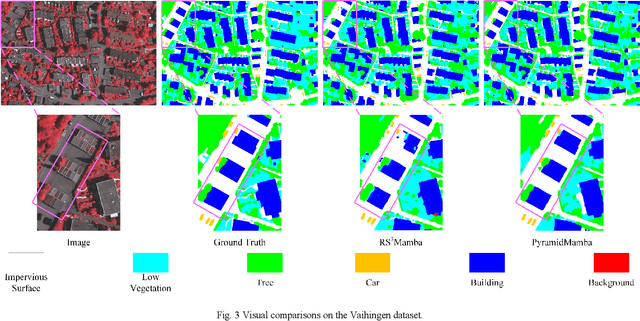
Semantic segmentation, as a basic tool for intelligent interpretation of remote sensing images, plays a vital role in many Earth Observation (EO) applications. Nowadays, accurate semantic segmentation of remote sensing images remains a challenge due to the complex spatial-temporal scenes and multi-scale geo-objects. Driven by the wave of deep learning (DL), CNN- and Transformer-based semantic segmentation methods have been explored widely, and these two architectures both revealed the importance of multi-scale feature representation for strengthening semantic information of geo-objects. However, the actual multi-scale feature fusion often comes with the semantic redundancy issue due to homogeneous semantic contents in pyramid features. To handle this issue, we propose a novel Mamba-based segmentation network, namely PyramidMamba. Specifically, we design a plug-and-play decoder, which develops a dense spatial pyramid pooling (DSPP) to encode rich multi-scale semantic features and a pyramid fusion Mamba (PFM) to reduce semantic redundancy in multi-scale feature fusion. Comprehensive ablation experiments illustrate the effectiveness and superiority of the proposed method in enhancing multi-scale feature representation as well as the great potential for real-time semantic segmentation. Moreover, our PyramidMamba yields state-of-the-art performance on three publicly available datasets, i.e. the OpenEarthMap (70.8% mIoU), ISPRS Vaihingen (84.8% mIoU) and Potsdam (88.0% mIoU) datasets. The code will be available at https://github.com/WangLibo1995/GeoSeg.
MetaSegNet: Metadata-collaborative Vision-Language Representation Learning for Semantic Segmentation of Remote Sensing Images
Dec 20, 2023Semantic segmentation of remote sensing images plays a vital role in a wide range of Earth Observation (EO) applications, such as land use land cover mapping, environment monitoring, and sustainable development. Driven by rapid developments in Artificial Intelligence (AI), deep learning (DL) has emerged as the mainstream tool for semantic segmentation and achieved many breakthroughs in the field of remote sensing. However, the existing DL-based methods mainly focus on unimodal visual data while ignoring the rich multimodal information involved in the real world, usually demonstrating weak reliability and generlization. Inspired by the success of Vision Transformers and large language models, we propose a novel metadata-collaborative multimodal segmentation network (MetaSegNet) that applies vision-language representation learning for semantic segmentation of remote sensing images. Unlike the common model structure that only uses unimodal visual data, we extract the key characteristic (i.e. the climate zone) from freely available remote sensing image metadata and transfer it into knowledge-based text prompts via the generic ChatGPT. Then, we construct an image encoder, a text encoder and a crossmodal attention fusion subnetwork to extract the image and text feature and apply image-text interaction. Benefiting from such a design, the proposed MetaSegNet demonstrates superior generalization and achieves competitive accuracy with state-of-the-art semantic segmentation methods on the large-scale OpenEarthMap dataset (68.6% mIoU) and Potsdam dataset (93.3% mean F1 score) as well as LoveDA dataset (52.2% mIoU).
Transformer Meets Convolution: A Bilateral Awareness Net-work for Semantic Segmentation of Very Fine Resolution Ur-ban Scene Images
Jun 23, 2021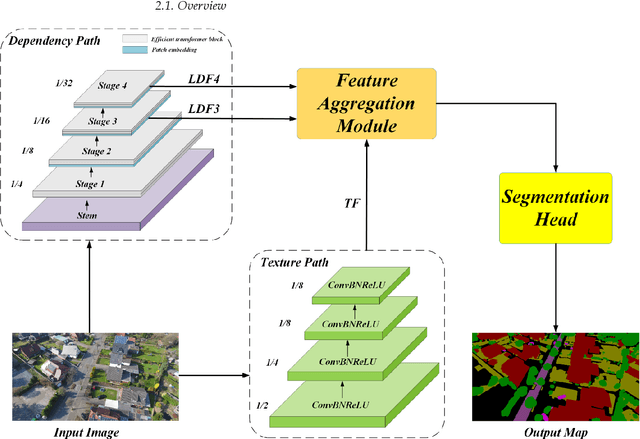
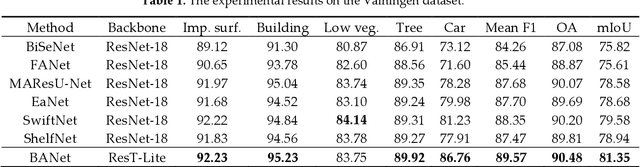
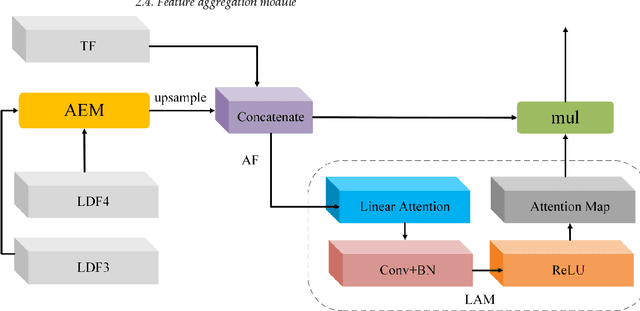
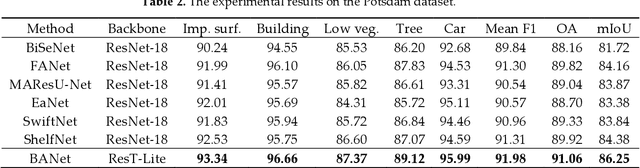
Semantic segmentation from very fine resolution (VFR) urban scene images plays a significant role in several application scenarios including autonomous driving, land cover classification, and urban planning, etc. However, the tremendous details contained in the VFR image severely limit the potential of the existing deep learning approaches. More seriously, the considerable variations in scale and appearance of objects further deteriorate the representational capacity of those se-mantic segmentation methods, leading to the confusion of adjacent objects. Addressing such is-sues represents a promising research field in the remote sensing community, which paves the way for scene-level landscape pattern analysis and decision making. In this manuscript, we pro-pose a bilateral awareness network (BANet) which contains a dependency path and a texture path to fully capture the long-range relationships and fine-grained details in VFR images. Specif-ically, the dependency path is conducted based on the ResT, a novel Transformer backbone with memory-efficient multi-head self-attention, while the texture path is built on the stacked convo-lution operation. Besides, using the linear attention mechanism, a feature aggregation module (FAM) is designed to effectively fuse the dependency features and texture features. Extensive experiments conducted on the three large-scale urban scene image segmentation datasets, i.e., ISPRS Vaihingen dataset, ISPRS Potsdam dataset, and UAVid dataset, demonstrate the effective-ness of our BANet. Specifically, a 64.6% mIoU is achieved on the UAVid dataset.
A Novel Transformer based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images
May 11, 2021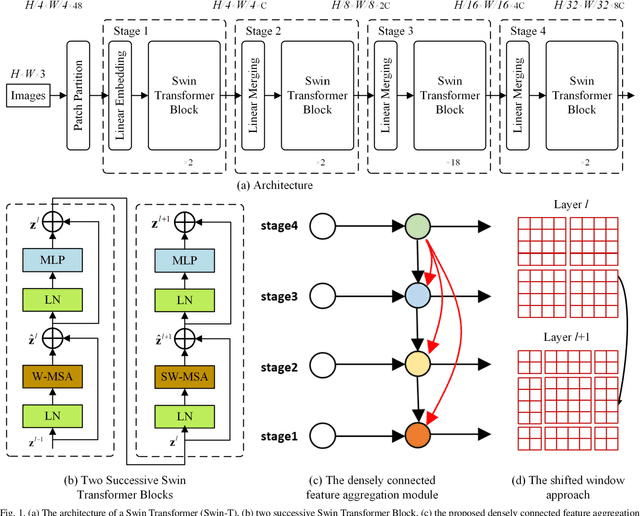
The fully-convolutional network (FCN) with an encoder-decoder architecture has been the standard paradigm for semantic segmentation. The encoder-decoder architecture utilizes an encoder to capture multi-level feature maps, which are incorporated into the final prediction by a decoder. As the context is crucial for precise segmentation, tremendous effort has been made to extract such information in an intelligent fashion, including employing dilated/atrous convolutions or inserting attention modules. However, these endeavours are all based on the FCN architecture with ResNet or other backbones, which cannot fully exploit the context from the theoretical concept. By contrast, we propose the Swin Transformer as the backbone to extract the context information and design a novel decoder of densely connected feature aggregation module (DCFAM) to restore the resolution and produce the segmentation map. The experimental results on two remotely sensed semantic segmentation datasets demonstrate the effectiveness of the proposed scheme.
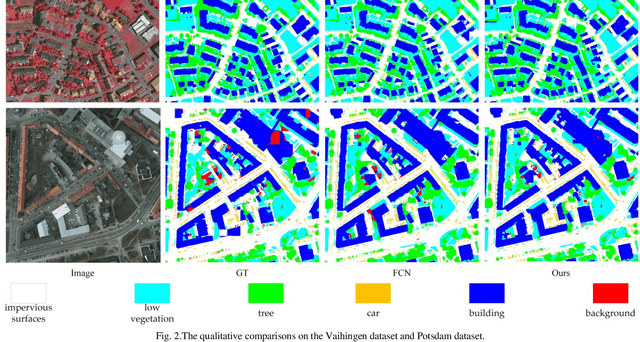
SaNet: Scale-aware Neural Network for Semantic Labelling of Multiple Spatial Resolution Aerial Images
Apr 10, 2021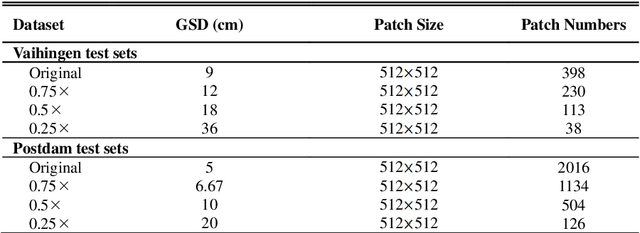


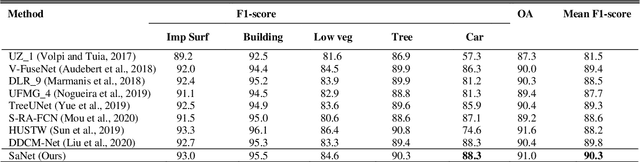
Assigning geospatial objects of aerial images with specific categories at the pixel level is a fundamental task in urban scene interpretation. Along with rapid developments in sensor technologies, aerial images can be captured at multiple spatial resolutions (MSR) with information content manifested at different scales. Extracting information from these MSR aerial images represents huge opportunities for enhanced feature representation and characterisation. However, MSR images suffer from two critical issues: 1) increased variation in the sizes of geospatial objects and 2) information and informative feature loss at coarse spatial resolutions. In this paper, we propose a novel scale-aware neural network (SaNet) for semantic labelling of MSR aerial images to address these two issues. SaNet deploys a densely connected feature network (DCFPN) module to capture high-quality multi-scale context, such as to address the scale variation issue and increase the quality of segmentation for both large and small objects simultaneously. A spatial feature recalibration (SFR) module is further incorporated into the network to learn complete semantic features with enhanced spatial relationships, where the effects of information and informative feature loss are addressed. The combination of DCFPN and SFR allows the proposed SaNet to learn scale-aware features from MSR aerial images. Extensive experiments undertaken on ISPRS semantic segmentation datasets demonstrated the outstanding accuracy of the proposed SaNet in cross-resolution segmentation, with an average OA of 83.4% on the Vaihingen dataset and an average F1 score of 80.4% on the Potsdam dataset, outperforming state-of-the-art deep learning approaches, including FPN (80.2% and 76.6%), PSPNet (79.8% and 76.2%) and Deeplabv3+ (80.8% and 76.1%) as well as DDCM-Net (81.7% and 77.6%) and EaNet (81.5% and 78.3%).