 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Manipulation via Trace-Conditioned VLA Planning
Apr 23, 2026Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip
EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Apr 08, 2026Robot learning increasingly depends on large and diverse data, yet robot data collection remains expensive and difficult to scale. Egocentric human data offer a promising alternative by capturing rich manipulation behavior across everyday environments. However, existing human datasets are often limited in scope, difficult to extend, and fragmented across institutions. We introduce EgoVerse, a collaborative platform for human data-driven robot learning that unifies data collection, processing, and access under a shared framework, enabling contributions from individual researchers, academic labs, and industry partners. The current release includes 1,362 hours (80k episodes) of human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 unique demonstrators, with standardized formats, manipulation-relevant annotations, and tooling for downstream learning. Beyond the dataset, we conduct a large-scale study of human-to-robot transfer with experiments replicated across multiple labs, tasks, and robot embodiments under shared protocols. We find that policy performance generally improves with increased human data, but that effective scaling depends on alignment between human data and robot learning objectives. Together, the dataset, platform, and study establish a foundation for reproducible progress in human data-driven robot learning. Videos and additional information can be found at https://egoverse.ai/
In-N-On: Scaling Egocentric Manipulation with in-the-wild and on-task Data
Nov 19, 2025Egocentric videos are a valuable and scalable data source to learn manipulation policies. However, due to significant data heterogeneity, most existing approaches utilize human data for simple pre-training, which does not unlock its full potential. This paper first provides a scalable recipe for collecting and using egocentric data by categorizing human data into two categories: in-the-wild and on-task alongside with systematic analysis on how to use the data. We first curate a dataset, PHSD, which contains over 1,000 hours of diverse in-the-wild egocentric data and over 20 hours of on-task data directly aligned to the target manipulation tasks. This enables learning a large egocentric language-conditioned flow matching policy, Human0. With domain adaptation techniques, Human0 minimizes the gap between humans and humanoids. Empirically, we show Human0 achieves several novel properties from scaling human data, including language following of instructions from only human data, few-shot learning, and improved robustness using on-task data. Project website: https://xiongyicai.github.io/In-N-On/
AirCopBench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoning
Nov 14, 2025
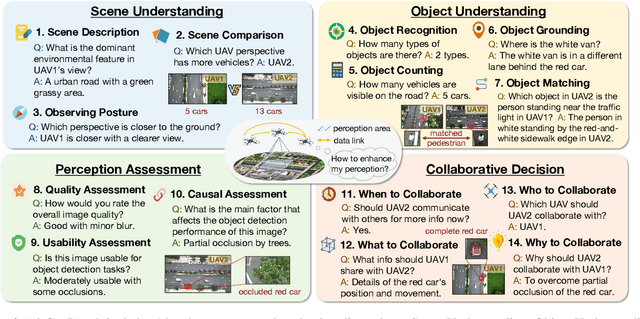
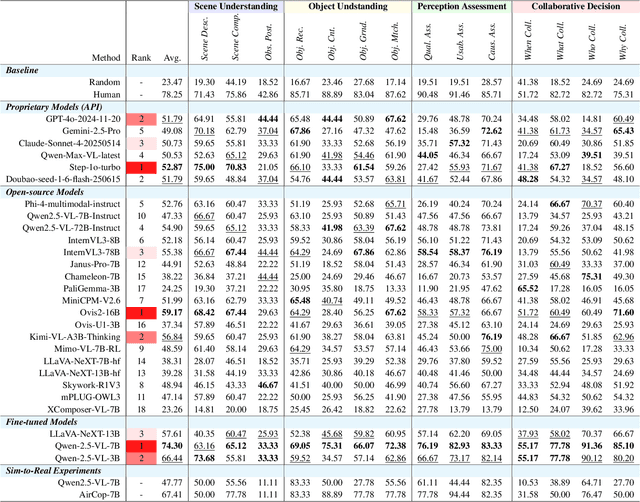
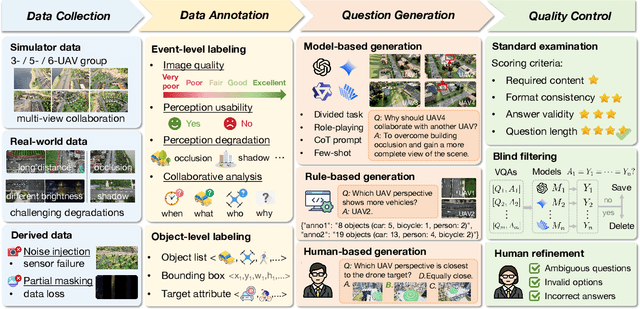
Multimodal Large Language Models (MLLMs) have shown promise in single-agent vision tasks, yet benchmarks for evaluating multi-agent collaborative perception remain scarce. This gap is critical, as multi-drone systems provide enhanced coverage, robustness, and collaboration compared to single-sensor setups. Existing multi-image benchmarks mainly target basic perception tasks using high-quality single-agent images, thus failing to evaluate MLLMs in more complex, egocentric collaborative scenarios, especially under real-world degraded perception conditions.To address these challenges, we introduce AirCopBench, the first comprehensive benchmark designed to evaluate MLLMs in embodied aerial collaborative perception under challenging perceptual conditions. AirCopBench includes 14.6k+ questions derived from both simulator and real-world data, spanning four key task dimensions: Scene Understanding, Object Understanding, Perception Assessment, and Collaborative Decision, across 14 task types. We construct the benchmark using data from challenging degraded-perception scenarios with annotated collaborative events, generating large-scale questions through model-, rule-, and human-based methods under rigorous quality control. Evaluations on 40 MLLMs show significant performance gaps in collaborative perception tasks, with the best model trailing humans by 24.38% on average and exhibiting inconsistent results across tasks. Fine-tuning experiments further confirm the feasibility of sim-to-real transfer in aerial collaborative perception and reasoning.
PeftCD: Leveraging Vision Foundation Models with Parameter-Efficient Fine-Tuning for Remote Sensing Change Detection
Sep 11, 2025To tackle the prevalence of pseudo changes, the scarcity of labeled samples, and the difficulty of cross-domain generalization in multi-temporal and multi-source remote sensing imagery, we propose PeftCD, a change detection framework built upon Vision Foundation Models (VFMs) with Parameter-Efficient Fine-Tuning (PEFT). At its core, PeftCD employs a weight-sharing Siamese encoder derived from a VFM, into which LoRA and Adapter modules are seamlessly integrated. This design enables highly efficient task adaptation by training only a minimal set of additional parameters. To fully unlock the potential of VFMs, we investigate two leading backbones: the Segment Anything Model v2 (SAM2), renowned for its strong segmentation priors, and DINOv3, a state-of-the-art self-supervised representation learner. The framework is complemented by a deliberately lightweight decoder, ensuring the focus remains on the powerful feature representations from the backbones. Extensive experiments demonstrate that PeftCD achieves state-of-the-art performance across multiple public datasets, including SYSU-CD (IoU 73.81%), WHUCD (92.05%), MSRSCD (64.07%), MLCD (76.89%), CDD (97.01%), S2Looking (52.25%) and LEVIR-CD (85.62%), with notably precise boundary delineation and strong suppression of pseudo-changes. In summary, PeftCD presents an optimal balance of accuracy, efficiency, and generalization. It offers a powerful and scalable paradigm for adapting large-scale VFMs to real-world remote sensing change detection applications. The code and pretrained models will be released at https://github.com/dyzy41/PeftCD.
M2IO-R1: An Efficient RL-Enhanced Reasoning Framework for Multimodal Retrieval Augmented Multimodal Generation
Aug 08, 2025Current research on Multimodal Retrieval-Augmented Generation (MRAG) enables diverse multimodal inputs but remains limited to single-modality outputs, restricting expressive capacity and practical utility. In contrast, real-world applications often demand both multimodal inputs and multimodal outputs for effective communication and grounded reasoning. Motivated by the recent success of Reinforcement Learning (RL) in complex reasoning tasks for Large Language Models (LLMs), we adopt RL as a principled and effective paradigm to address the multi-step, outcome-driven challenges inherent in multimodal output generation. Here, we introduce M2IO-R1, a novel framework for Multimodal Retrieval-Augmented Multimodal Generation (MRAMG) that supports both multimodal inputs and outputs. Central to our framework is an RL-based inserter, Inserter-R1-3B, trained with Group Relative Policy Optimization to guide image selection and placement in a controllable and semantically aligned manner. Empirical results show that our lightweight 3B inserter achieves strong reasoning capabilities with significantly reduced latency, outperforming baselines in both quality and efficiency.
HuB: Learning Extreme Humanoid Balance
May 12, 2025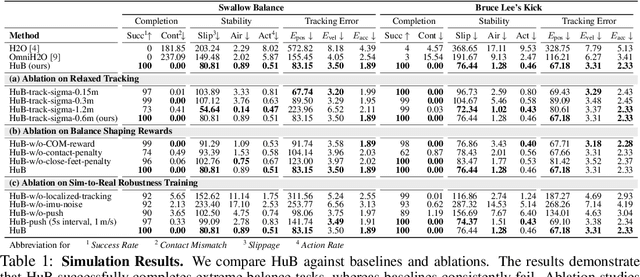
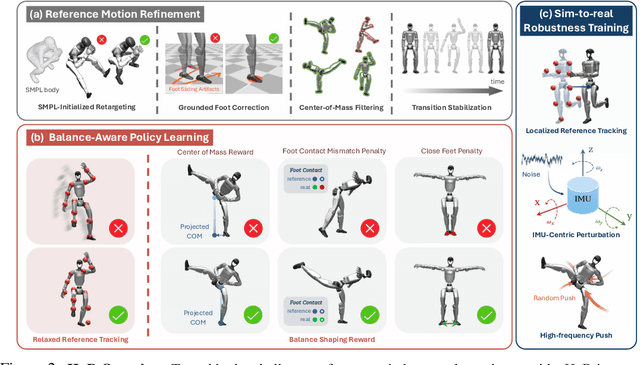
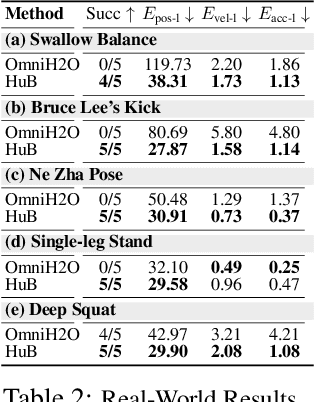
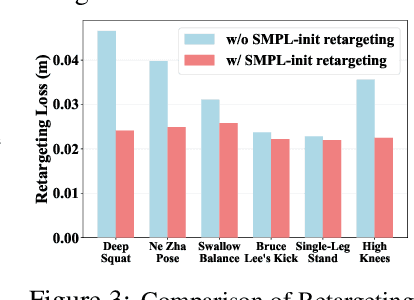
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
FP3: A 3D Foundation Policy for Robotic Manipulation
Mar 11, 2025Following its success in natural language processing and computer vision, foundation models that are pre-trained on large-scale multi-task datasets have also shown great potential in robotics. However, most existing robot foundation models rely solely on 2D image observations, ignoring 3D geometric information, which is essential for robots to perceive and reason about the 3D world. In this paper, we introduce FP3, a first large-scale 3D foundation policy model for robotic manipulation. FP3 builds on a scalable diffusion transformer architecture and is pre-trained on 60k trajectories with point cloud observations. With the model design and diverse pre-training data, FP3 can be efficiently fine-tuned for downstream tasks while exhibiting strong generalization capabilities. Experiments on real robots demonstrate that with only 80 demonstrations, FP3 is able to learn a new task with over 90% success rates in novel environments with unseen objects, significantly surpassing existing robot foundation models.
A Remote Sensing Image Change Detection Method Integrating Layer Exchange and Channel-Spatial Differences
Jan 19, 2025



Change detection in remote sensing imagery is a critical technique for Earth observation, primarily focusing on pixel-level segmentation of change regions between bi-temporal images. The essence of pixel-level change detection lies in determining whether corresponding pixels in bi-temporal images have changed. In deep learning, the spatial and channel dimensions of feature maps represent different information from the original images. In this study, we found that in change detection tasks, difference information can be computed not only from the spatial dimension of bi-temporal features but also from the channel dimension. Therefore, we designed the Channel-Spatial Difference Weighting (CSDW) module as an aggregation-distribution mechanism for bi-temporal features in change detection. This module enhances the sensitivity of the change detection model to difference features. Additionally, bi-temporal images share the same geographic location and exhibit strong inter-image correlations. To construct the correlation between bi-temporal images, we designed a decoding structure based on the Layer-Exchange (LE) method to enhance the interaction of bi-temporal features. Comprehensive experiments on the CLCD, PX-CLCD, LEVIR-CD, and S2Looking datasets demonstrate that the proposed LENet model significantly improves change detection performance. The code and pre-trained models will be available at: https://github.com/dyzy41/lenet.
UniHOI: Learning Fast, Dense and Generalizable 4D Reconstruction for Egocentric Hand Object Interaction Videos
Nov 14, 2024Egocentric Hand Object Interaction (HOI) videos provide valuable insights into human interactions with the physical world, attracting growing interest from the computer vision and robotics communities. A key task in fully understanding the geometry and dynamics of HOI scenes is dense pointclouds sequence reconstruction. However, the inherent motion of both hands and the camera makes this challenging. Current methods often rely on time-consuming test-time optimization, making them impractical for reconstructing internet-scale videos. To address this, we introduce UniHOI, a model that unifies the estimation of all variables necessary for dense 4D reconstruction, including camera intrinsic, camera poses, and video depth, for egocentric HOI scene in a fast feed-forward manner. We end-to-end optimize all these variables to improve their consistency in 3D space. Furthermore, our model could be trained solely on large-scale monocular video dataset, overcoming the limitation of scarce labeled HOI data. We evaluate UniHOI with both in-domain and zero-shot generalization setting, surpassing all baselines in pointclouds sequence reconstruction and long-term 3D scene flow recovery. UniHOI is the first approach to offer fast, dense, and generalizable monocular egocentric HOI scene reconstruction in the presence of motion. Code and trained model will be released in the future.