 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLOFetch: Compressed-Hierarchical Instruction Prefetching for Cloud Microservices
Nov 06, 2025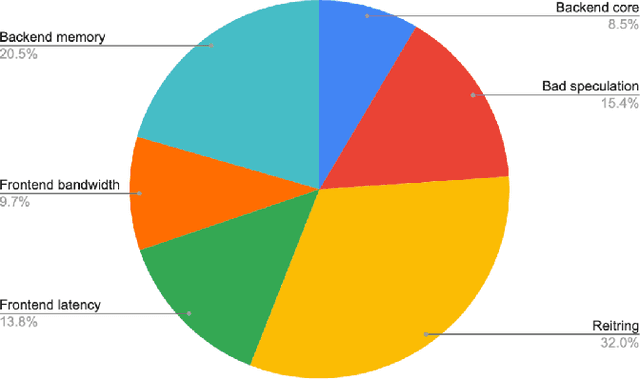
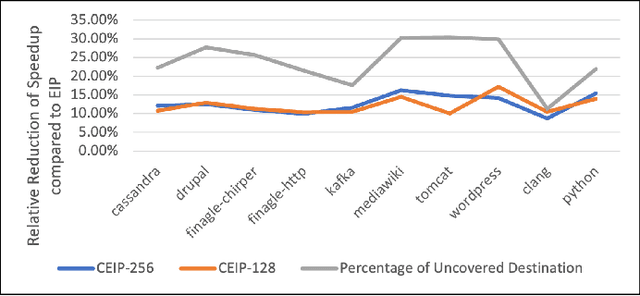
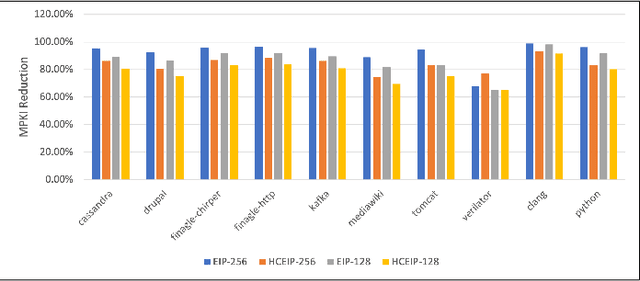
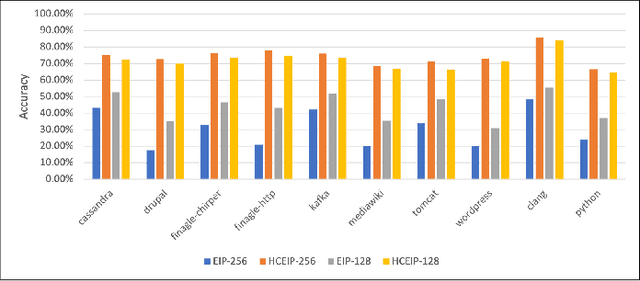
Large-scale networked services rely on deep soft-ware stacks and microservice orchestration, which increase instruction footprints and create frontend stalls that inflate tail latency and energy. We revisit instruction prefetching for these cloud workloads and present a design that aligns with SLO driven and self optimizing systems. Building on the Entangling Instruction Prefetcher (EIP), we introduce a Compressed Entry that captures up to eight destinations around a base using 36 bits by exploiting spatial clustering, and a Hierarchical Metadata Storage scheme that keeps only L1 resident and frequently queried entries on chip while virtualizing bulk metadata into lower levels. We further add a lightweight Online ML Controller that scores prefetch profitability using context features and a bandit adjusted threshold. On data center applications, our approach preserves EIP like speedups with smaller on chip state and improves efficiency for networked services in the ML era.
A Gravity-informed Spatiotemporal Transformer for Human Activity Intensity Prediction
Jun 16, 2025Human activity intensity prediction is a crucial to many location-based services. Although tremendous progress has been made to model dynamic spatiotemporal patterns of human activity, most existing methods, including spatiotemporal graph neural networks (ST-GNNs), overlook physical constraints of spatial interactions and the over-smoothing phenomenon in spatial correlation modeling. To address these limitations, this work proposes a physics-informed deep learning framework, namely Gravity-informed Spatiotemporal Transformer (Gravityformer) by refining transformer attention to integrate the universal law of gravitation and explicitly incorporating constraints from spatial interactions. Specifically, it (1) estimates two spatially explicit mass parameters based on inflow and outflow, (2) models the likelihood of cross-unit interaction using closed-form solutions of spatial interactions to constrain spatial modeling randomness, and (3) utilizes the learned spatial interaction to guide and mitigate the over-smoothing phenomenon in transformer attention matrices. The underlying law of human activity can be explicitly modeled by the proposed adaptive gravity model. Moreover, a parallel spatiotemporal graph convolution transformer structure is proposed for achieving a balance between coupled spatial and temporal learning. Systematic experiments on six real-world large-scale activity datasets demonstrate the quantitative and qualitative superiority of our approach over state-of-the-art benchmarks. Additionally, the learned gravity attention matrix can be disentangled and interpreted based on geographical laws. This work provides a novel insight into integrating physical laws with deep learning for spatiotemporal predictive learning.
A Narrative Review on Large AI Models in Lung Cancer Screening, Diagnosis, and Treatment Planning
Jun 08, 2025Lung cancer remains one of the most prevalent and fatal diseases worldwide, demanding accurate and timely diagnosis and treatment. Recent advancements in large AI models have significantly enhanced medical image understanding and clinical decision-making. This review systematically surveys the state-of-the-art in applying large AI models to lung cancer screening, diagnosis, prognosis, and treatment. We categorize existing models into modality-specific encoders, encoder-decoder frameworks, and joint encoder architectures, highlighting key examples such as CLIP, BLIP, Flamingo, BioViL-T, and GLoRIA. We further examine their performance in multimodal learning tasks using benchmark datasets like LIDC-IDRI, NLST, and MIMIC-CXR. Applications span pulmonary nodule detection, gene mutation prediction, multi-omics integration, and personalized treatment planning, with emerging evidence of clinical deployment and validation. Finally, we discuss current limitations in generalizability, interpretability, and regulatory compliance, proposing future directions for building scalable, explainable, and clinically integrated AI systems. Our review underscores the transformative potential of large AI models to personalize and optimize lung cancer care.
RegionGCN: Spatial-Heterogeneity-Aware Graph Convolutional Networks
Jan 29, 2025



Modeling spatial heterogeneity in the data generation process is essential for understanding and predicting geographical phenomena. Despite their prevalence in geospatial tasks, neural network models usually assume spatial stationarity, which could limit their performance in the presence of spatial process heterogeneity. By allowing model parameters to vary over space, several approaches have been proposed to incorporate spatial heterogeneity into neural networks. However, current geographically weighting approaches are ineffective on graph neural networks, yielding no significant improvement in prediction accuracy. We assume the crux lies in the over-fitting risk brought by a large number of local parameters. Accordingly, we propose to model spatial process heterogeneity at the regional level rather than at the individual level, which largely reduces the number of spatially varying parameters. We further develop a heuristic optimization procedure to learn the region partition adaptively in the process of model training. Our proposed spatial-heterogeneity-aware graph convolutional network, named RegionGCN, is applied to the spatial prediction of county-level vote share in the 2016 US presidential election based on socioeconomic attributes. Results show that RegionGCN achieves significant improvement over the basic and geographically weighted GCNs. We also offer an exploratory analysis tool for the spatial variation of non-linear relationships through ensemble learning of regional partitions from RegionGCN. Our work contributes to the practice of Geospatial Artificial Intelligence (GeoAI) in tackling spatial heterogeneity.
Identifying Influential nodes in Brain Networks via Self-Supervised Graph-Transformer
Sep 17, 2024


Studying influential nodes (I-nodes) in brain networks is of great significance in the field of brain imaging. Most existing studies consider brain connectivity hubs as I-nodes. However, this approach relies heavily on prior knowledge from graph theory, which may overlook the intrinsic characteristics of the brain network, especially when its architecture is not fully understood. In contrast, self-supervised deep learning can learn meaningful representations directly from the data. This approach enables the exploration of I-nodes for brain networks, which is also lacking in current studies. This paper proposes a Self-Supervised Graph Reconstruction framework based on Graph-Transformer (SSGR-GT) to identify I-nodes, which has three main characteristics. First, as a self-supervised model, SSGR-GT extracts the importance of brain nodes to the reconstruction. Second, SSGR-GT uses Graph-Transformer, which is well-suited for extracting features from brain graphs, combining both local and global characteristics. Third, multimodal analysis of I-nodes uses graph-based fusion technology, combining functional and structural brain information. The I-nodes we obtained are distributed in critical areas such as the superior frontal lobe, lateral parietal lobe, and lateral occipital lobe, with a total of 56 identified across different experiments. These I-nodes are involved in more brain networks than other regions, have longer fiber connections, and occupy more central positions in structural connectivity. They also exhibit strong connectivity and high node efficiency in both functional and structural networks. Furthermore, there is a significant overlap between the I-nodes and both the structural and functional rich-club. These findings enhance our understanding of the I-nodes within the brain network, and provide new insights for future research in further understanding the brain working mechanisms.
Uncover the nature of overlapping community in cities
Jan 31, 2024



Urban spaces, though often perceived as discrete communities, are shared by various functional and social groups. Our study introduces a graph-based physics-aware deep learning framework, illuminating the intricate overlapping nature inherent in urban communities. Through analysis of individual mobile phone positioning data at Twin Cities metro area (TCMA) in Minnesota, USA, our findings reveal that 95.7 % of urban functional complexity stems from the overlapping structure of communities during weekdays. Significantly, our research not only quantifies these overlaps but also reveals their compelling correlations with income and racial indicators, unraveling the complex segregation patterns in U.S. cities. As the first to elucidate the overlapping nature of urban communities, this work offers a unique geospatial perspective on looking at urban structures, highlighting the nuanced interplay of socioeconomic dynamics within cities.
ChatGPT Informed Graph Neural Network for Stock Movement Prediction
Jun 07, 2023ChatGPT has demonstrated remarkable capabilities across various natural language processing (NLP) tasks. However, its potential for inferring dynamic network structures from temporal textual data, specifically financial news, remains an unexplored frontier. In this research, we introduce a novel framework that leverages ChatGPT's graph inference capabilities to enhance Graph Neural Networks (GNN). Our framework adeptly extracts evolving network structures from textual data, and incorporates these networks into graph neural networks for subsequent predictive tasks. The experimental results from stock movement forecasting indicate our model has consistently outperformed the state-of-the-art Deep Learning-based benchmarks. Furthermore, the portfolios constructed based on our model's outputs demonstrate higher annualized cumulative returns, alongside reduced volatility and maximum drawdown. This superior performance highlights the potential of ChatGPT for text-based network inferences and underscores its promising implications for the financial sector.
Interpreting County Level COVID-19 Infection and Feature Sensitivity using Deep Learning Time Series Models
Oct 06, 2022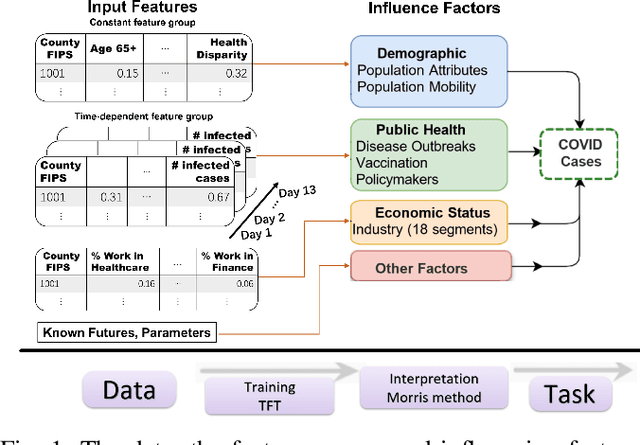
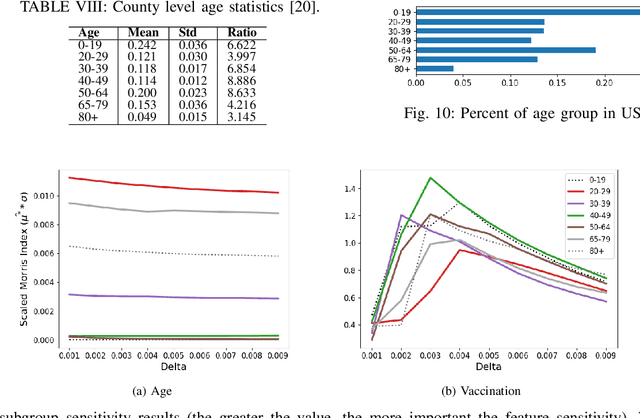
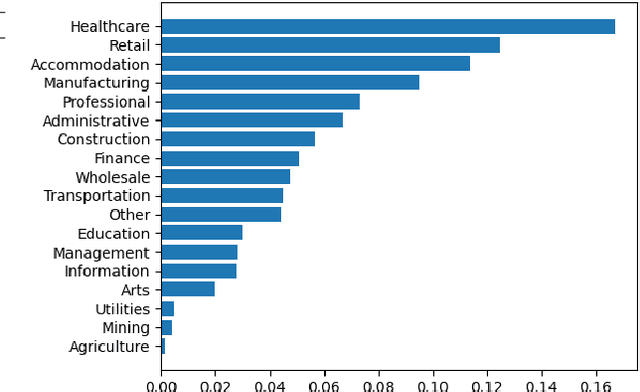
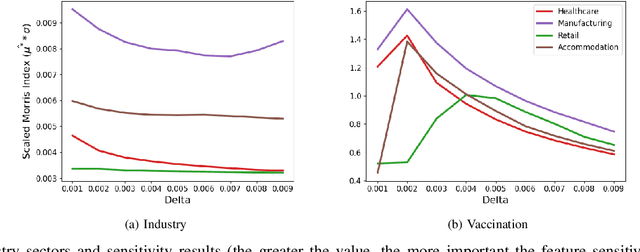
Interpretable machine learning plays a key role in healthcare because it is challenging in understanding feature importance in deep learning model predictions. We propose a novel framework that uses deep learning to study feature sensitivity for model predictions. This work combines sensitivity analysis with heterogeneous time-series deep learning model prediction, which corresponds to the interpretations of spatio-temporal features. We forecast county-level COVID-19 infection using the Temporal Fusion Transformer. We then use the sensitivity analysis extending Morris Method to see how sensitive the outputs are with respect to perturbation to our static and dynamic input features. The significance of the work is grounded in a real-world COVID-19 infection prediction with highly non-stationary, finely granular, and heterogeneous data. 1) Our model can capture the detailed daily changes of temporal and spatial model behaviors and achieves high prediction performance compared to a PyTorch baseline. 2) By analyzing the Morris sensitivity indices and attention patterns, we decipher the meaning of feature importance with observational population and dynamic model changes. 3) We have collected 2.5 years of socioeconomic and health features over 3142 US counties, such as observed cases and deaths, and a number of static (age distribution, health disparity, and industry) and dynamic features (vaccination, disease spread, transmissible cases, and social distancing). Using the proposed framework, we conduct extensive experiments and show our model can learn complex interactions and perform predictions for daily infection at the county level. Being able to model the disease infection with a hybrid prediction and description accuracy measurement with Morris index at the county level is a central idea that sheds light on individual feature interpretation via sensitivity analysis.
Sensing population distribution from satellite imagery via deep learning: model selection, neighboring effect, and systematic biases
Mar 03, 2021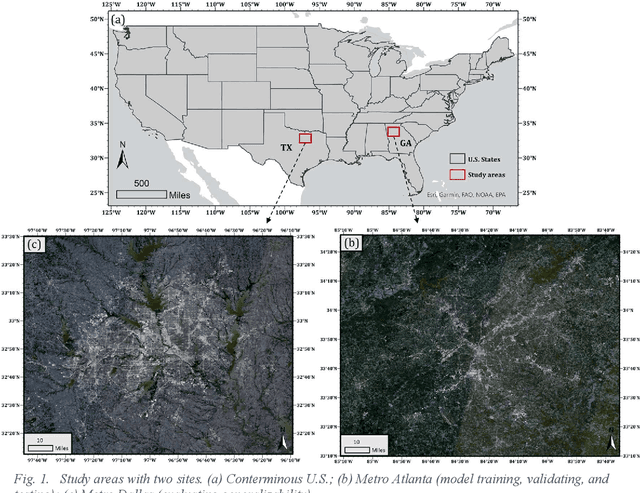
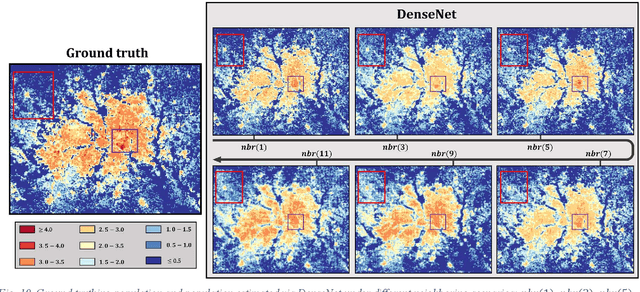

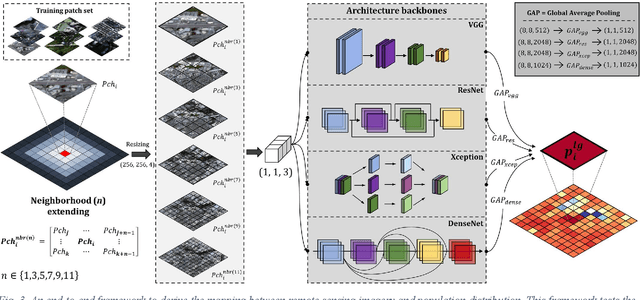
The rapid development of remote sensing techniques provides rich, large-coverage, and high-temporal information of the ground, which can be coupled with the emerging deep learning approaches that enable latent features and hidden geographical patterns to be extracted. This study marks the first attempt to cross-compare performances of popular state-of-the-art deep learning models in estimating population distribution from remote sensing images, investigate the contribution of neighboring effect, and explore the potential systematic population estimation biases. We conduct an end-to-end training of four popular deep learning architectures, i.e., VGG, ResNet, Xception, and DenseNet, by establishing a mapping between Sentinel-2 image patches and their corresponding population count from the LandScan population grid. The results reveal that DenseNet outperforms the other three models, while VGG has the worst performances in all evaluating metrics under all selected neighboring scenarios. As for the neighboring effect, contradicting existing studies, our results suggest that the increase of neighboring sizes leads to reduced population estimation performance, which is found universal for all four selected models in all evaluating metrics. In addition, there exists a notable, universal bias that all selected deep learning models tend to overestimate sparsely populated image patches and underestimate densely populated image patches, regardless of neighboring sizes. The methodological, experimental, and contextual knowledge this study provides is expected to benefit a wide range of future studies that estimate population distribution via remote sensing imagery.
Learning Local Feature Descriptor with Motion Attribute for Vision-based Localization
Aug 07, 2019
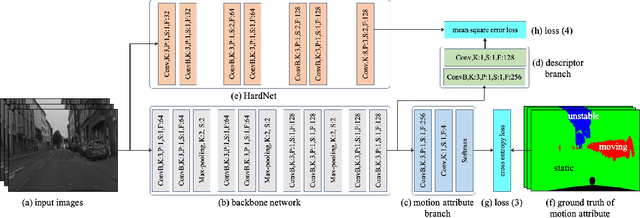
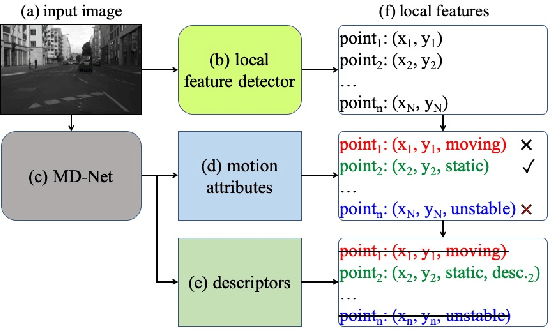

In recent years, camera-based localization has been widely used for robotic applications, and most proposed algorithms rely on local features extracted from recorded images. For better performance, the features used for open-loop localization are required to be short-term globally static, and the ones used for re-localization or loop closure detection need to be long-term static. Therefore, the motion attribute of a local feature point could be exploited to improve localization performance, e.g., the feature points extracted from moving persons or vehicles can be excluded from these systems due to their unsteadiness. In this paper, we design a fully convolutional network (FCN), named MD-Net, to perform motion attribute estimation and feature description simultaneously. MD-Net has a shared backbone network to extract features from the input image and two network branches to complete each sub-task. With MD-Net, we can obtain the motion attribute while avoiding increasing much more computation. Experimental results demonstrate that the proposed method can learn distinct local feature descriptor along with motion attribute only using an FCN, by outperforming competing methods by a wide margin. We also show that the proposed algorithm can be integrated into a vision-based localization algorithm to improve estimation accuracy significantly.