 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Paradox of Outcome Optimization: A Causal Information-Theoretic Bound on Reasoning Shortcuts in LLMs
May 30, 2026Large Language Models (LLMs) aligned via outcome-based Reinforcement Learning (RL) frequently exhibit a critical failure mode: they achieve high performance on in-distribution benchmarks while demonstrating brittle reasoning capabilities on out-of-distribution (OOD) tasks. We term this phenomenon Reward-Induced Manifold Collapse. We establish a theoretical framework bridging Structural Causal Models (SCM) and the Information Bottleneck (IB) principle to explain this paradox. We define reasoning as a high-complexity causal process and shortcut learning as the exploitation of low-complexity spurious correlations. Under the implicit inductive bias of Stochastic Gradient Descent (SGD), models optimized for outcome rewards are biased toward shortcut solutions whenever the training distribution allows for a ``Markovian Screening'' of the true causal mechanism. We derive a new generalization bound based on Semantic Coverage Measure ($η$) rather than sample size, showing why data scaling on homogeneous distributions may fail to correct reasoning flaws. We also show that Process Reward Models (PRMs) function as Topological Filters, enforcing step-wise mutual information constraints that render the low-complexity shortcut manifold inadmissible. These results provide a mathematical grounding for the role of process supervision beyond simple credit assignment.
FundaPod: A Multi-Persona Agent Pod Platform with Knowledge Graph Memory for AI-Assisted Fundamental Investment Research
May 28, 2026Large language models (LLMs) are increasingly applied in finance, yet most existing work emphasizes trading signals or financial NLP tasks centered on prediction. Institutional fundamental research, by contrast, requires human analysts or AI agents to gather evidence, identify business drivers, compare competing viewpoints, and generate investment memos. Its broader goal is not merely to predict outcomes, but to produce investment plans that are transparent, reusable, and verifiable, while contributing to the cumulative development of investment knowledge. We present FundaPod, a multi-persona agent platform for AI-assisted fundamental investment research. We argue that fundamental research is a human-centric decision-support task that is qualitatively distinct from trading-signal generation, and is therefore better served by an independence-preserving architecture. In FundaPod, AI agents with different personas, such as value investors or macro strategists, conduct research independently under a shared provenance contract. Their disagreements are then surfaced post hoc for adjudication by the human portfolio manager (PM) through a knowledge-graph memory system. This paper contributes five design principles for human-AI hybrid systems supporting fundamental research, grounded in design-science practice and theories of cognitive isolation and human-machine coordination. It also describes four architectural mechanisms: a persona distillation pipeline that turns public investor materials into deployable agents; a declarative skill registry that lets the planner derive typed task graphs; a grounded evidence model that links memo claims to verifiable sources; and a knowledge-graph "second brain" that connects tickers, memos, analysts, and themes. We demonstrate the architecture through a complete case study and a persona-based memo comparison.
Generalist Graph Anomaly Detection via Prototype-Based Distillation
May 26, 2026Driven by the pressing demand for graph anomaly detection (GAD) in high-stakes domains, the generalist GAD paradigm, which trains a single detector transferable across new graphs, has recently gained growing attention. However, existing methods often rely on scarce and costly annotations for training and sometimes even require few-shot support at inference, which limits their robustness to diverse and unseen anomaly patterns. To address this limitation, we introduce ProMoS, the first unsupervised generalist GAD framework, which detects anomalies by modeling the abundant normality in unlabeled data. ProMoS adopts a knowledge-distillation paradigm to distill normality priors from a frozen self-supervised graph neural network (GNN) teacher to a mixture-of-students model with shared global and lightweight personalized branches, enabling efficient and expressive normality modeling without learning from scratch. We further propose prototype-guided soft-label distillation to align teacher and student in a shared prototype space, enhancing cross-graph generalizability. During inference, ProMoS performs zero-shot anomaly detection on unseen graphs via distillation bias and prototype geometric deviation. Extensive experiments show the effectiveness and efficiency of ProMoS, charting a practical path toward label-free, zero-shot generalist GAD.
CREval: An Automated Interpretable Evaluation for Creative Image Manipulation under Complex Instructions
Mar 27, 2026Instruction-based multimodal image manipulation has recently made rapid progress. However, existing evaluation methods lack a systematic and human-aligned framework for assessing model performance on complex and creative editing tasks. To address this gap, we propose CREval, a fully automated question-answer (QA)-based evaluation pipeline that overcomes the incompleteness and poor interpretability of opaque Multimodal Large Language Models (MLLMs) scoring. Simultaneously, we introduce CREval-Bench, a comprehensive benchmark specifically designed for creative image manipulation under complex instructions. CREval-Bench covers three categories and nine creative dimensions, comprising over 800 editing samples and 13K evaluation queries. Leveraging this pipeline and benchmark, we systematically evaluate a diverse set of state-of-the-art open and closed-source models. The results reveal that while closed-source models generally outperform open-source ones on complex and creative tasks, all models still struggle to complete such edits effectively. In addition, user studies demonstrate strong consistency between CREval's automated metrics and human judgments. Therefore, CREval provides a reliable foundation for evaluating image editing models on complex and creative image manipulation tasks, and highlights key challenges and opportunities for future research.
Lean Clients, Full Accuracy: Hybrid Zeroth- and First-Order Split Federated Learning
Jan 14, 2026Split Federated Learning (SFL) enables collaborative training between resource-constrained edge devices and a compute-rich server. Communication overhead is a central issue in SFL and can be mitigated with auxiliary networks. Yet, the fundamental client-side computation challenge remains, as back-propagation requires substantial memory and computation costs, severely limiting the scale of models that edge devices can support. To enable more resource-efficient client computation and reduce the client-server communication, we propose HERON-SFL, a novel hybrid optimization framework that integrates zeroth-order (ZO) optimization for local client training while retaining first-order (FO) optimization on the server. With the assistance of auxiliary networks, ZO updates enable clients to approximate local gradients using perturbed forward-only evaluations per step, eliminating memory-intensive activation caching and avoiding explicit gradient computation in the traditional training process. Leveraging the low effective rank assumption, we theoretically prove that HERON-SFL's convergence rate is independent of model dimensionality, addressing a key scalability concern common to ZO algorithms. Empirically, on ResNet training and language model (LM) fine-tuning tasks, HERON-SFL matches benchmark accuracy while reducing client peak memory by up to 64% and client-side compute cost by up to 33% per step, substantially expanding the range of models that can be trained or adapted on resource-limited devices.
Machine Learning-Driven Creep Law Discovery Across Alloy Compositional Space
Jan 13, 2026Hihg-temperature creep characterization of structural alloys traditionally relies on serial uniaxial tests, which are highly inefficient for exploring the large search space of alloy compositions and for material discovery. Here, we introduce a machine-learning-assisted, high-throughput framework for creep law identification based on a dimple array bulge instrument (DABI) configuration, which enables parallel creep testing of 25 dimples, each fabricated from a different alloy, in a single experiment. Full-field surface displacements of dimples undergoing time-dependent creep-induced bulging under inert gas pressure are measured by 3D digital image correlation. We train a recurrent neural network (RNN) as a surrogate model, mapping creep parameters and loading conditions to the time-dependent deformation response of DABI. Coupling this surrogate with a particle swarm optimization scheme enables rapid and global inverse identification with sparsity regularization of creep parameters from experiment displacement-time histories. In addition, we propose a phenomenological creep law with a time-dependent stress exponent that captures the sigmoidal primary creep observed in wrought INCONEL 625 and extracts its temperature dependence from DABI test at multiple temperatures. Furthermore, we employ a general creep law combining several conventional forms together with regularized inversion to identify the creep laws for 47 additional Fe-, Ni-, and Co-rich alloys and to automatically select the dominant functional form for each alloy. This workflow combined with DABI experiment provides a quantitative, high-throughput creep characterization platform that is compatible with data mining, composition-property modeling, and nonlinear structural optimization with creep behavior across a large alloy design space.
When Large Language Models Do Not Work: Online Incivility Prediction through Graph Neural Networks
Dec 08, 2025Online incivility has emerged as a widespread and persistent problem in digital communities, imposing substantial social and psychological burdens on users. Although many platforms attempt to curb incivility through moderation and automated detection, the performance of existing approaches often remains limited in both accuracy and efficiency. To address this challenge, we propose a Graph Neural Network (GNN) framework for detecting three types of uncivil behavior (i.e., toxicity, aggression, and personal attacks) within the English Wikipedia community. Our model represents each user comment as a node, with textual similarity between comments defining the edges, allowing the network to jointly learn from both linguistic content and relational structures among comments. We also introduce a dynamically adjusted attention mechanism that adaptively balances nodal and topological features during information aggregation. Empirical evaluations demonstrate that our proposed architecture outperforms 12 state-of-the-art Large Language Models (LLMs) across multiple metrics while requiring significantly lower inference cost. These findings highlight the crucial role of structural context in detecting online incivility and address the limitations of text-only LLM paradigms in behavioral prediction. All datasets and comparative outputs will be publicly available in our repository to support further research and reproducibility.
Adaptive Digital Twin of Sheet Metal Forming via Proper Orthogonal Decomposition-Based Koopman Operator with Model Predictive Control
Nov 13, 2025

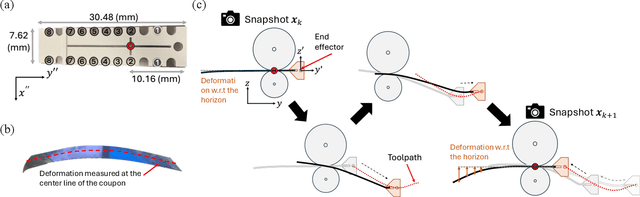
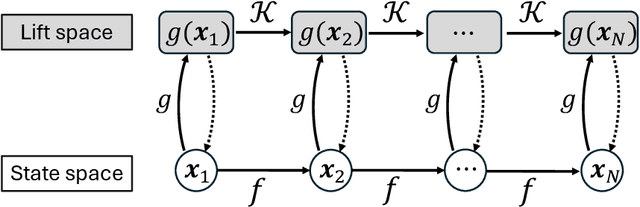
Digital Twin (DT) technologies are transforming manufacturing by enabling real-time prediction, monitoring, and control of complex processes. Yet, applying DT to deformation-based metal forming remains challenging because of the strongly coupled spatial-temporal behavior and the nonlinear relationship between toolpath and material response. For instance, sheet-metal forming by the English wheel, a highly flexible but artisan-dependent process, still lacks digital counterparts that can autonomously plan and adapt forming strategies. This study presents an adaptive DT framework that integrates Proper Orthogonal Decomposition (POD) for physics-aware dimensionality reduction with a Koopman operator for representing nonlinear system in a linear lifted space for the real-time decision-making via model predictive control (MPC). To accommodate evolving process conditions or material states, an online Recursive Least Squares (RLS) algorithm is introduced to update the operator coefficients in real time, enabling continuous adaptation of the DT model as new deformation data become available. The proposed framework is experimentally demonstrated on a robotic English Wheel sheet metal forming system, where deformation fields are measured and modeled under varying toolpaths. Results show that the adaptive DT is capable of controlling the forming process to achieve the given target shape by effectively capturing non-stationary process behaviors. Beyond this case study, the proposed framework establishes a generalizable approach for interpretable, adaptive, and computationally-efficient DT of nonlinear manufacturing systems, bridging reduced-order physics representations with data-driven adaptability to support autonomous process control and optimization.
GraphTOP: Graph Topology-Oriented Prompting for Graph Neural Networks
Oct 25, 2025Graph Neural Networks (GNNs) have revolutionized the field of graph learning by learning expressive graph representations from massive graph data. As a common pattern to train powerful GNNs, the "pre-training, adaptation" scheme first pre-trains GNNs over unlabeled graph data and subsequently adapts them to specific downstream tasks. In the adaptation phase, graph prompting is an effective strategy that modifies input graph data with learnable prompts while keeping pre-trained GNN models frozen. Typically, existing graph prompting studies mainly focus on *feature-oriented* methods that apply graph prompts to node features or hidden representations. However, these studies often achieve suboptimal performance, as they consistently overlook the potential of *topology-oriented* prompting, which adapts pre-trained GNNs by modifying the graph topology. In this study, we conduct a pioneering investigation of graph prompting in terms of graph topology. We propose the first **Graph** **T**opology-**O**riented **P**rompting (GraphTOP) framework to effectively adapt pre-trained GNN models for downstream tasks. More specifically, we reformulate topology-oriented prompting as an edge rewiring problem within multi-hop local subgraphs and relax it into the continuous probability space through reparameterization while ensuring tight relaxation and preserving graph sparsity. Extensive experiments on five graph datasets under four pre-training strategies demonstrate that our proposed GraphTOP outshines six baselines on multiple node classification datasets. Our code is available at https://github.com/xbfu/GraphTOP.
ALLabel: Three-stage Active Learning for LLM-based Entity Recognition using Demonstration Retrieval
Sep 09, 2025Many contemporary data-driven research efforts in the natural sciences, such as chemistry and materials science, require large-scale, high-performance entity recognition from scientific datasets. Large language models (LLMs) have increasingly been adopted to solve the entity recognition task, with the same trend being observed on all-spectrum NLP tasks. The prevailing entity recognition LLMs rely on fine-tuned technology, yet the fine-tuning process often incurs significant cost. To achieve a best performance-cost trade-off, we propose ALLabel, a three-stage framework designed to select the most informative and representative samples in preparing the demonstrations for LLM modeling. The annotated examples are used to construct a ground-truth retrieval corpus for LLM in-context learning. By sequentially employing three distinct active learning strategies, ALLabel consistently outperforms all baselines under the same annotation budget across three specialized domain datasets. Experimental results also demonstrate that selectively annotating only 5\%-10\% of the dataset with ALLabel can achieve performance comparable to the method annotating the entire dataset. Further analyses and ablation studies verify the effectiveness and generalizability of our proposal.