 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot all tokens contribute equally to diffusion learning
Apr 08, 2026With the rapid development of conditional diffusion models, significant progress has been made in text-to-video generation. However, we observe that these models often neglect semantically important tokens during inference, leading to biased or incomplete generations under classifier-free guidance. We attribute this issue to two key factors: distributional bias caused by the long-tailed token frequency in training data, and spatial misalignment in cross-attention where semantically important tokens are overshadowed by less informative ones. To address these issues, we propose Distribution-Aware Rectification and Spatial Ensemble (DARE), a unified framework that improves semantic guidance in diffusion models from the perspectives of distributional debiasing and spatial consistency. First, we introduce Distribution-Rectified Classifier-Free Guidance (DR-CFG), which regularizes the training process by dynamically suppressing dominant tokens with low semantic density, encouraging the model to better capture underrepresented semantic cues and learn a more balanced conditional distribution. This design mitigates the risk of the model distribution overfitting to tokens with low semantic density. Second, we propose Spatial Representation Alignment (SRA), which adaptively reweights cross-attention maps according to token importance and enforces representation consistency, enabling semantically important tokens to exert stronger spatial guidance during generation. This mechanism effectively prevents low semantic-density tokens from dominating the attention allocation, thereby avoiding the dilution of the spatial and distributional guidance provided by high semantic-density tokens. Extensive experiments on multiple benchmark datasets demonstrate that DARE consistently improves generation fidelity and semantic alignment, achieving significant gains over existing approaches.
Condition Weaving Meets Expert Modulation: Towards Universal and Controllable Image Generation
Aug 24, 2025The image-to-image generation task aims to produce controllable images by leveraging conditional inputs and prompt instructions. However, existing methods often train separate control branches for each type of condition, leading to redundant model structures and inefficient use of computational resources. To address this, we propose a Unified image-to-image Generation (UniGen) framework that supports diverse conditional inputs while enhancing generation efficiency and expressiveness. Specifically, to tackle the widely existing parameter redundancy and computational inefficiency in controllable conditional generation architectures, we propose the Condition Modulated Expert (CoMoE) module. This module aggregates semantically similar patch features and assigns them to dedicated expert modules for visual representation and conditional modeling. By enabling independent modeling of foreground features under different conditions, CoMoE effectively mitigates feature entanglement and redundant computation in multi-condition scenarios. Furthermore, to bridge the information gap between the backbone and control branches, we propose WeaveNet, a dynamic, snake-like connection mechanism that enables effective interaction between global text-level control from the backbone and fine-grained control from conditional branches. Extensive experiments on the Subjects-200K and MultiGen-20M datasets across various conditional image generation tasks demonstrate that our method consistently achieves state-of-the-art performance, validating its advantages in both versatility and effectiveness. The code has been uploaded to https://github.com/gavin-gqzhang/UniGen.
Hierarchical Feature Learning for Medical Point Clouds via State Space Model
Apr 17, 2025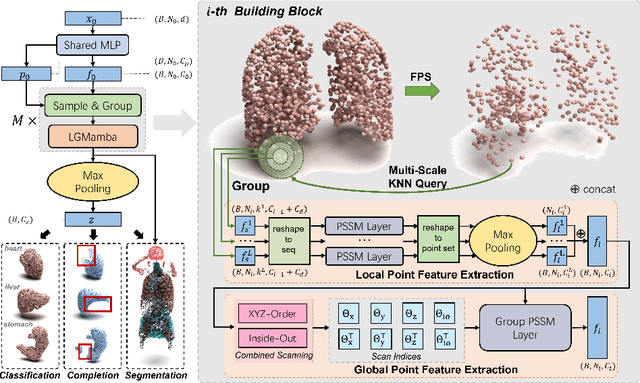



Deep learning-based point cloud modeling has been widely investigated as an indispensable component of general shape analysis. Recently, transformer and state space model (SSM) have shown promising capacities in point cloud learning. However, limited research has been conducted on medical point clouds, which have great potential in disease diagnosis and treatment. This paper presents an SSM-based hierarchical feature learning framework for medical point cloud understanding. Specifically, we down-sample input into multiple levels through the farthest point sampling. At each level, we perform a series of k-nearest neighbor (KNN) queries to aggregate multi-scale structural information. To assist SSM in processing point clouds, we introduce coordinate-order and inside-out scanning strategies for efficient serialization of irregular points. Point features are calculated progressively from short neighbor sequences and long point sequences through vanilla and group Point SSM blocks, to capture both local patterns and long-range dependencies. To evaluate the proposed method, we build a large-scale medical point cloud dataset named MedPointS for anatomy classification, completion, and segmentation. Extensive experiments conducted on MedPointS demonstrate that our method achieves superior performance across all tasks. The dataset is available at https://flemme-docs.readthedocs.io/en/latest/medpoints.html. Code is merged to a public medical imaging platform: https://github.com/wlsdzyzl/flemme.
Transfer Risk Map: Mitigating Pixel-level Negative Transfer in Medical Segmentation
Feb 04, 2025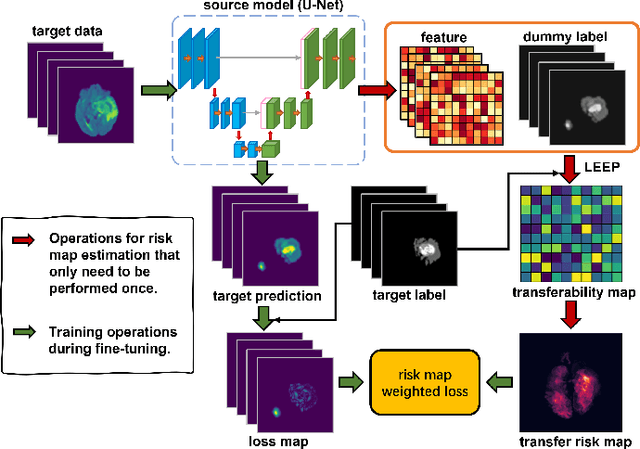



How to mitigate negative transfer in transfer learning is a long-standing and challenging issue, especially in the application of medical image segmentation. Existing methods for reducing negative transfer focus on classification or regression tasks, ignoring the non-uniform negative transfer risk in different image regions. In this work, we propose a simple yet effective weighted fine-tuning method that directs the model's attention towards regions with significant transfer risk for medical semantic segmentation. Specifically, we compute a transferability-guided transfer risk map to quantify the transfer hardness for each pixel and the potential risks of negative transfer. During the fine-tuning phase, we introduce a map-weighted loss function, normalized with image foreground size to counter class imbalance. Extensive experiments on brain segmentation datasets show our method significantly improves the target task performance, with gains of 4.37% on FeTS2021 and 1.81% on iSeg2019, avoiding negative transfer across modalities and tasks. Meanwhile, a 2.9% gain under a few-shot scenario validates the robustness of our approach.
Adapting Foundation Models for Few-Shot Medical Image Segmentation: Actively and Sequentially
Feb 03, 2025
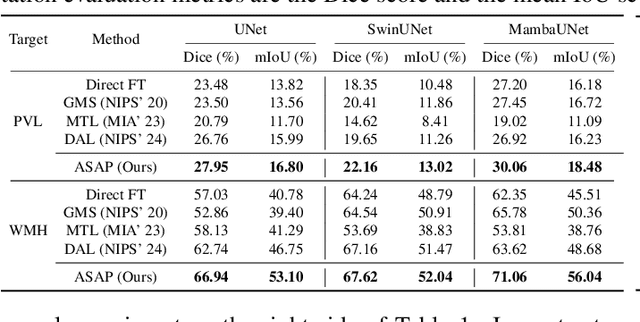


Recent advances in foundation models have brought promising results in computer vision, including medical image segmentation. Fine-tuning foundation models on specific low-resource medical tasks has become a standard practice. However, ensuring reliable and robust model adaptation when the target task has a large domain gap and few annotated samples remains a challenge. Previous few-shot domain adaptation (FSDA) methods seek to bridge the distribution gap between source and target domains by utilizing auxiliary data. The selection and scheduling of auxiliaries are often based on heuristics, which can easily cause negative transfer. In this work, we propose an Active and Sequential domain AdaPtation (ASAP) framework for dynamic auxiliary dataset selection in FSDA. We formulate FSDA as a multi-armed bandit problem and derive an efficient reward function to prioritize training on auxiliary datasets that align closely with the target task, through a single-round fine-tuning. Empirical validation on diverse medical segmentation datasets demonstrates that our method achieves favorable segmentation performance, significantly outperforming the state-of-the-art FSDA methods, achieving an average gain of 27.75% on MRI and 7.52% on CT datasets in Dice score. Code is available at the git repository: https://github.com/techicoco/ASAP.
Virtual-Work Based Shape-Force Sensing for Continuum Instruments with Tension-Feedback Actuation
Jan 09, 2025



Continuum instruments are integral to robot-assisted minimally invasive surgery (MIS), with tendon-driven mechanisms being the most common. Real-time tension feedback is crucial for precise articulation but remains a challenge in compact actuation unit designs. Additionally, accurate shape and external force sensing of continuum instruments are essential for advanced control and manipulation. This paper presents a compact and modular actuation unit that integrates a torque cell directly into the pulley module to provide real-time tension feedback. Building on this unit, we propose a novel shape-force sensing framework that incorporates polynomial curvature kinematics to accurately model non-constant curvature. The framework combines pose sensor measurements at the instrument tip and actuation tension feedback at the developed actuation unit. Experimental results demonstrate the improved performance of the proposed shape-force sensing framework in terms of shape reconstruction accuracy and force estimation reliability compared to conventional constant-curvature methods.
AI-Driven Reinvention of Hydrological Modeling for Accurate Predictions and Interpretation to Transform Earth System Modeling
Jan 07, 2025Traditional equation-driven hydrological models often struggle to accurately predict streamflow in challenging regional Earth systems like the Tibetan Plateau, while hybrid and existing algorithm-driven models face difficulties in interpreting hydrological behaviors. This work introduces HydroTrace, an algorithm-driven, data-agnostic model that substantially outperforms these approaches, achieving a Nash-Sutcliffe Efficiency of 98% and demonstrating strong generalization on unseen data. Moreover, HydroTrace leverages advanced attention mechanisms to capture spatial-temporal variations and feature-specific impacts, enabling the quantification and spatial resolution of streamflow partitioning as well as the interpretation of hydrological behaviors such as glacier-snow-streamflow interactions and monsoon dynamics. Additionally, a large language model (LLM)-based application allows users to easily understand and apply HydroTrace's insights for practical purposes. These advancements position HydroTrace as a transformative tool in hydrological and broader Earth system modeling, offering enhanced prediction accuracy and interpretability.
Optimizing Automatic Summarization of Long Clinical Records Using Dynamic Context Extension:Testing and Evaluation of the NBCE Method
Nov 14, 2024
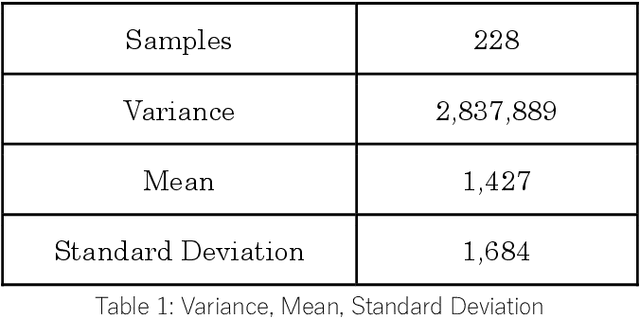
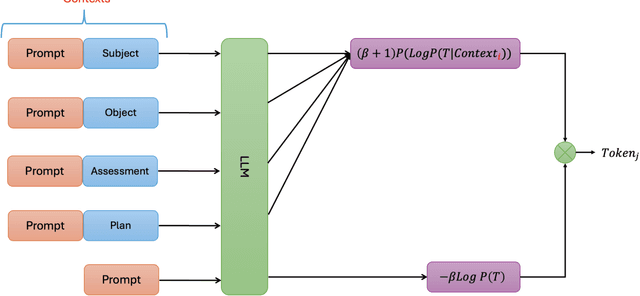
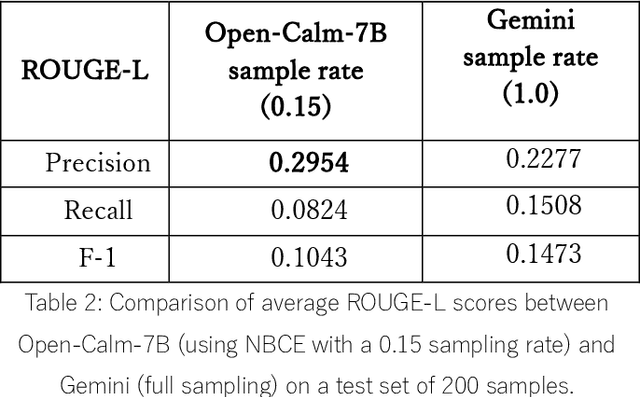
Summarizing patient clinical notes is vital for reducing documentation burdens. Current manual summarization makes medical staff struggle. We propose an automatic method using LLMs, but long inputs cause LLMs to lose context, reducing output quality especially in small size model. We used a 7B model, open-calm-7b, enhanced with Native Bayes Context Extend and a redesigned decoding mechanism to reference one sentence at a time, keeping inputs within context windows, 2048 tokens. Our improved model achieved near parity with Google's over 175B Gemini on ROUGE-L metrics with 200 samples, indicating strong performance using less resources, enhancing automated EMR summarization feasibility.
Selecting the Best Sequential Transfer Path for Medical Image Segmentation with Limited Labeled Data
Oct 09, 2024



The medical image processing field often encounters the critical issue of scarce annotated data. Transfer learning has emerged as a solution, yet how to select an adequate source task and effectively transfer the knowledge to the target task remains challenging. To address this, we propose a novel sequential transfer scheme with a task affinity metric tailored for medical images. Considering the characteristics of medical image segmentation tasks, we analyze the image and label similarity between tasks and compute the task affinity scores, which assess the relatedness among tasks. Based on this, we select appropriate source tasks and develop an effective sequential transfer strategy by incorporating intermediate source tasks to gradually narrow the domain discrepancy and minimize the transfer cost. Thereby we identify the best sequential transfer path for the given target task. Extensive experiments on three MRI medical datasets, FeTS 2022, iSeg-2019, and WMH, demonstrate the efficacy of our method in finding the best source sequence. Compared with directly transferring from a single source task, the sequential transfer results underline a significant improvement in target task performance, achieving an average of 2.58% gain in terms of segmentation Dice score, notably, 6.00% for FeTS 2022. Code is available at the git repository.
Vision Transformer based Random Walk for Group Re-Identification
Oct 08, 2024



Group re-identification (re-ID) aims to match groups with the same people under different cameras, mainly involves the challenges of group members and layout changes well. Most existing methods usually use the k-nearest neighbor algorithm to update node features to consider changes in group membership, but these methods cannot solve the problem of group layout changes. To this end, we propose a novel vision transformer based random walk framework for group re-ID. Specifically, we design a vision transformer based on a monocular depth estimation algorithm to construct a graph through the average depth value of pedestrian features to fully consider the impact of camera distance on group members relationships. In addition, we propose a random walk module to reconstruct the graph by calculating affinity scores between target and gallery images to remove pedestrians who do not belong to the current group. Experimental results show that our framework is superior to most methods.