 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Real Image Dehazing using YCbCr Color Space
Dec 24, 2024



Image dehazing, particularly with learning-based methods, has gained significant attention due to its importance in real-world applications. However, relying solely on the RGB color space often fall short, frequently leaving residual haze. This arises from two main issues: the difficulty in obtaining clear textural features from hazy RGB images and the complexity of acquiring real haze/clean image pairs outside controlled environments like smoke-filled scenes. To address these issues, we first propose a novel Structure Guided Dehazing Network (SGDN) that leverages the superior structural properties of YCbCr features over RGB. It comprises two key modules: Bi-Color Guidance Bridge (BGB) and Color Enhancement Module (CEM). BGB integrates a phase integration module and an interactive attention module, utilizing the rich texture features of the YCbCr space to guide the RGB space, thereby recovering clearer features in both frequency and spatial domains. To maintain tonal consistency, CEM further enhances the color perception of RGB features by aggregating YCbCr channel information. Furthermore, for effective supervised learning, we introduce a Real-World Well-Aligned Haze (RW$^2$AH) dataset, which includes a diverse range of scenes from various geographical regions and climate conditions. Experimental results demonstrate that our method surpasses existing state-of-the-art methods across multiple real-world smoke/haze datasets. Code and Dataset: \textcolor{blue}{\url{https://github.com/fiwy0527/AAAI25_SGDN.}}
Vision Transformer based Random Walk for Group Re-Identification
Oct 08, 2024



Group re-identification (re-ID) aims to match groups with the same people under different cameras, mainly involves the challenges of group members and layout changes well. Most existing methods usually use the k-nearest neighbor algorithm to update node features to consider changes in group membership, but these methods cannot solve the problem of group layout changes. To this end, we propose a novel vision transformer based random walk framework for group re-ID. Specifically, we design a vision transformer based on a monocular depth estimation algorithm to construct a graph through the average depth value of pedestrian features to fully consider the impact of camera distance on group members relationships. In addition, we propose a random walk module to reconstruct the graph by calculating affinity scores between target and gallery images to remove pedestrians who do not belong to the current group. Experimental results show that our framework is superior to most methods.
A Novel Dual-Stage Evolutionary Algorithm for Finding Robust Solutions
Jan 02, 2024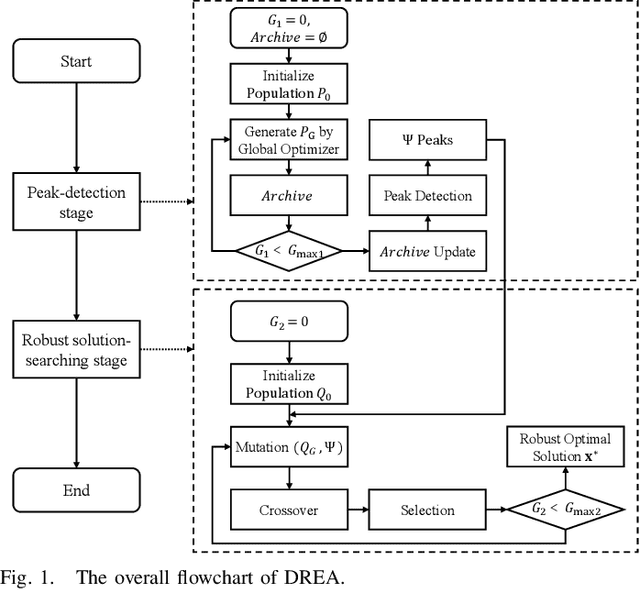
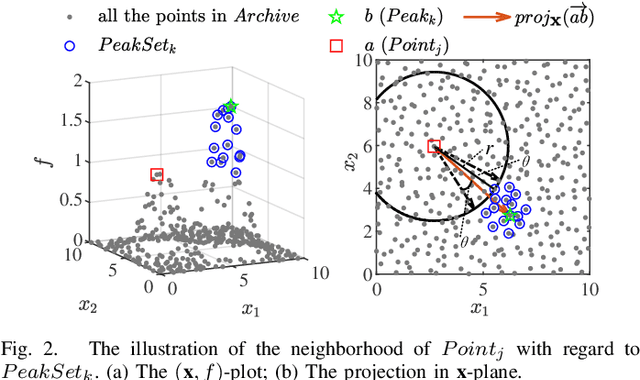


In robust optimization problems, the magnitude of perturbations is relatively small. Consequently, solutions within certain regions are less likely to represent the robust optima when perturbations are introduced. Hence, a more efficient search process would benefit from increased opportunities to explore promising regions where global optima or good local optima are situated. In this paper, we introduce a novel robust evolutionary algorithm named the dual-stage robust evolutionary algorithm (DREA) aimed at discovering robust solutions. DREA operates in two stages: the peak-detection stage and the robust solution-searching stage. The primary objective of the peak-detection stage is to identify peaks in the fitness landscape of the original optimization problem. Conversely, the robust solution-searching stage focuses on swiftly identifying the robust optimal solution using information obtained from the peaks discovered in the initial stage. These two stages collectively enable the proposed DREA to efficiently obtain the robust optimal solution for the optimization problem. This approach achieves a balance between solution optimality and robustness by separating the search processes for optimal and robust optimal solutions. Experimental results demonstrate that DREA significantly outperforms five state-of-the-art algorithms across 18 test problems characterized by diverse complexities. Moreover, when evaluated on higher-dimensional robust optimization problems (100-$D$ and 200-$D$), DREA also demonstrates superior performance compared to all five counterpart algorithms.
Adversarial Learning of Hard Positives for Place Recognition
May 08, 2022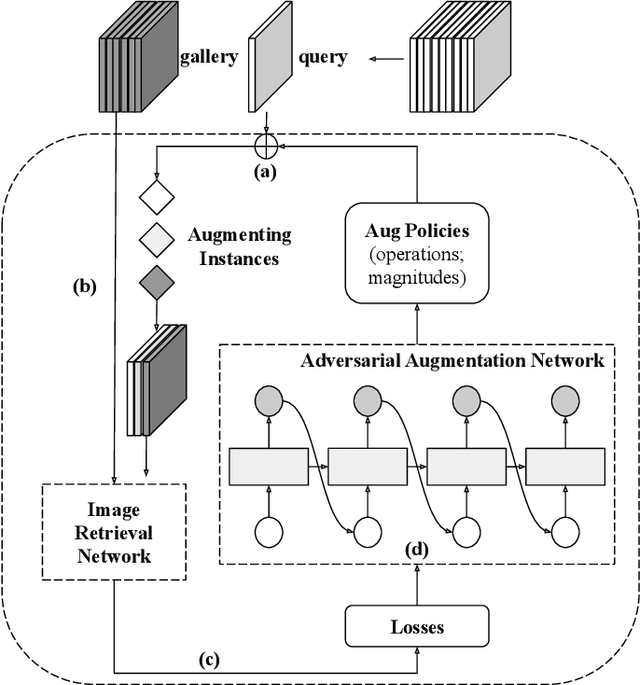
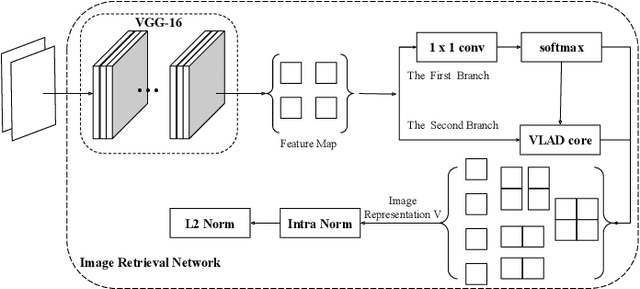

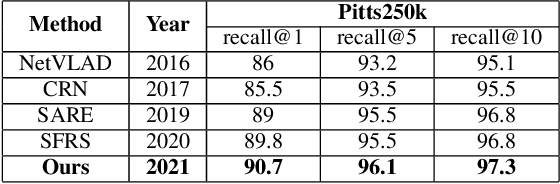
Image retrieval methods for place recognition learn global image descriptors that are used for fetching geo-tagged images at inference time. Recent works have suggested employing weak and self-supervision for mining hard positives and hard negatives in order to improve localization accuracy and robustness to visibility changes (e.g. in illumination or view point). However, generating hard positives, which is essential for obtaining robustness, is still limited to hard-coded or global augmentations. In this work we propose an adversarial method to guide the creation of hard positives for training image retrieval networks. Our method learns local and global augmentation policies which will increase the training loss, while the image retrieval network is forced to learn more powerful features for discriminating increasingly difficult examples. This approach allows the image retrieval network to generalize beyond the hard examples presented in the data and learn features that are robust to a wide range of variations. Our method achieves state-of-the-art recalls on the Pitts250 and Tokyo 24/7 benchmarks and outperforms recent image retrieval methods on the rOxford and rParis datasets by a noticeable margin.