 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoteZero: Geospatial Reasoning with Zero Human Annotations
May 06, 2026Geospatial reasoning requires models to resolve complex spatial semantics and user intent into precise target locations for Earth observation. Recent progress has liberated the reasoning path from manual curation, allowing models to generate their own inference chains. Yet a final dependency remains: they are still supervised by human-annotated ground-truth coordinates. This leaves the reasoning process autonomous, but not its spatial endpoint, and prevents true self-evolution on abundant unlabeled remote sensing data. To break this bottleneck, we introduce RemoteZero, a box-supervision-free framework for geospatial reasoning. RemoteZero is motivated by a simple asymmetry: an MLLM is typically better at verifying whether a region satisfies a query than at directly generating precise coordinates. Leveraging this stronger discriminative ability, RemoteZero replaces geometric supervision with intrinsic semantic verification and enables GRPO training without box annotations. The resulting framework further supports iterative self-evolution, allowing the model to improve from unlabeled remote sensing imagery through its own verification signal. Experiments show that RemoteZero achieves competitive performance against strong supervised methods, demonstrating the potential of self-verifying training for geospatial reasoning localization.
Are VLMs Lost Between Sky and Space? LinkS$^2$Bench for UAV-Satellite Dynamic Cross-View Spatial Intelligence
Apr 02, 2026Synergistic spatial intelligence between UAVs and satellites is indispensable for emergency response and security operations, as it uniquely integrates macro-scale global coverage with dynamic, real-time local perception. However, the capacity of Vision-Language Models (VLMs) to master this complex interplay remains largely unexplored. This gap persists primarily because existing benchmarks are confined to isolated Unmanned Aerial Vehicle (UAV) videos or static satellite imagery, failing to evaluate the dynamic local-to-global spatial mapping essential for comprehensive cross-view reasoning. To bridge this gap, we introduce LinkS$^2$Bench, the first comprehensive benchmark designed to evaluate VLMs' wide-area, dynamic cross-view spatial intelligence. LinkS$^2$Bench links 1,022 minutes of dynamic UAV footage with high-resolution satellite imagery covering over 200 km$^2$. Through an LMM-assisted pipeline and rigorous human annotation, we constructed 17.9k high-quality question-answer pairs comprising 12 fine-grained tasks across four dimensions: perception, localization, relation, and reasoning. Evaluations of 18 representative VLMs reveal a substantial gap compared to human baselines, identifying accurate cross-view dynamic alignment as the critical bottleneck. To alleviate this, we design a Cross-View Alignment Adapter, demonstrating that explicit alignment significantly improves model performance. Furthermore, fine-tuning experiments underscore the potential of LinkS$^2$Bench in advancing VLM adaptation for complex spatial reasoning.
A3R: Agentic Affordance Reasoning via Cross-Dimensional Evidence in 3D Gaussian Scenes
Apr 02, 2026Affordance reasoning in 3D Gaussian scenes aims to identify the region that supports the action specified by a given text instruction in complex environments. Existing methods typically cast this problem as one-shot prediction from static scene observations, assuming sufficient evidence is already available for reasoning. However, in complex 3D scenes, many failure cases arise not from weak prediction capacity, but from incomplete task-relevant evidence under fixed observations. To address this limitation, we reformulate fine-grained affordance reasoning as a sequential evidence acquisition process, where ambiguity is progressively reduced through complementary 3D geometric and 2D semantic evidence. Building on this formulation, we propose A3R, an agentic affordance reasoning framework that enables an MLLM-based policy to iteratively select evidence acquisition actions and update the affordance belief through cross-dimensional evidence acquisition. To optimize such sequential decision making, we further introduce a GRPO-based policy learning strategy that improves evidence acquisition efficiency and reasoning accuracy. Extensive experiments on scene-level benchmarks show that A3R consistently surpasses static one-shot baselines, demonstrating the advantage of agentic cross-dimensional evidence acquisition for fine-grained affordance reasoning in complex 3D Gaussian scenes.
Explore Intrinsic Geometry for Query-based Tiny and Oriented Object Detector with Momentum-based Bipartite Matching
Feb 14, 2026Recent query-based detectors have achieved remarkable progress, yet their performance remains constrained when handling objects with arbitrary orientations, especially for tiny objects capturing limited texture information. This limitation primarily stems from the underutilization of intrinsic geometry during pixel-based feature decoding and the occurrence of inter-stage matching inconsistency caused by stage-wise bipartite matching. To tackle these challenges, we present IGOFormer, a novel query-based oriented object detector that explicitly integrates intrinsic geometry into feature decoding and enhances inter-stage matching stability. Specifically, we design an Intrinsic Geometry-aware Decoder, which enhances the object-related features conditioned on an object query by injecting complementary geometric embeddings extrapolated from their correlations to capture the geometric layout of the object, thereby offering a critical geometric insight into its orientation. Meanwhile, a Momentum-based Bipartite Matching scheme is developed to adaptively aggregate historical matching costs by formulating an exponential moving average with query-specific smoothing factors, effectively preventing conflicting supervisory signals arising from inter-stage matching inconsistency. Extensive experiments and ablation studies demonstrate the superiority of our IGOFormer for aerial oriented object detection, achieving an AP$_{50}$ score of 78.00\% on DOTA-V1.0 using Swin-T backbone under the single-scale setting. The code will be made publicly available.
Learning Brain Representation with Hierarchical Visual Embeddings
Feb 07, 2026Decoding visual representations from brain signals has attracted significant attention in both neuroscience and artificial intelligence. However, the degree to which brain signals truly encode visual information remains unclear. Current visual decoding approaches explore various brain-image alignment strategies, yet most emphasize high-level semantic features while neglecting pixel-level details, thereby limiting our understanding of the human visual system. In this paper, we propose a brain-image alignment strategy that leverages multiple pre-trained visual encoders with distinct inductive biases to capture hierarchical and multi-scale visual representations, while employing a contrastive learning objective to achieve effective alignment between brain signals and visual embeddings. Furthermore, we introduce a Fusion Prior, which learns a stable mapping on large-scale visual data and subsequently matches brain features to this pre-trained prior, thereby enhancing distributional consistency across modalities. Extensive quantitative and qualitative experiments demonstrate that our method achieves a favorable balance between retrieval accuracy and reconstruction fidelity.
Disentangle Object and Non-object Infrared Features via Language Guidance
Jan 14, 2026Infrared object detection focuses on identifying and locating objects in complex environments (\eg, dark, snow, and rain) where visible imaging cameras are disabled by poor illumination. However, due to low contrast and weak edge information in infrared images, it is challenging to extract discriminative object features for robust detection. To deal with this issue, we propose a novel vision-language representation learning paradigm for infrared object detection. An additional textual supervision with rich semantic information is explored to guide the disentanglement of object and non-object features. Specifically, we propose a Semantic Feature Alignment (SFA) module to align the object features with the corresponding text features. Furthermore, we develop an Object Feature Disentanglement (OFD) module that disentangles text-aligned object features and non-object features by minimizing their correlation. Finally, the disentangled object features are entered into the detection head. In this manner, the detection performance can be remarkably enhanced via more discriminative and less noisy features. Extensive experimental results demonstrate that our approach achieves superior performance on two benchmarks: M\textsuperscript{3}FD (83.7\% mAP), FLIR (86.1\% mAP). Our code will be publicly available once the paper is accepted.
RAC-DMVC: Reliability-Aware Contrastive Deep Multi-View Clustering under Multi-Source Noise
Nov 17, 2025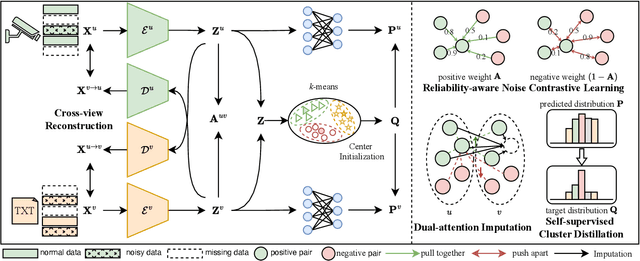
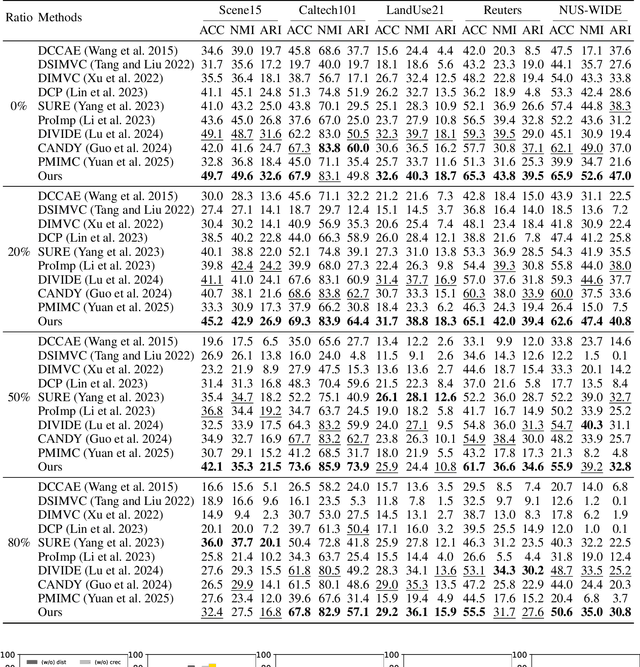

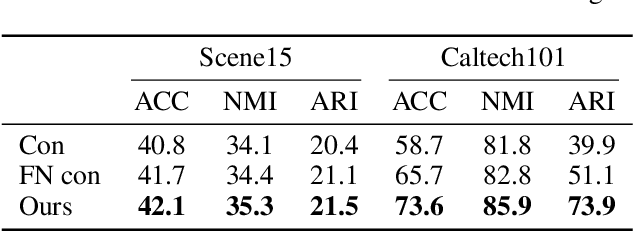
Multi-view clustering (MVC), which aims to separate the multi-view data into distinct clusters in an unsupervised manner, is a fundamental yet challenging task. To enhance its applicability in real-world scenarios, this paper addresses a more challenging task: MVC under multi-source noises, including missing noise and observation noise. To this end, we propose a novel framework, Reliability-Aware Contrastive Deep Multi-View Clustering (RAC-DMVC), which constructs a reliability graph to guide robust representation learning under noisy environments. Specifically, to address observation noise, we introduce a cross-view reconstruction to enhances robustness at the data level, and a reliability-aware noise contrastive learning to mitigates bias in positive and negative pairs selection caused by noisy representations. To handle missing noise, we design a dual-attention imputation to capture shared information across views while preserving view-specific features. In addition, a self-supervised cluster distillation module further refines the learned representations and improves the clustering performance. Extensive experiments on five benchmark datasets demonstrate that RAC-DMVC outperforms SOTA methods on multiple evaluation metrics and maintains excellent performance under varying ratios of noise.
Center-Oriented Prototype Contrastive Clustering
Aug 21, 2025Contrastive learning is widely used in clustering tasks due to its discriminative representation. However, the conflict problem between classes is difficult to solve effectively. Existing methods try to solve this problem through prototype contrast, but there is a deviation between the calculation of hard prototypes and the true cluster center. To address this problem, we propose a center-oriented prototype contrastive clustering framework, which consists of a soft prototype contrastive module and a dual consistency learning module. In short, the soft prototype contrastive module uses the probability that the sample belongs to the cluster center as a weight to calculate the prototype of each category, while avoiding inter-class conflicts and reducing prototype drift. The dual consistency learning module aligns different transformations of the same sample and the neighborhoods of different samples respectively, ensuring that the features have transformation-invariant semantic information and compact intra-cluster distribution, while providing reliable guarantees for the calculation of prototypes. Extensive experiments on five datasets show that the proposed method is effective compared to the SOTA. Our code is published on https://github.com/LouisDong95/CPCC.
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Jul 31, 20253D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.
Chain-of-Talkers (CoTalk): Fast Human Annotation of Dense Image Captions
May 28, 2025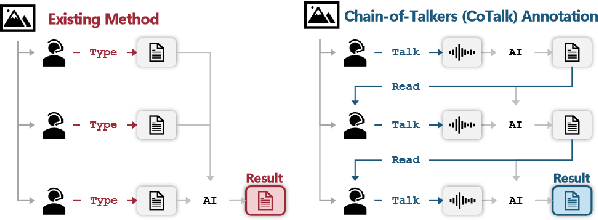

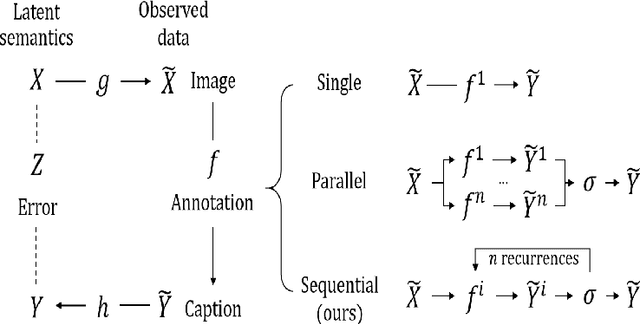
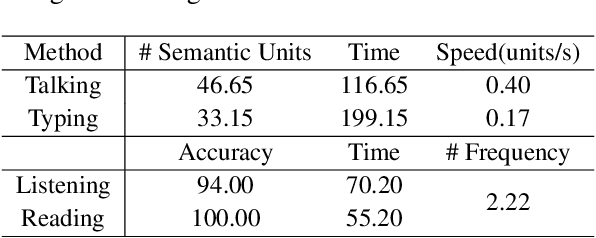
While densely annotated image captions significantly facilitate the learning of robust vision-language alignment, methodologies for systematically optimizing human annotation efforts remain underexplored. We introduce Chain-of-Talkers (CoTalk), an AI-in-the-loop methodology designed to maximize the number of annotated samples and improve their comprehensiveness under fixed budget constraints (e.g., total human annotation time). The framework is built upon two key insights. First, sequential annotation reduces redundant workload compared to conventional parallel annotation, as subsequent annotators only need to annotate the ``residual'' -- the missing visual information that previous annotations have not covered. Second, humans process textual input faster by reading while outputting annotations with much higher throughput via talking; thus a multimodal interface enables optimized efficiency. We evaluate our framework from two aspects: intrinsic evaluations that assess the comprehensiveness of semantic units, obtained by parsing detailed captions into object-attribute trees and analyzing their effective connections; extrinsic evaluation measures the practical usage of the annotated captions in facilitating vision-language alignment. Experiments with eight participants show our Chain-of-Talkers (CoTalk) improves annotation speed (0.42 vs. 0.30 units/sec) and retrieval performance (41.13\% vs. 40.52\%) over the parallel method.