 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-World Co-Salient Object Detection with Generative Uncertainty-aware Group Selective Exchange-Masking
Oct 16, 2023The traditional definition of co-salient object detection (CoSOD) task is to segment the common salient objects in a group of relevant images. This definition is based on an assumption of group consensus consistency that is not always reasonable in the open-world setting, which results in robustness issue in the model when dealing with irrelevant images in the inputting image group under the open-word scenarios. To tackle this problem, we introduce a group selective exchange-masking (GSEM) approach for enhancing the robustness of the CoSOD model. GSEM takes two groups of images as input, each containing different types of salient objects. Based on the mixed metric we designed, GSEM selects a subset of images from each group using a novel learning-based strategy, then the selected images are exchanged. To simultaneously consider the uncertainty introduced by irrelevant images and the consensus features of the remaining relevant images in the group, we designed a latent variable generator branch and CoSOD transformer branch. The former is composed of a vector quantised-variational autoencoder to generate stochastic global variables that model uncertainty. The latter is designed to capture correlation-based local features that include group consensus. Finally, the outputs of the two branches are merged and passed to a transformer-based decoder to generate robust predictions. Taking into account that there are currently no benchmark datasets specifically designed for open-world scenarios, we constructed three open-world benchmark datasets, namely OWCoSal, OWCoSOD, and OWCoCA, based on existing datasets. By breaking the group-consistency assumption, these datasets provide effective simulations of real-world scenarios and can better evaluate the robustness and practicality of models.
Video Saliency Prediction Using Enhanced Spatiotemporal Alignment Network
Jan 02, 2020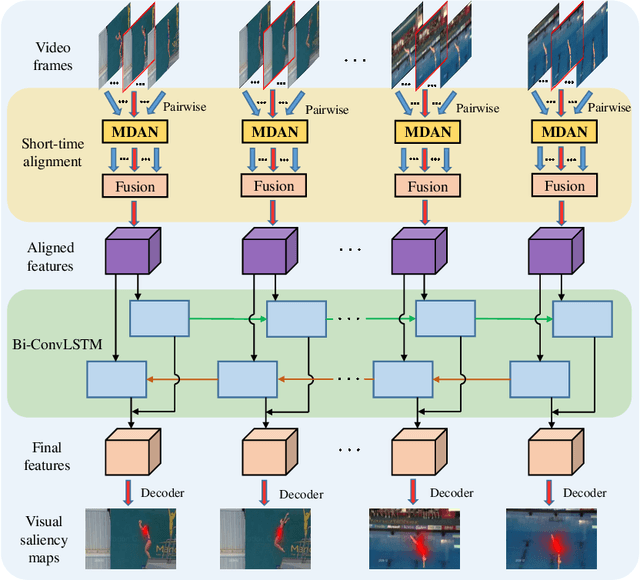
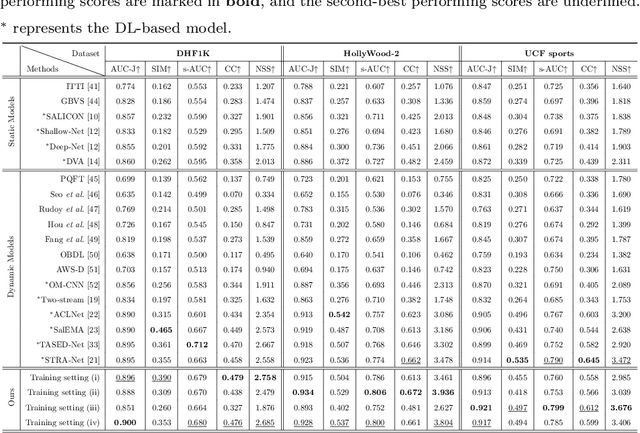
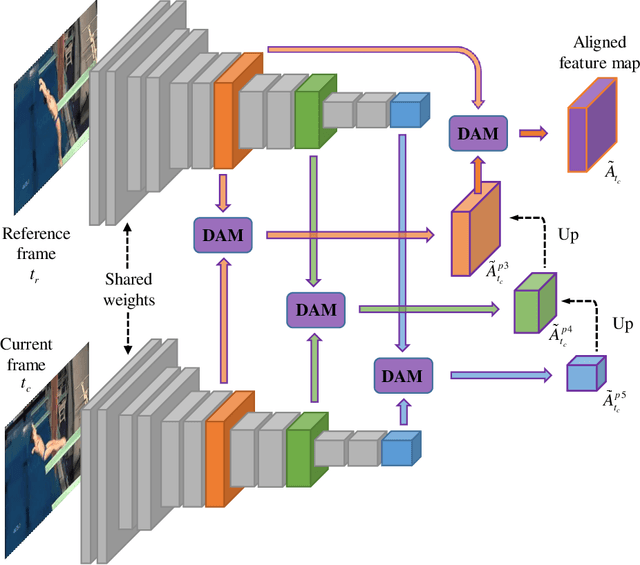
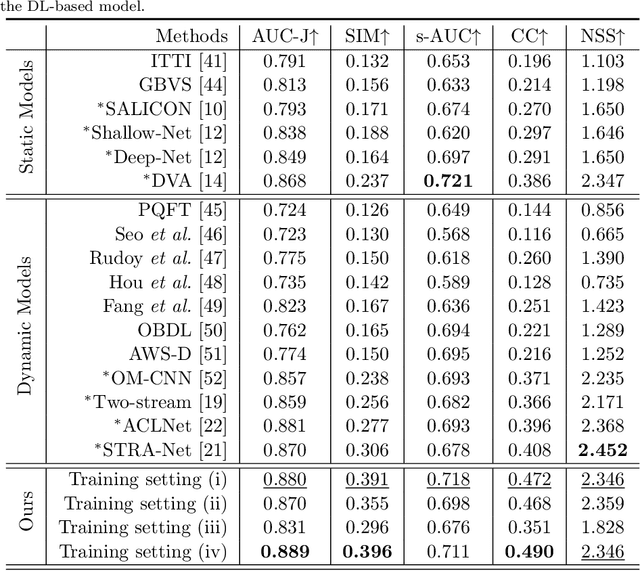
Due to a variety of motions across different frames, it is highly challenging to learn an effective spatiotemporal representation for accurate video saliency prediction (VSP). To address this issue, we develop an effective spatiotemporal feature alignment network tailored to VSP, mainly including two key sub-networks: a multi-scale deformable convolutional alignment network (MDAN) and a bidirectional convolutional Long Short-Term Memory (Bi-ConvLSTM) network. The MDAN learns to align the features of the neighboring frames to the reference one in a coarse-to-fine manner, which can well handle various motions. Specifically, the MDAN owns a pyramidal feature hierarchy structure that first leverages deformable convolution (Dconv) to align the lower-resolution features across frames, and then aggregates the aligned features to align the higher-resolution features, progressively enhancing the features from top to bottom. The output of MDAN is then fed into the Bi-ConvLSTM for further enhancement, which captures the useful long-time temporal information along forward and backward timing directions to effectively guide attention orientation shift prediction under complex scene transformation. Finally, the enhanced features are decoded to generate the predicted saliency map. The proposed model is trained end-to-end without any intricate post processing. Extensive evaluations on four VSP benchmark datasets demonstrate that the proposed method achieves favorable performance against state-of-the-art methods. The source codes and all the results will be released.
An Efficient Algorithm for the Piecewise-Smooth Model with Approximately Explicit Solutions
Dec 08, 2016

This paper presents an efficient approach to image segmentation that approximates the piecewise-smooth (PS) functional in [12] with explicit solutions. By rendering some rational constraints on the initial conditions and the final solutions of the PS functional, we propose two novel formulations which can be approximated to be the explicit solutions of the evolution partial differential equations (PDEs) of the PS model, in which only one PDE needs to be solved efficiently. Furthermore, an energy term that regularizes the level set function to be a signed distance function is incorporated into our evolution formulation, and the time-consuming re-initialization is avoided. Experiments on synthetic and real images show that our method is more efficient than both the PS model and the local binary fitting (LBF) model [4], while having similar segmentation accuracy as the LBF model.
Learning Multi-Scale Deep Features for High-Resolution Satellite Image Classification
Nov 11, 2016

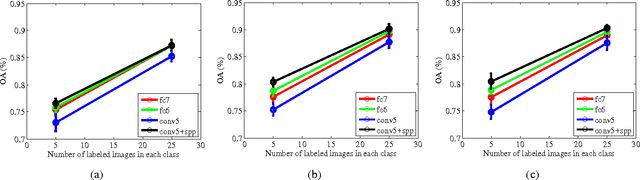
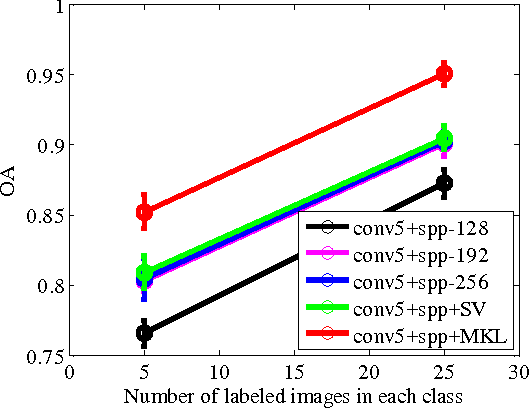
In this paper, we propose a multi-scale deep feature learning method for high-resolution satellite image classification. Specifically, we firstly warp the original satellite image into multiple different scales. The images in each scale are employed to train a deep convolutional neural network (DCNN). However, simultaneously training multiple DCNNs is time-consuming. To address this issue, we explore DCNN with spatial pyramid pooling (SPP-net). Since different SPP-nets have the same number of parameters, which share the identical initial values, and only fine-tuning the parameters in fully-connected layers ensures the effectiveness of each network, thereby greatly accelerating the training process. Then, the multi-scale satellite images are fed into their corresponding SPP-nets respectively to extract multi-scale deep features. Finally, a multiple kernel learning method is developed to automatically learn the optimal combination of such features. Experiments on two difficult datasets show that the proposed method achieves favorable performance compared to other state-of-the-art methods.
Adaptive Deep Pyramid Matching for Remote Sensing Scene Classification
Nov 11, 2016
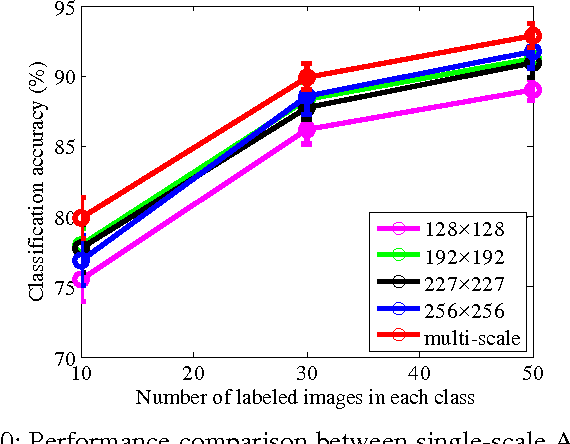
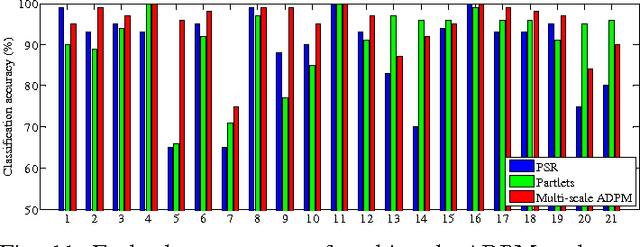

Convolutional neural networks (CNNs) have attracted increasing attention in the remote sensing community. Most CNNs only take the last fully-connected layers as features for the classification of remotely sensed images, discarding the other convolutional layer features which may also be helpful for classification purposes. In this paper, we propose a new adaptive deep pyramid matching (ADPM) model that takes advantage of the features from all of the convolutional layers for remote sensing image classification. To this end, the optimal fusing weights for different convolutional layers are learned from the data itself. In remotely sensed scenes, the objects of interest exhibit different scales in distinct scenes, and even a single scene may contain objects with different sizes. To address this issue, we select the CNN with spatial pyramid pooling (SPP-net) as the basic deep network, and further construct a multi-scale ADPM model to learn complementary information from multi-scale images. Our experiments have been conducted using two widely used remote sensing image databases, and the results show that the proposed method significantly improves the performance when compared to other state-of-the-art methods.
Re-initialization Free Level Set Evolution via Reaction Diffusion
Aug 08, 2012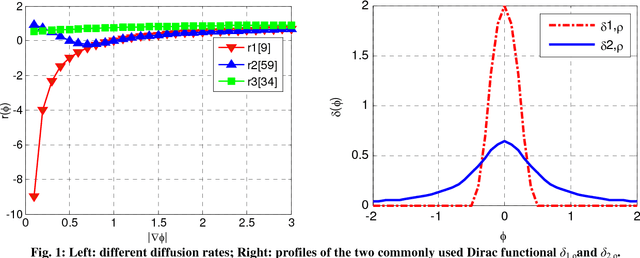
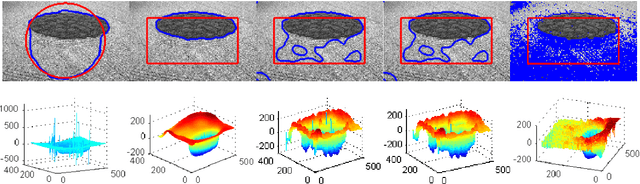

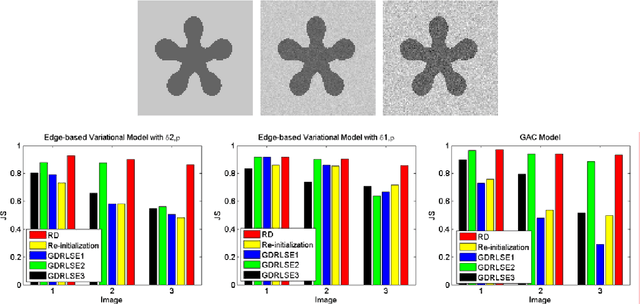
This paper presents a novel reaction-diffusion (RD) method for implicit active contours, which is completely free of the costly re-initialization procedure in level set evolution (LSE). A diffusion term is introduced into LSE, resulting in a RD-LSE equation, to which a piecewise constant solution can be derived. In order to have a stable numerical solution of the RD based LSE, we propose a two-step splitting method (TSSM) to iteratively solve the RD-LSE equation: first iterating the LSE equation, and then solving the diffusion equation. The second step regularizes the level set function obtained in the first step to ensure stability, and thus the complex and costly re-initialization procedure is completely eliminated from LSE. By successfully applying diffusion to LSE, the RD-LSE model is stable by means of the simple finite difference method, which is very easy to implement. The proposed RD method can be generalized to solve the LSE for both variational level set method and PDE-based level set method. The RD-LSE method shows very good performance on boundary anti-leakage, and it can be readily extended to high dimensional level set method. The extensive and promising experimental results on synthetic and real images validate the effectiveness of the proposed RD-LSE approach.