 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Saliency Prediction Using Enhanced Spatiotemporal Alignment Network
Paper and Code
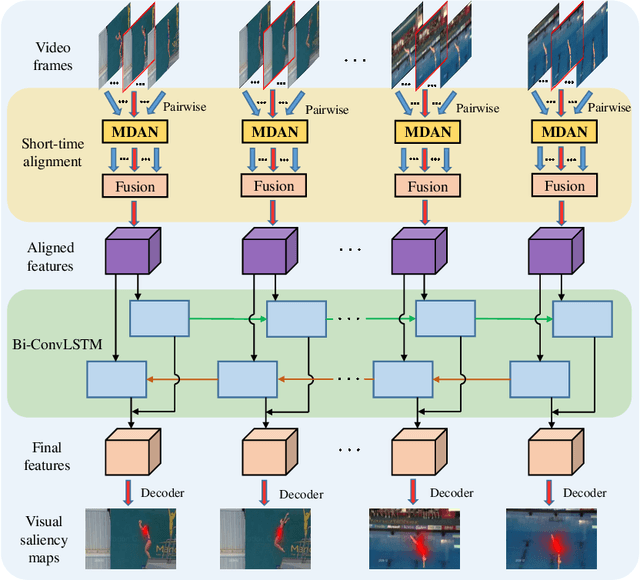
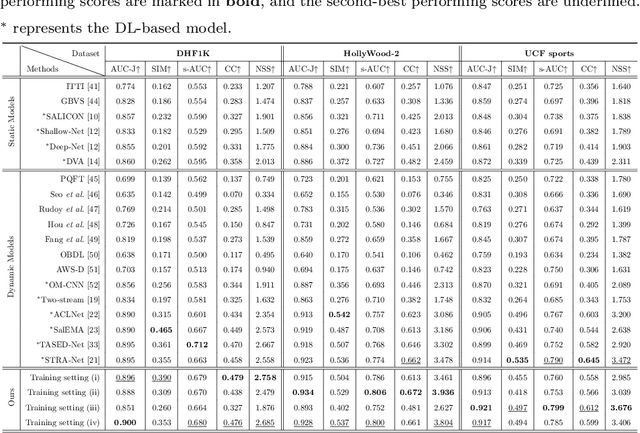
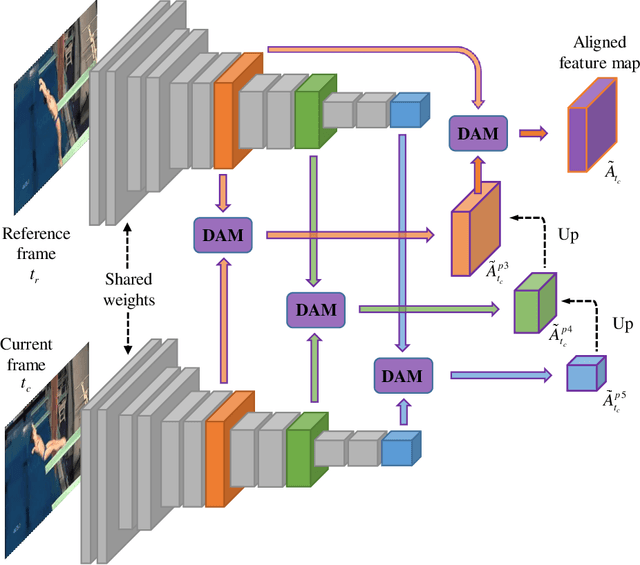
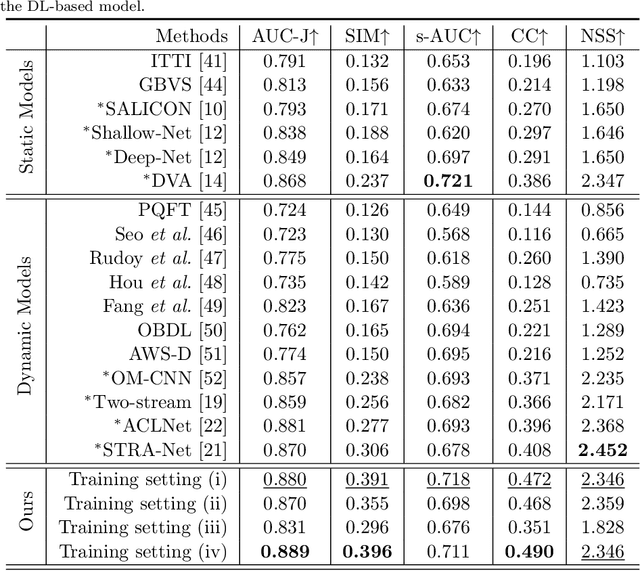
Due to a variety of motions across different frames, it is highly challenging to learn an effective spatiotemporal representation for accurate video saliency prediction (VSP). To address this issue, we develop an effective spatiotemporal feature alignment network tailored to VSP, mainly including two key sub-networks: a multi-scale deformable convolutional alignment network (MDAN) and a bidirectional convolutional Long Short-Term Memory (Bi-ConvLSTM) network. The MDAN learns to align the features of the neighboring frames to the reference one in a coarse-to-fine manner, which can well handle various motions. Specifically, the MDAN owns a pyramidal feature hierarchy structure that first leverages deformable convolution (Dconv) to align the lower-resolution features across frames, and then aggregates the aligned features to align the higher-resolution features, progressively enhancing the features from top to bottom. The output of MDAN is then fed into the Bi-ConvLSTM for further enhancement, which captures the useful long-time temporal information along forward and backward timing directions to effectively guide attention orientation shift prediction under complex scene transformation. Finally, the enhanced features are decoded to generate the predicted saliency map. The proposed model is trained end-to-end without any intricate post processing. Extensive evaluations on four VSP benchmark datasets demonstrate that the proposed method achieves favorable performance against state-of-the-art methods. The source codes and all the results will be released.