 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Points Are Equal: Uncertainty-Aware 4D LiDAR Scene Synthesis
Jun 01, 2026Constructing faithful 4D worlds from LiDAR-acquired sequences is crucial for embodied AI, yet current generative frameworks apply uniform modeling capacity across all spatial regions. This ignores that perceptual difficulty varies dramatically within a single scan: distant surfaces, occluded boundaries, and small-scale objects carry far higher uncertainty than well-observed structures. We present U4D, a new framework that explicitly leverages spatial uncertainty to guide LiDAR scene generation in a "hard-to-easy" schedule. U4D derives per-point uncertainty maps via Shannon Entropy from a pretrained segmentor, then applies an unconditional diffusion stage to synthesize high-entropy areas with precise geometry, followed by a conditional completion stage that fills in the remaining regions using these structures as priors. A MoST (Mixture of Spatio-Temporal) block further maintains cross-frame coherence by dynamically balancing spatial detail and temporal continuity. Extensive experiments on nuScenes and SemanticKITTI demonstrate state-of-the-art scene fidelity, temporal consistency, and downstream performance.
MemPro: Agentic Memory Systems as Evolvable Programs
May 30, 2026Long-horizon autonomous agents require memory systems to retain historical information, track evolving states, and reuse relevant knowledge beyond finite context windows. Existing agentic memory systems typically follow a memory construction-retrieval (MCR) pipeline, but often adapt mainly the memory bank while keeping the surrounding pipeline fixed after deployment. This fixed-pipeline design struggles to handle heterogeneous task-specific failure modes and can become misaligned with memory banks that evolve in scale and structure over time. To address these limitations, we propose MemPro, a system-level evolution framework that treats the entire MCR pipeline as an evolvable program rather than adapting only the memory bank or prompt text. MemPro maintains a version tree of runnable memory-system implementations, where an Evolving Agent iteratively selects promising versions, diagnoses recurring failures, and creates improved child versions through failure-mode-guided edit-debug refinement. Experiments on LongMemEval, LoCoMo, HotpotQA, and NarrativeQA show that MemPro consistently outperforms strong static and prompt-level evolving baselines within a few iterations, continues to improve with evolution, and achieves a favorable performance-cost trade-off. Code is available at https://github.com/wanghai673/MemPro.
CycloneMAE: A Scalable Multi-Task Learning Model for Global Tropical Cyclone Probabilistic Forecasting
Apr 14, 2026Tropical cyclones (TCs) rank among the most destructive natural hazards, yet their forecasting faces fundamental trade-offs: numerical weather prediction (NWP) models are computationally prohibitive and struggle to leverage historical data, while existing deep learning (DL)-based intelligent models are variable-specific and deterministic, which fail to generalize across different forecasting variables. Here we present CycloneMAE, a scalable multi-task forecasting model that learns transferable TC representations from multi-modal data using a TC structure-aware masked autoencoder. By coupling a discrete probabilistic gridding mechanism with a pre-train/fine-tune paradigm, CycloneMAE simultaneously delivers deterministic forecasts and probability distributions. Evaluated across five global ocean basins, CycloneMAE outperforms leading NWP systems in pressure and wind forecasting up to 120 hours and in track forecasting up to 24 hours. Attribution analysis via integrated gradients reveals physically interpretable learning dynamics: short-term forecasts rely predominantly on the internal core convective structure from satellite imagery, whereas longer-term forecasts progressively shift attention to external environmental factors. Our framework establishes a scalable, probabilistic, and interpretable pathway for operational TC forecasting.
Unlocking Prototype Potential: An Efficient Tuning Framework for Few-Shot Class-Incremental Learning
Feb 05, 2026Few-shot class-incremental learning (FSCIL) seeks to continuously learn new classes from very limited samples while preserving previously acquired knowledge. Traditional methods often utilize a frozen pre-trained feature extractor to generate static class prototypes, which suffer from the inherent representation bias of the backbone. While recent prompt-based tuning methods attempt to adapt the backbone via minimal parameter updates, given the constraint of extreme data scarcity, the model's capacity to assimilate novel information and substantively enhance its global discriminative power is inherently limited. In this paper, we propose a novel shift in perspective: freezing the feature extractor while fine-tuning the prototypes. We argue that the primary challenge in FSCIL is not feature acquisition, but rather the optimization of decision regions within a static, high-quality feature space. To this end, we introduce an efficient prototype fine-tuning framework that evolves static centroids into dynamic, learnable components. The framework employs a dual-calibration method consisting of class-specific and task-aware offsets. These components function synergistically to improve the discriminative capacity of prototypes for ongoing incremental classes. Extensive results demonstrate that our method attains superior performance across multiple benchmarks while requiring minimal learnable parameters.
Teaching Prompts to Coordinate: Hierarchical Layer-Grouped Prompt Tuning for Continual Learning
Nov 15, 2025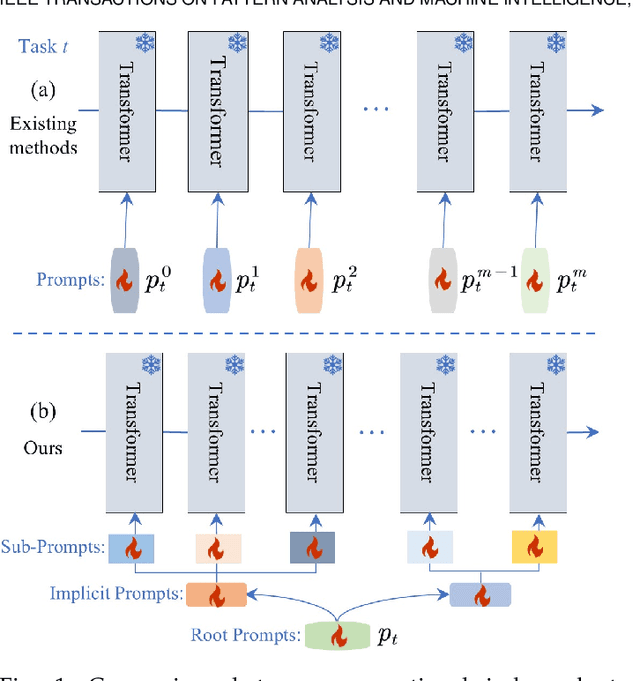
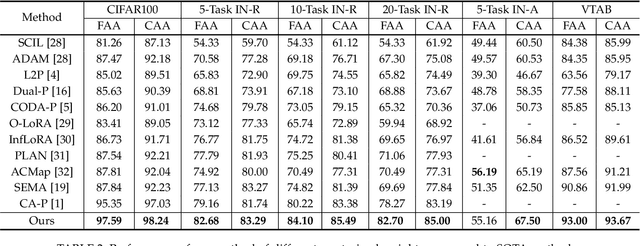
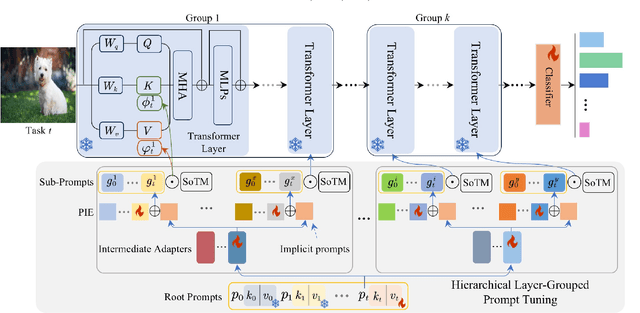
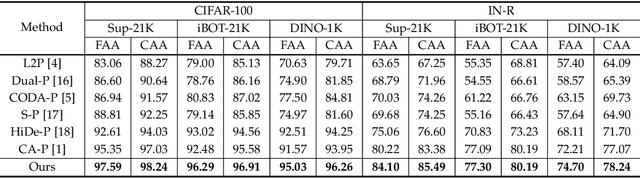
Prompt-based continual learning methods fine-tune only a small set of additional learnable parameters while keeping the pre-trained model's parameters frozen. It enables efficient adaptation to new tasks while mitigating the risk of catastrophic forgetting. These methods typically attach one independent task-specific prompt to each layer of pre-trained models to locally modulate its features, ensuring that the layer's representation aligns with the requirements of the new task. However, although introducing learnable prompts independently at each layer provides high flexibility for adapting to new tasks, this overly flexible tuning could make certain layers susceptible to unnecessary updates. As all prompts till the current task are added together as a final prompt for all seen tasks, the model may easily overwrite feature representations essential to previous tasks, which increases the risk of catastrophic forgetting. To address this issue, we propose a novel hierarchical layer-grouped prompt tuning method for continual learning. It improves model stability in two ways: (i) Layers in the same group share roughly the same prompts, which are adjusted by position encoding. This helps preserve the intrinsic feature relationships and propagation pathways of the pre-trained model within each group. (ii) It utilizes a single task-specific root prompt to learn to generate sub-prompts for each layer group. In this way, all sub-prompts are conditioned on the same root prompt, enhancing their synergy and reducing independence. Extensive experiments across four benchmarks demonstrate that our method achieves favorable performance compared with several state-of-the-art methods.
DeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
TAlignDiff: Automatic Tooth Alignment assisted by Diffusion-based Transformation Learning
Aug 06, 2025Orthodontic treatment hinges on tooth alignment, which significantly affects occlusal function, facial aesthetics, and patients' quality of life. Current deep learning approaches predominantly concentrate on predicting transformation matrices through imposing point-to-point geometric constraints for tooth alignment. Nevertheless, these matrices are likely associated with the anatomical structure of the human oral cavity and possess particular distribution characteristics that the deterministic point-to-point geometric constraints in prior work fail to capture. To address this, we introduce a new automatic tooth alignment method named TAlignDiff, which is supported by diffusion-based transformation learning. TAlignDiff comprises two main components: a primary point cloud-based regression network (PRN) and a diffusion-based transformation matrix denoising module (DTMD). Geometry-constrained losses supervise PRN learning for point cloud-level alignment. DTMD, as an auxiliary module, learns the latent distribution of transformation matrices from clinical data. We integrate point cloud-based transformation regression and diffusion-based transformation modeling into a unified framework, allowing bidirectional feedback between geometric constraints and diffusion refinement. Extensive ablation and comparative experiments demonstrate the effectiveness and superiority of our method, highlighting its potential in orthodontic treatment.
TopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
May 14, 2025



Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning. Videos and code are available at https://github.com/Zechao-Guan/TopoDiT-3D.
FauForensics: Boosting Audio-Visual Deepfake Detection with Facial Action Units
May 13, 2025The rapid evolution of generative AI has increased the threat of realistic audio-visual deepfakes, demanding robust detection methods. Existing solutions primarily address unimodal (audio or visual) forgeries but struggle with multimodal manipulations due to inadequate handling of heterogeneous modality features and poor generalization across datasets. To this end, we propose a novel framework called FauForensics by introducing biologically invariant facial action units (FAUs), which is a quantitative descriptor of facial muscle activity linked to emotion physiology. It serves as forgery-resistant representations that reduce domain dependency while capturing subtle dynamics often disrupted in synthetic content. Besides, instead of comparing entire video clips as in prior works, our method computes fine-grained frame-wise audiovisual similarities via a dedicated fusion module augmented with learnable cross-modal queries. It dynamically aligns temporal-spatial lip-audio relationships while mitigating multi-modal feature heterogeneity issues. Experiments on FakeAVCeleb and LAV-DF show state-of-the-art (SOTA) performance and superior cross-dataset generalizability with up to an average of 4.83\% than existing methods.
ProgRoCC: A Progressive Approach to Rough Crowd Counting
Apr 18, 2025
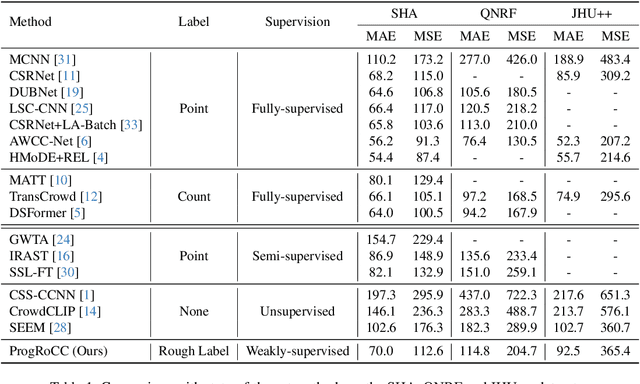
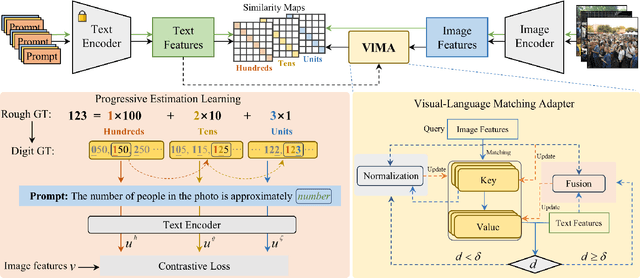

As the number of individuals in a crowd grows, enumeration-based techniques become increasingly infeasible and their estimates increasingly unreliable. We propose instead an estimation-based version of the problem: we label Rough Crowd Counting that delivers better accuracy on the basis of training data that is easier to acquire. Rough crowd counting requires only rough annotations of the number of targets in an image, instead of the more traditional, and far more expensive, per-target annotations. We propose an approach to the rough crowd counting problem based on CLIP, termed ProgRoCC. Specifically, we introduce a progressive estimation learning strategy that determines the object count through a coarse-to-fine approach. This approach delivers answers quickly, outperforms the state-of-the-art in semi- and weakly-supervised crowd counting. In addition, we design a vision-language matching adapter that optimizes key-value pairs by mining effective matches of two modalities to refine the visual features, thereby improving the final performance. Extensive experimental results on three widely adopted crowd counting datasets demonstrate the effectiveness of our method.