 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperFlow++: Enhanced Spatiotemporal Consistency for Cross-Modal Data Pretraining
Mar 25, 2025LiDAR representation learning has emerged as a promising approach to reducing reliance on costly and labor-intensive human annotations. While existing methods primarily focus on spatial alignment between LiDAR and camera sensors, they often overlook the temporal dynamics critical for capturing motion and scene continuity in driving scenarios. To address this limitation, we propose SuperFlow++, a novel framework that integrates spatiotemporal cues in both pretraining and downstream tasks using consecutive LiDAR-camera pairs. SuperFlow++ introduces four key components: (1) a view consistency alignment module to unify semantic information across camera views, (2) a dense-to-sparse consistency regularization mechanism to enhance feature robustness across varying point cloud densities, (3) a flow-based contrastive learning approach that models temporal relationships for improved scene understanding, and (4) a temporal voting strategy that propagates semantic information across LiDAR scans to improve prediction consistency. Extensive evaluations on 11 heterogeneous LiDAR datasets demonstrate that SuperFlow++ outperforms state-of-the-art methods across diverse tasks and driving conditions. Furthermore, by scaling both 2D and 3D backbones during pretraining, we uncover emergent properties that provide deeper insights into developing scalable 3D foundation models. With strong generalizability and computational efficiency, SuperFlow++ establishes a new benchmark for data-efficient LiDAR-based perception in autonomous driving. The code is publicly available at https://github.com/Xiangxu-0103/SuperFlow
PoI: Pixel of Interest for Novel View Synthesis Assisted Scene Coordinate Regression
Feb 07, 2025The task of estimating camera poses can be enhanced through novel view synthesis techniques such as NeRF and Gaussian Splatting to increase the diversity and extension of training data. However, these techniques often produce rendered images with issues like blurring and ghosting, which compromise their reliability. These issues become particularly pronounced for Scene Coordinate Regression (SCR) methods, which estimate 3D coordinates at the pixel level. To mitigate the problems associated with unreliable rendered images, we introduce a novel filtering approach, which selectively extracts well-rendered pixels while discarding the inferior ones. This filter simultaneously measures the SCR model's real-time reprojection loss and gradient during training. Building on this filtering technique, we also develop a new strategy to improve scene coordinate regression using sparse inputs, drawing on successful applications of sparse input techniques in novel view synthesis. Our experimental results validate the effectiveness of our method, demonstrating state-of-the-art performance on indoor and outdoor datasets.
LiMoE: Mixture of LiDAR Representation Learners from Automotive Scenes
Jan 07, 2025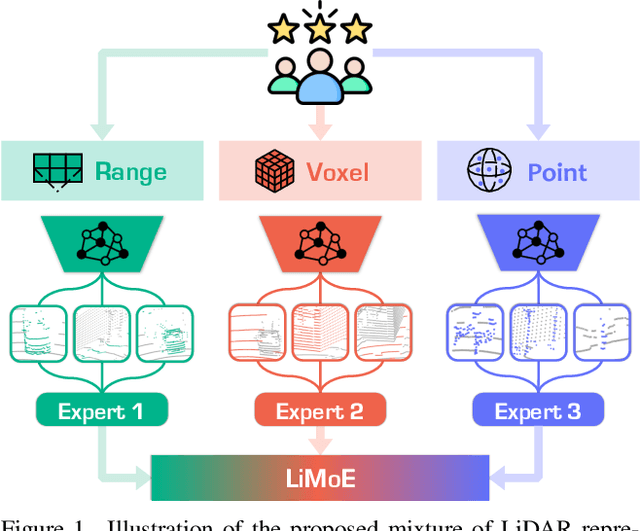



LiDAR data pretraining offers a promising approach to leveraging large-scale, readily available datasets for enhanced data utilization. However, existing methods predominantly focus on sparse voxel representation, overlooking the complementary attributes provided by other LiDAR representations. In this work, we propose LiMoE, a framework that integrates the Mixture of Experts (MoE) paradigm into LiDAR data representation learning to synergistically combine multiple representations, such as range images, sparse voxels, and raw points. Our approach consists of three stages: i) Image-to-LiDAR Pretraining, which transfers prior knowledge from images to point clouds across different representations; ii) Contrastive Mixture Learning (CML), which uses MoE to adaptively activate relevant attributes from each representation and distills these mixed features into a unified 3D network; iii) Semantic Mixture Supervision (SMS), which combines semantic logits from multiple representations to boost downstream segmentation performance. Extensive experiments across 11 large-scale LiDAR datasets demonstrate our effectiveness and superiority. The code and model checkpoints have been made publicly accessible.
4D Contrastive Superflows are Dense 3D Representation Learners
Jul 10, 2024



In the realm of autonomous driving, accurate 3D perception is the foundation. However, developing such models relies on extensive human annotations -- a process that is both costly and labor-intensive. To address this challenge from a data representation learning perspective, we introduce SuperFlow, a novel framework designed to harness consecutive LiDAR-camera pairs for establishing spatiotemporal pretraining objectives. SuperFlow stands out by integrating two key designs: 1) a dense-to-sparse consistency regularization, which promotes insensitivity to point cloud density variations during feature learning, and 2) a flow-based contrastive learning module, carefully crafted to extract meaningful temporal cues from readily available sensor calibrations. To further boost learning efficiency, we incorporate a plug-and-play view consistency module that enhances the alignment of the knowledge distilled from camera views. Extensive comparative and ablation studies across 11 heterogeneous LiDAR datasets validate our effectiveness and superiority. Additionally, we observe several interesting emerging properties by scaling up the 2D and 3D backbones during pretraining, shedding light on the future research of 3D foundation models for LiDAR-based perception.
Cooperative Sentiment Agents for Multimodal Sentiment Analysis
Apr 19, 2024



In this paper, we propose a new Multimodal Representation Learning (MRL) method for Multimodal Sentiment Analysis (MSA), which facilitates the adaptive interaction between modalities through Cooperative Sentiment Agents, named Co-SA. Co-SA comprises two critical components: the Sentiment Agents Establishment (SAE) phase and the Sentiment Agents Cooperation (SAC) phase. During the SAE phase, each sentiment agent deals with an unimodal signal and highlights explicit dynamic sentiment variations within the modality via the Modality-Sentiment Disentanglement (MSD) and Deep Phase Space Reconstruction (DPSR) modules. Subsequently, in the SAC phase, Co-SA meticulously designs task-specific interaction mechanisms for sentiment agents so that coordinating multimodal signals to learn the joint representation. Specifically, Co-SA equips an independent policy model for each sentiment agent that captures significant properties within the modality. These policies are optimized mutually through the unified reward adaptive to downstream tasks. Benefitting from the rewarding mechanism, Co-SA transcends the limitation of pre-defined fusion modes and adaptively captures unimodal properties for MRL in the multimodal interaction setting. To demonstrate the effectiveness of Co-SA, we apply it to address Multimodal Sentiment Analysis (MSA) and Multimodal Emotion Recognition (MER) tasks. Our comprehensive experimental results demonstrate that Co-SA excels at discovering diverse cross-modal features, encompassing both common and complementary aspects. The code can be available at https://github.com/smwanghhh/Co-SA.
FRNet: Frustum-Range Networks for Scalable LiDAR Segmentation
Dec 07, 2023LiDAR segmentation is crucial for autonomous driving systems. The recent range-view approaches are promising for real-time processing. However, they suffer inevitably from corrupted contextual information and rely heavily on post-processing techniques for prediction refinement. In this work, we propose a simple yet powerful FRNet that restores the contextual information of the range image pixels with corresponding frustum LiDAR points. Firstly, a frustum feature encoder module is used to extract per-point features within the frustum region, which preserves scene consistency and is crucial for point-level predictions. Next, a frustum-point fusion module is introduced to update per-point features hierarchically, which enables each point to extract more surrounding information via the frustum features. Finally, a head fusion module is used to fuse features at different levels for final semantic prediction. Extensive experiments on four popular LiDAR segmentation benchmarks under various task setups demonstrate our superiority. FRNet achieves competitive performance while maintaining high efficiency. The code is publicly available.
Adaptively Multi-view and Temporal Fusing Transformer for 3D Human Pose Estimation
Oct 11, 2021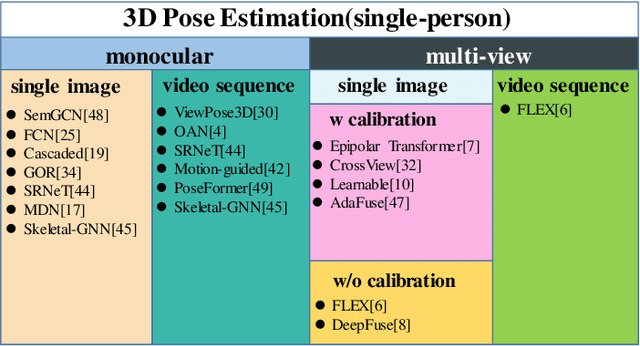
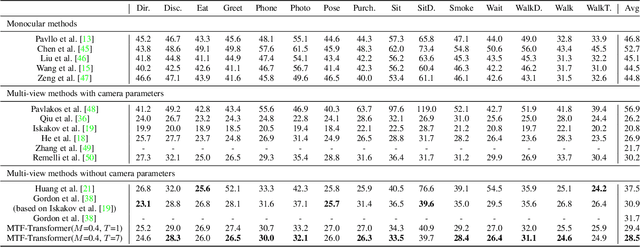
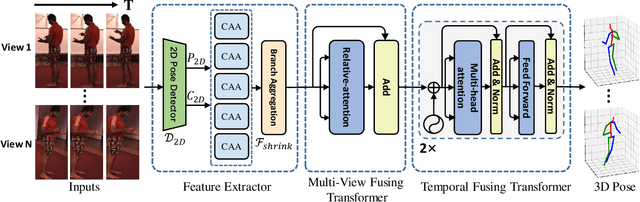

In practical application, 3D Human Pose Estimation (HPE) is facing with several variable elements, involving the number of views, the length of the video sequence, and whether using camera calibration. To this end, we propose a unified framework named Multi-view and Temporal Fusing Transformer (MTF-Transformer) to adaptively handle varying view numbers and video length without calibration. MTF-Transformer consists of Feature Extractor, Multi-view Fusing Transformer (MFT), and Temporal Fusing Transformer (TFT). Feature Extractor estimates the 2D pose from each image and encodes the predicted coordinates and confidence into feature embedding for further 3D pose inference. It discards the image features and focuses on lifting the 2D pose into the 3D pose, making the subsequent modules computationally lightweight enough to handle videos. MFT fuses the features of a varying number of views with a relative-attention block. It adaptively measures the implicit relationship between each pair of views and reconstructs the features. TFT aggregates the features of the whole sequence and predicts 3D pose via a transformer, which is adaptive to the length of the video and takes full advantage of the temporal information. With these modules, MTF-Transformer handles different application scenes, varying from a monocular-single-image to multi-view-video, and the camera calibration is avoidable. We demonstrate quantitative and qualitative results on the Human3.6M, TotalCapture, and KTH Multiview Football II. Compared with state-of-the-art methods with camera parameters, experiments show that MTF-Transformer not only obtains comparable results but also generalizes well to dynamic capture with an arbitrary number of unseen views. Code is available in https://github.com/lelexx/MTF-Transformer.