 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysX-Omni: Unified Simulation-Ready Physical 3D Generation for Rigid, Deformable, and Articulated Objects
May 20, 2026Simulation-ready physical 3D assets have emerged as a promising direction owing to their broad applicability in downstream tasks. However, most existing 3D generation methods either neglect physical properties or are limited to a single asset category, e.g., rigid, deformable, or articulated objects. To address these limitations, we introduce PhysX-Omni, a unified framework for simulation-ready physical 3D generation across diverse asset types. Specifically, we develop a novel and efficient geometry representation tailored for Vision-Language Models, which directly encodes high-resolution 3D structures without compression, significantly improving generation performance. In addition, we construct the first general simulation-ready 3D dataset, PhysXVerse, covering diverse indoor and outdoor categories. Furthermore, to comprehensively and flexibly evaluate both generative and understanding capabilities in the wild, we propose PhysX-Bench, which encompasses six key attributes: geometry, absolute scale, material, affordance, kinematics, and function description. Extensive experiments with conventional metrics and PhysX-Bench show that PhysX-Omni performs strongly in both generation and understanding. Moreover, additional studies further validate the potential of PhysX-Omni for applications in simulation-ready scene generation and robotic policy learning. We believe PhysX-Omni can significantly advance a wide range of downstream applications, particularly in embodied AI and physics-based simulation.
Is Your Driving World Model an All-Around Player?
May 11, 2026Today's driving world models can generate remarkably realistic dash-cam videos, yet no single model excels universally. Some generate photorealistic textures but violate basic physics; others maintain geometric consistency but fail when subjected to closed-loop planning. This disconnect exposes a critical gap: the field evaluates how real generated worlds appear, but rarely whether they behave realistically. We introduce WorldLens, a unified benchmark that measures world-model fidelity across the full spectrum, from pixel quality and 4D geometry to closed-loop driving and human perceptual alignment, through five complementary aspects and 24 standardized dimensions. Our evaluation of six representative models reveals that no existing approach dominates across all axes: texture-rich models violate geometry, geometry-aware models lack behavioral fidelity, and even the strongest performers achieve only 2-3 out of 10 on human realism ratings. To bridge algorithmic metrics with human perception, we further contribute WorldLens-26K, a 26,808-entry human-annotated preference dataset pairing numerical scores with textual rationales, and WorldLens-Agent, a vision-language evaluator distilled from these judgments that enables scalable, explainable auto-assessment. Together, the benchmark, dataset, and agent form a unified ecosystem for assessing generated worlds not merely by visual appeal, but by physical and behavioral fidelity.
HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
Mar 16, 2026We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos. Existing methods suffer from a perception-simulation gap: visually plausible reconstructions often violate physical constraints, leading to instability in physics engines and failure in embodied AI applications. To bridge this gap, we introduce a physically-grounded bi-directional optimization pipeline that treats the physics simulator as an active supervisor to jointly refine human dynamics and scene geometry. In the forward direction, we employ Scene-targeted Reinforcement Learning to optimize human motion under dual supervision of motion fidelity and contact stability. In the reverse direction, we propose Direct Simulation Reward Optimization, which leverages simulation feedback on gravitational stability and interaction success to refine scene geometry. We further present HSIBench, a new benchmark with diverse objects and interaction scenarios. Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots.
PureCC: Pure Learning for Text-to-Image Concept Customization
Mar 08, 2026Existing concept customization methods have achieved remarkable outcomes in high-fidelity and multi-concept customization. However, they often neglect the influence on the original model's behavior and capabilities when learning new personalized concepts. To address this issue, we propose PureCC. PureCC introduces a novel decoupled learning objective for concept customization, which combines the implicit guidance of the target concept with the original conditional prediction. This separated form enables PureCC to substantially focus on the original model during training. Moreover, based on this objective, PureCC designs a dual-branch training pipeline that includes a frozen extractor providing purified target concept representations as implicit guidance and a trainable flow model producing the original conditional prediction, jointly achieving pure learning for personalized concepts. Furthermore, PureCC introduces a novel adaptive guidance scale $λ^\star$ to dynamically adjust the guidance strength of the target concept, balancing customization fidelity and model preservation. Extensive experiments show that PureCC achieves state-of-the-art performance in preserving the original behavior and capabilities while enabling high-fidelity concept customization. The code is available at https://github.com/lzc-sg/PureCC.
EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents
Feb 26, 2026Human behaviors in the real world naturally encode rich, long-term contextual information that can be leveraged to train embodied agents for perception, understanding, and acting. However, existing capture systems typically rely on costly studio setups and wearable devices, limiting the large-scale collection of scene-conditioned human motion data in the wild. To address this, we propose EmbodMocap, a portable and affordable data collection pipeline using two moving iPhones. Our key idea is to jointly calibrate dual RGB-D sequences to reconstruct both humans and scenes within a unified metric world coordinate frame. The proposed method allows metric-scale and scene-consistent capture in everyday environments without static cameras or markers, bridging human motion and scene geometry seamlessly. Compared with optical capture ground truth, we demonstrate that the dual-view setting exhibits a remarkable ability to mitigate depth ambiguity, achieving superior alignment and reconstruction performance over single iphone or monocular models. Based on the collected data, we empower three embodied AI tasks: monocular human-scene-reconstruction, where we fine-tune on feedforward models that output metric-scale, world-space aligned humans and scenes; physics-based character animation, where we prove our data could be used to scale human-object interaction skills and scene-aware motion tracking; and robot motion control, where we train a humanoid robot via sim-to-real RL to replicate human motions depicted in videos. Experimental results validate the effectiveness of our pipeline and its contributions towards advancing embodied AI research.
OnlineSI: Taming Large Language Model for Online 3D Understanding and Grounding
Jan 23, 2026In recent years, researchers have increasingly been interested in how to enable Multimodal Large Language Models (MLLM) to possess spatial understanding and reasoning capabilities. However, most existing methods overlook the importance of the ability to continuously work in an ever-changing world, and lack the possibility of deployment on embodied systems in real-world environments. In this work, we introduce OnlineSI, a framework that can continuously improve its spatial understanding of its surroundings given a video stream. Our core idea is to maintain a finite spatial memory to retain past observations, ensuring the computation required for each inference does not increase as the input accumulates. We further integrate 3D point cloud information with semantic information, helping MLLM to better locate and identify objects in the scene. To evaluate our method, we introduce the Fuzzy $F_1$-Score to mitigate ambiguity, and test our method on two representative datasets. Experiments demonstrate the effectiveness of our method, paving the way towards real-world embodied systems.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
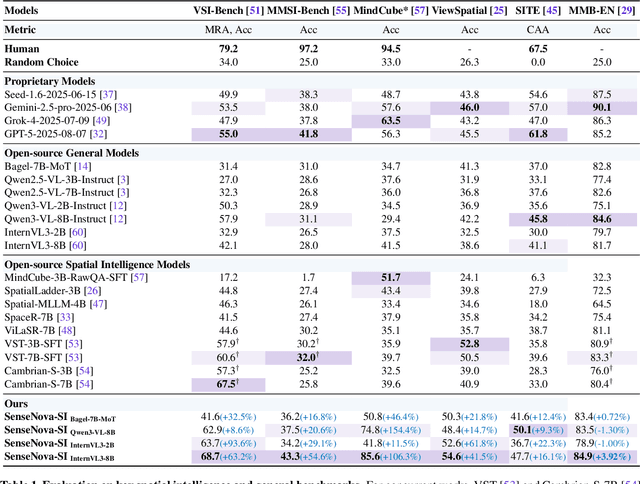


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Nov 17, 20253D modeling is shifting from static visual representations toward physical, articulated assets that can be directly used in simulation and interaction. However, most existing 3D generation methods overlook key physical and articulation properties, thereby limiting their utility in embodied AI. To bridge this gap, we introduce PhysX-Anything, the first simulation-ready physical 3D generative framework that, given a single in-the-wild image, produces high-quality sim-ready 3D assets with explicit geometry, articulation, and physical attributes. Specifically, we propose the first VLM-based physical 3D generative model, along with a new 3D representation that efficiently tokenizes geometry. It reduces the number of tokens by 193x, enabling explicit geometry learning within standard VLM token budgets without introducing any special tokens during fine-tuning and significantly improving generative quality. In addition, to overcome the limited diversity of existing physical 3D datasets, we construct a new dataset, PhysX-Mobility, which expands the object categories in prior physical 3D datasets by over 2x and includes more than 2K common real-world objects with rich physical annotations. Extensive experiments on PhysX-Mobility and in-the-wild images demonstrate that PhysX-Anything delivers strong generative performance and robust generalization. Furthermore, simulation-based experiments in a MuJoCo-style environment validate that our sim-ready assets can be directly used for contact-rich robotic policy learning. We believe PhysX-Anything can substantially empower a broad range of downstream applications, especially in embodied AI and physics-based simulation.
SEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Oct 30, 2025Immersive applications call for synthesizing spatiotemporal 4D content from casual videos without costly 3D supervision. Existing video-to-4D methods typically rely on manually annotated camera poses, which are labor-intensive and brittle for in-the-wild footage. Recent warp-then-inpaint approaches mitigate the need for pose labels by warping input frames along a novel camera trajectory and using an inpainting model to fill missing regions, thereby depicting the 4D scene from diverse viewpoints. However, this trajectory-to-trajectory formulation often entangles camera motion with scene dynamics and complicates both modeling and inference. We introduce SEE4D, a pose-free, trajectory-to-camera framework that replaces explicit trajectory prediction with rendering to a bank of fixed virtual cameras, thereby separating camera control from scene modeling. A view-conditional video inpainting model is trained to learn a robust geometry prior by denoising realistically synthesized warped images and to inpaint occluded or missing regions across virtual viewpoints, eliminating the need for explicit 3D annotations. Building on this inpainting core, we design a spatiotemporal autoregressive inference pipeline that traverses virtual-camera splines and extends videos with overlapping windows, enabling coherent generation at bounded per-step complexity. We validate See4D on cross-view video generation and sparse reconstruction benchmarks. Across quantitative metrics and qualitative assessments, our method achieves superior generalization and improved performance relative to pose- or trajectory-conditioned baselines, advancing practical 4D world modeling from casual videos.