 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Perspective-Invariant 3D Object Detection
Jul 23, 2025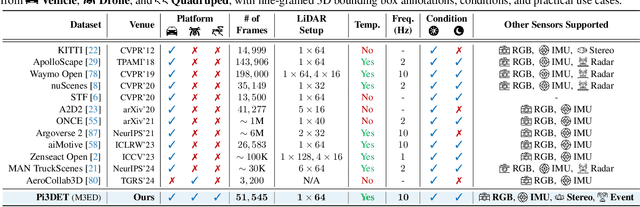
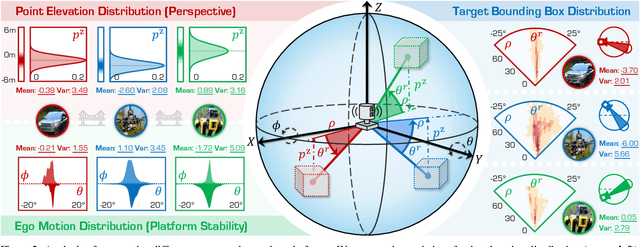
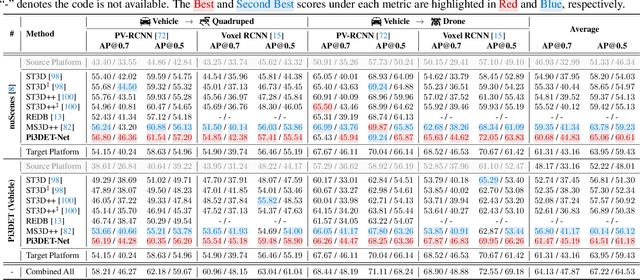
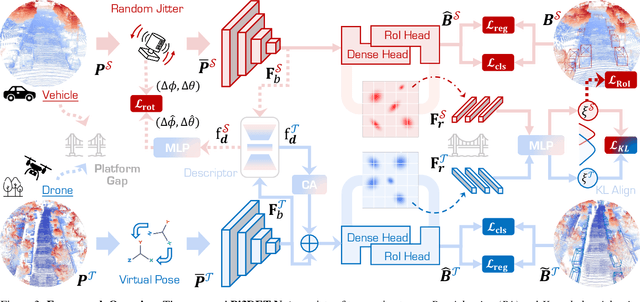
With the rise of robotics, LiDAR-based 3D object detection has garnered significant attention in both academia and industry. However, existing datasets and methods predominantly focus on vehicle-mounted platforms, leaving other autonomous platforms underexplored. To bridge this gap, we introduce Pi3DET, the first benchmark featuring LiDAR data and 3D bounding box annotations collected from multiple platforms: vehicle, quadruped, and drone, thereby facilitating research in 3D object detection for non-vehicle platforms as well as cross-platform 3D detection. Based on Pi3DET, we propose a novel cross-platform adaptation framework that transfers knowledge from the well-studied vehicle platform to other platforms. This framework achieves perspective-invariant 3D detection through robust alignment at both geometric and feature levels. Additionally, we establish a benchmark to evaluate the resilience and robustness of current 3D detectors in cross-platform scenarios, providing valuable insights for developing adaptive 3D perception systems. Extensive experiments validate the effectiveness of our approach on challenging cross-platform tasks, demonstrating substantial gains over existing adaptation methods. We hope this work paves the way for generalizable and unified 3D perception systems across diverse and complex environments. Our Pi3DET dataset, cross-platform benchmark suite, and annotation toolkit have been made publicly available.
SPIRAL: Semantic-Aware Progressive LiDAR Scene Generation
May 28, 2025Leveraging recent diffusion models, LiDAR-based large-scale 3D scene generation has achieved great success. While recent voxel-based approaches can generate both geometric structures and semantic labels, existing range-view methods are limited to producing unlabeled LiDAR scenes. Relying on pretrained segmentation models to predict the semantic maps often results in suboptimal cross-modal consistency. To address this limitation while preserving the advantages of range-view representations, such as computational efficiency and simplified network design, we propose Spiral, a novel range-view LiDAR diffusion model that simultaneously generates depth, reflectance images, and semantic maps. Furthermore, we introduce novel semantic-aware metrics to evaluate the quality of the generated labeled range-view data. Experiments on the SemanticKITTI and nuScenes datasets demonstrate that Spiral achieves state-of-the-art performance with the smallest parameter size, outperforming two-step methods that combine the generative and segmentation models. Additionally, we validate that range images generated by Spiral can be effectively used for synthetic data augmentation in the downstream segmentation training, significantly reducing the labeling effort on LiDAR data.
LargeAD: Large-Scale Cross-Sensor Data Pretraining for Autonomous Driving
Jan 07, 2025Recent advancements in vision foundation models (VFMs) have revolutionized visual perception in 2D, yet their potential for 3D scene understanding, particularly in autonomous driving applications, remains underexplored. In this paper, we introduce LargeAD, a versatile and scalable framework designed for large-scale 3D pretraining across diverse real-world driving datasets. Our framework leverages VFMs to extract semantically rich superpixels from 2D images, which are aligned with LiDAR point clouds to generate high-quality contrastive samples. This alignment facilitates cross-modal representation learning, enhancing the semantic consistency between 2D and 3D data. We introduce several key innovations: i) VFM-driven superpixel generation for detailed semantic representation, ii) a VFM-assisted contrastive learning strategy to align multimodal features, iii) superpoint temporal consistency to maintain stable representations across time, and iv) multi-source data pretraining to generalize across various LiDAR configurations. Our approach delivers significant performance improvements over state-of-the-art methods in both linear probing and fine-tuning tasks for both LiDAR-based segmentation and object detection. Extensive experiments on eleven large-scale multi-modal datasets highlight our superior performance, demonstrating the adaptability, efficiency, and robustness in real-world autonomous driving scenarios.
OVGaussian: Generalizable 3D Gaussian Segmentation with Open Vocabularies
Dec 31, 2024Open-vocabulary scene understanding using 3D Gaussian (3DGS) representations has garnered considerable attention. However, existing methods mostly lift knowledge from large 2D vision models into 3DGS on a scene-by-scene basis, restricting the capabilities of open-vocabulary querying within their training scenes so that lacking the generalizability to novel scenes. In this work, we propose \textbf{OVGaussian}, a generalizable \textbf{O}pen-\textbf{V}ocabulary 3D semantic segmentation framework based on the 3D \textbf{Gaussian} representation. We first construct a large-scale 3D scene dataset based on 3DGS, dubbed \textbf{SegGaussian}, which provides detailed semantic and instance annotations for both Gaussian points and multi-view images. To promote semantic generalization across scenes, we introduce Generalizable Semantic Rasterization (GSR), which leverages a 3D neural network to learn and predict the semantic property for each 3D Gaussian point, where the semantic property can be rendered as multi-view consistent 2D semantic maps. In the next, we propose a Cross-modal Consistency Learning (CCL) framework that utilizes open-vocabulary annotations of 2D images and 3D Gaussians within SegGaussian to train the 3D neural network capable of open-vocabulary semantic segmentation across Gaussian-based 3D scenes. Experimental results demonstrate that OVGaussian significantly outperforms baseline methods, exhibiting robust cross-scene, cross-domain, and novel-view generalization capabilities. Code and the SegGaussian dataset will be released. (https://github.com/runnanchen/OVGaussian).
An Empirical Study of Training State-of-the-Art LiDAR Segmentation Models
May 23, 2024In the rapidly evolving field of autonomous driving, precise segmentation of LiDAR data is crucial for understanding complex 3D environments. Traditional approaches often rely on disparate, standalone codebases, hindering unified advancements and fair benchmarking across models. To address these challenges, we introduce MMDetection3D-lidarseg, a comprehensive toolbox designed for the efficient training and evaluation of state-of-the-art LiDAR segmentation models. We support a wide range of segmentation models and integrate advanced data augmentation techniques to enhance robustness and generalization. Additionally, the toolbox provides support for multiple leading sparse convolution backends, optimizing computational efficiency and performance. By fostering a unified framework, MMDetection3D-lidarseg streamlines development and benchmarking, setting new standards for research and application. Our extensive benchmark experiments on widely-used datasets demonstrate the effectiveness of the toolbox. The codebase and trained models have been publicly available, promoting further research and innovation in the field of LiDAR segmentation for autonomous driving.
OpenESS: Event-based Semantic Scene Understanding with Open Vocabularies
May 08, 2024



Event-based semantic segmentation (ESS) is a fundamental yet challenging task for event camera sensing. The difficulties in interpreting and annotating event data limit its scalability. While domain adaptation from images to event data can help to mitigate this issue, there exist data representational differences that require additional effort to resolve. In this work, for the first time, we synergize information from image, text, and event-data domains and introduce OpenESS to enable scalable ESS in an open-world, annotation-efficient manner. We achieve this goal by transferring the semantically rich CLIP knowledge from image-text pairs to event streams. To pursue better cross-modality adaptation, we propose a frame-to-event contrastive distillation and a text-to-event semantic consistency regularization. Experimental results on popular ESS benchmarks showed our approach outperforms existing methods. Notably, we achieve 53.93% and 43.31% mIoU on DDD17 and DSEC-Semantic without using either event or frame labels.
Multi-Space Alignments Towards Universal LiDAR Segmentation
May 02, 2024


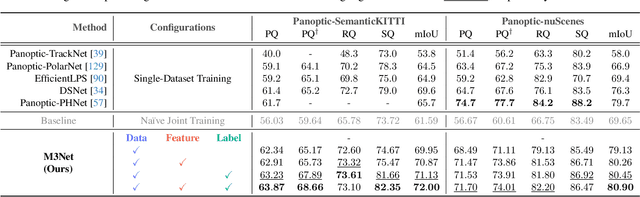
A unified and versatile LiDAR segmentation model with strong robustness and generalizability is desirable for safe autonomous driving perception. This work presents M3Net, a one-of-a-kind framework for fulfilling multi-task, multi-dataset, multi-modality LiDAR segmentation in a universal manner using just a single set of parameters. To better exploit data volume and diversity, we first combine large-scale driving datasets acquired by different types of sensors from diverse scenes and then conduct alignments in three spaces, namely data, feature, and label spaces, during the training. As a result, M3Net is capable of taming heterogeneous data for training state-of-the-art LiDAR segmentation models. Extensive experiments on twelve LiDAR segmentation datasets verify our effectiveness. Notably, using a shared set of parameters, M3Net achieves 75.1%, 83.1%, and 72.4% mIoU scores, respectively, on the official benchmarks of SemanticKITTI, nuScenes, and Waymo Open.
Visual Foundation Models Boost Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation
Mar 15, 2024



Unsupervised domain adaptation (UDA) is vital for alleviating the workload of labeling 3D point cloud data and mitigating the absence of labels when facing a newly defined domain. Various methods of utilizing images to enhance the performance of cross-domain 3D segmentation have recently emerged. However, the pseudo labels, which are generated from models trained on the source domain and provide additional supervised signals for the unseen domain, are inadequate when utilized for 3D segmentation due to their inherent noisiness and consequently restrict the accuracy of neural networks. With the advent of 2D visual foundation models (VFMs) and their abundant knowledge prior, we propose a novel pipeline VFMSeg to further enhance the cross-modal unsupervised domain adaptation framework by leveraging these models. In this work, we study how to harness the knowledge priors learned by VFMs to produce more accurate labels for unlabeled target domains and improve overall performance. We first utilize a multi-modal VFM, which is pre-trained on large scale image-text pairs, to provide supervised labels (VFM-PL) for images and point clouds from the target domain. Then, another VFM trained on fine-grained 2D masks is adopted to guide the generation of semantically augmented images and point clouds to enhance the performance of neural networks, which mix the data from source and target domains like view frustums (FrustumMixing). Finally, we merge class-wise prediction across modalities to produce more accurate annotations for unlabeled target domains. Our method is evaluated on various autonomous driving datasets and the results demonstrate a significant improvement for 3D segmentation task.
SAM-guided Unsupervised Domain Adaptation for 3D Segmentation
Oct 16, 2023Unsupervised domain adaptation (UDA) in 3D segmentation tasks presents a formidable challenge, primarily stemming from the sparse and unordered nature of point cloud data. Especially for LiDAR point clouds, the domain discrepancy becomes obvious across varying capture scenes, fluctuating weather conditions, and the diverse array of LiDAR devices in use. While previous UDA methodologies have often sought to mitigate this gap by aligning features between source and target domains, this approach falls short when applied to 3D segmentation due to the substantial domain variations. Inspired by the remarkable generalization capabilities exhibited by the vision foundation model, SAM, in the realm of image segmentation, our approach leverages the wealth of general knowledge embedded within SAM to unify feature representations across diverse 3D domains and further solves the 3D domain adaptation problem. Specifically, we harness the corresponding images associated with point clouds to facilitate knowledge transfer and propose an innovative hybrid feature augmentation methodology, which significantly enhances the alignment between the 3D feature space and SAM's feature space, operating at both the scene and instance levels. Our method is evaluated on many widely-recognized datasets and achieves state-of-the-art performance.