 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveMan: mmWave-Based Room-Scale Human Interaction Perception for Humanoid Robots
Jan 12, 2026Reliable humanoid-robot interaction (HRI) in household environments is constrained by two fundamental requirements, namely robustness to unconstrained user positions and preservation of user privacy. Millimeter-wave (mmWave) sensing inherently supports privacy-preserving interaction, making it a promising modality for room-scale HRI. However, existing mmWave-based interaction-sensing systems exhibit poor spatial generalization at unseen distances or viewpoints. To address this challenge, we introduce WaveMan, a spatially adaptive room-scale perception system that restores reliable human interaction sensing across arbitrary user positions. WaveMan integrates viewpoint alignment and spectrogram enhancement for spatial consistency, with dual-channel attention for robust feature extraction. Experiments across five participants show that, under fixed-position evaluation, WaveMan achieves the same cross-position accuracy as the baseline with five times fewer training positions. In random free-position testing, accuracy increases from 33.00% to 94.33%, enabled by the proposed method. These results demonstrate the feasibility of reliable, privacy-preserving interaction for household humanoid robots across unconstrained user positions.
Large Sign Language Models: Toward 3D American Sign Language Translation
Nov 11, 2025We present Large Sign Language Models (LSLM), a novel framework for translating 3D American Sign Language (ASL) by leveraging Large Language Models (LLMs) as the backbone, which can benefit hearing-impaired individuals' virtual communication. Unlike existing sign language recognition methods that rely on 2D video, our approach directly utilizes 3D sign language data to capture rich spatial, gestural, and depth information in 3D scenes. This enables more accurate and resilient translation, enhancing digital communication accessibility for the hearing-impaired community. Beyond the task of ASL translation, our work explores the integration of complex, embodied multimodal languages into the processing capabilities of LLMs, moving beyond purely text-based inputs to broaden their understanding of human communication. We investigate both direct translation from 3D gesture features to text and an instruction-guided setting where translations can be modulated by external prompts, offering greater flexibility. This work provides a foundational step toward inclusive, multimodal intelligent systems capable of understanding diverse forms of language.
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023



Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
UniSeg: A Unified Multi-Modal LiDAR Segmentation Network and the OpenPCSeg Codebase
Sep 11, 2023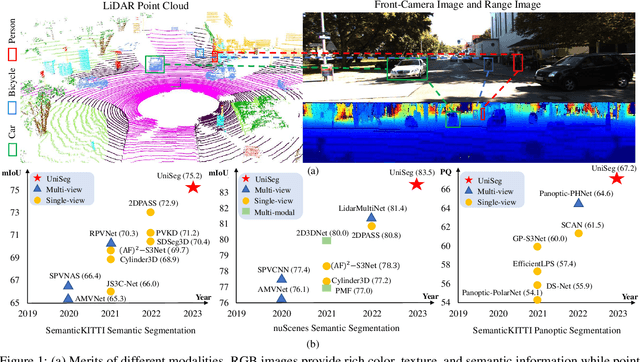

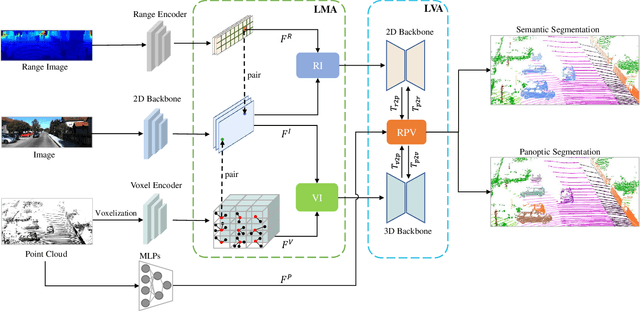
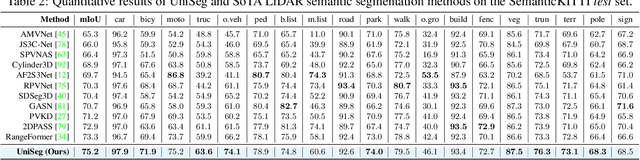
Point-, voxel-, and range-views are three representative forms of point clouds. All of them have accurate 3D measurements but lack color and texture information. RGB images are a natural complement to these point cloud views and fully utilizing the comprehensive information of them benefits more robust perceptions. In this paper, we present a unified multi-modal LiDAR segmentation network, termed UniSeg, which leverages the information of RGB images and three views of the point cloud, and accomplishes semantic segmentation and panoptic segmentation simultaneously. Specifically, we first design the Learnable cross-Modal Association (LMA) module to automatically fuse voxel-view and range-view features with image features, which fully utilize the rich semantic information of images and are robust to calibration errors. Then, the enhanced voxel-view and range-view features are transformed to the point space,where three views of point cloud features are further fused adaptively by the Learnable cross-View Association module (LVA). Notably, UniSeg achieves promising results in three public benchmarks, i.e., SemanticKITTI, nuScenes, and Waymo Open Dataset (WOD); it ranks 1st on two challenges of two benchmarks, including the LiDAR semantic segmentation challenge of nuScenes and panoptic segmentation challenges of SemanticKITTI. Besides, we construct the OpenPCSeg codebase, which is the largest and most comprehensive outdoor LiDAR segmentation codebase. It contains most of the popular outdoor LiDAR segmentation algorithms and provides reproducible implementations. The OpenPCSeg codebase will be made publicly available at https://github.com/PJLab-ADG/PCSeg.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023
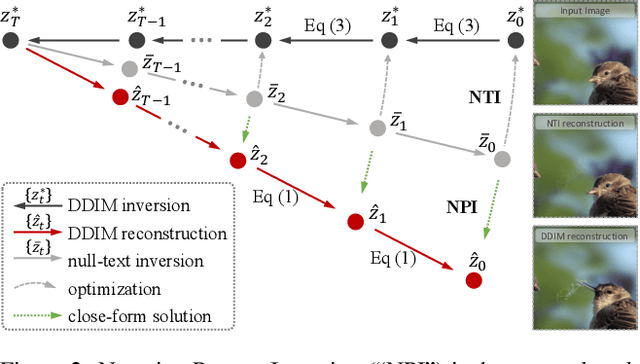
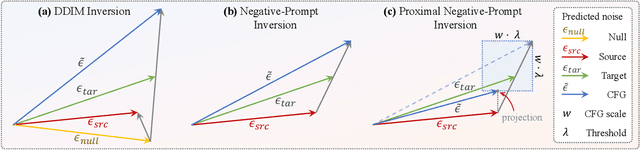

DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Configurable Spatial-Temporal Hierarchical Analysis for Flexible Video Anomaly Detection
May 12, 2023



Video anomaly detection (VAD) is a vital task with great practical applications in industrial surveillance, security system, and traffic control. Unlike previous unsupervised VAD methods that adopt a fixed structure to learn normality without considering different detection demands, we design a spatial-temporal hierarchical architecture (STHA) as a configurable architecture to flexibly detect different degrees of anomaly. The comprehensive structure of the STHA is delineated into a tripartite hierarchy, encompassing the following tiers: the stream level, the stack level, and the block level. Specifically, we design several auto-encoder-based blocks that possess varying capacities for extracting normal patterns. Then, we stack blocks according to the complexity degrees with both intra-stack and inter-stack residual links to learn hierarchical normality gradually. Considering the multisource knowledge of videos, we also model the spatial normality of video frames and temporal normality of RGB difference by designing two parallel streams consisting of stacks. Thus, STHA can provide various representation learning abilities by expanding or contracting hierarchically to detect anomalies of different degrees. Since the anomaly set is complicated and unbounded, our STHA can adjust its detection ability to adapt to the human detection demands and the complexity degree of anomaly that happened in the history of a scene. We conduct experiments on three benchmarks and perform extensive analysis, and the results demonstrate that our method performs comparablely to the state-of-the-art methods. In addition, we design a toy dataset to prove that our model can better balance the learning ability to adapt to different detection demands.
SCPNet: Semantic Scene Completion on Point Cloud
Mar 13, 2023Training deep models for semantic scene completion (SSC) is challenging due to the sparse and incomplete input, a large quantity of objects of diverse scales as well as the inherent label noise for moving objects. To address the above-mentioned problems, we propose the following three solutions: 1) Redesigning the completion sub-network. We design a novel completion sub-network, which consists of several Multi-Path Blocks (MPBs) to aggregate multi-scale features and is free from the lossy downsampling operations. 2) Distilling rich knowledge from the multi-frame model. We design a novel knowledge distillation objective, dubbed Dense-to-Sparse Knowledge Distillation (DSKD). It transfers the dense, relation-based semantic knowledge from the multi-frame teacher to the single-frame student, significantly improving the representation learning of the single-frame model. 3) Completion label rectification. We propose a simple yet effective label rectification strategy, which uses off-the-shelf panoptic segmentation labels to remove the traces of dynamic objects in completion labels, greatly improving the performance of deep models especially for those moving objects. Extensive experiments are conducted in two public SSC benchmarks, i.e., SemanticKITTI and SemanticPOSS. Our SCPNet ranks 1st on SemanticKITTI semantic scene completion challenge and surpasses the competitive S3CNet by 7.2 mIoU. SCPNet also outperforms previous completion algorithms on the SemanticPOSS dataset. Besides, our method also achieves competitive results on SemanticKITTI semantic segmentation tasks, showing that knowledge learned in the scene completion is beneficial to the segmentation task.
Simulation and Measurement of Human Respiration and Heartbeat with Millimeter- Wave Radar
Jul 22, 2022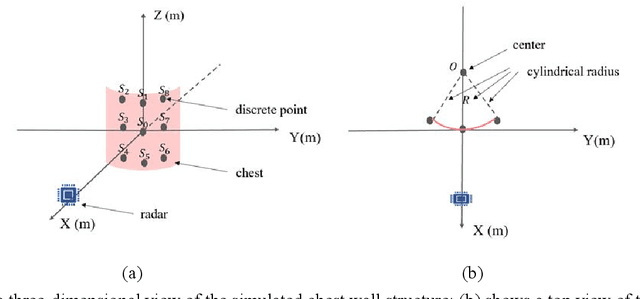
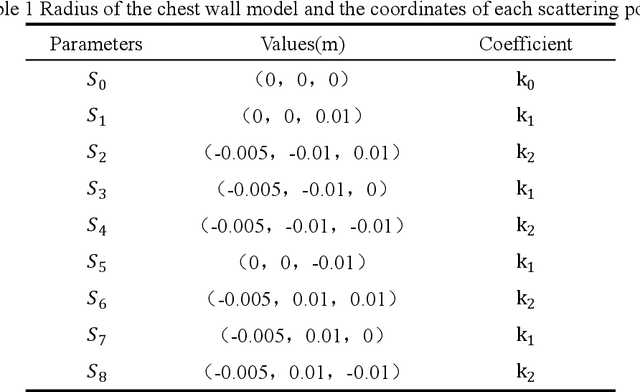
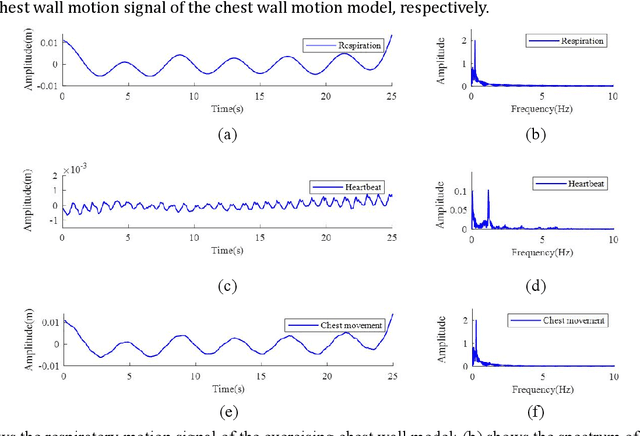
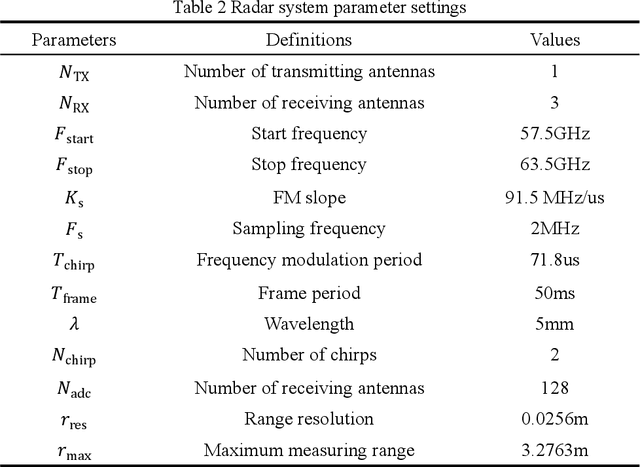
This paper establishes a multi-scattering point chest wall motion model by combining the human respiration signal (RS) and HS (HS) measured by radar. An algorithmic process is designed based on the model to accurately separate the human respiration and heartbeat motion. Firstly, a human maximum motion velocity constraint method is proposed to correct human chest wall tracking, determine the radial position of the chest wall relative to the radar, and extract the phase signal corresponding to the chest wall motion. Then an improved time-difference method is proposed to suppress the interference of RS harmonics on HS and the interference of low-frequency noise on RS. Finally, an adaptive Gaussian weighting filter is designed to extract the RS with less distortion from the phase signal. A low-order finite-length unit impulse response (FIR) filter is used to extract the HS with less distortion from the phase signal. To verify the effectiveness of the proposed algorithm, simulating the process of measuring the RS and HS of the chest wall motion model by radar. The simulation results show that, ideally, the radar measurement results of the RS and HS are less distorted relative to the actual values. In addition, we used a millimeter-wave experimental radar system in the 60 GHz band to measure the respiration rate (RR) and HR (HR) of two subjects. The experimental results showed that the measured RR and HR correlated well with the actual values. The quantitative analysis of simulation results and experimental results show that the proposed method can achieve accurate and robust measurement of RS and HS.
Hierarchically Self-Supervised Transformer for Human Skeleton Representation Learning
Jul 20, 2022
Despite the success of fully-supervised human skeleton sequence modeling, utilizing self-supervised pre-training for skeleton sequence representation learning has been an active field because acquiring task-specific skeleton annotations at large scales is difficult. Recent studies focus on learning video-level temporal and discriminative information using contrastive learning, but overlook the hierarchical spatial-temporal nature of human skeletons. Different from such superficial supervision at the video level, we propose a self-supervised hierarchical pre-training scheme incorporated into a hierarchical Transformer-based skeleton sequence encoder (Hi-TRS), to explicitly capture spatial, short-term, and long-term temporal dependencies at frame, clip, and video levels, respectively. To evaluate the proposed self-supervised pre-training scheme with Hi-TRS, we conduct extensive experiments covering three skeleton-based downstream tasks including action recognition, action detection, and motion prediction. Under both supervised and semi-supervised evaluation protocols, our method achieves the state-of-the-art performance. Additionally, we demonstrate that the prior knowledge learned by our model in the pre-training stage has strong transfer capability for different downstream tasks.
Region Proposal Rectification Towards Robust Instance Segmentation of Biological Images
Mar 06, 2022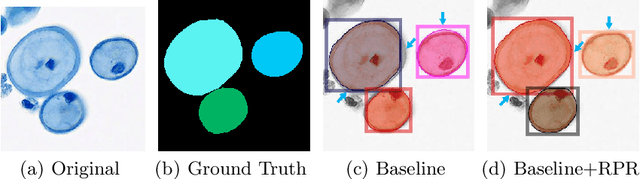
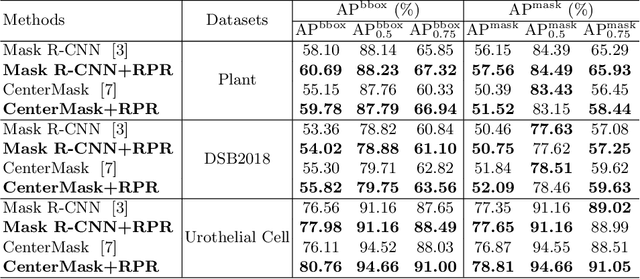
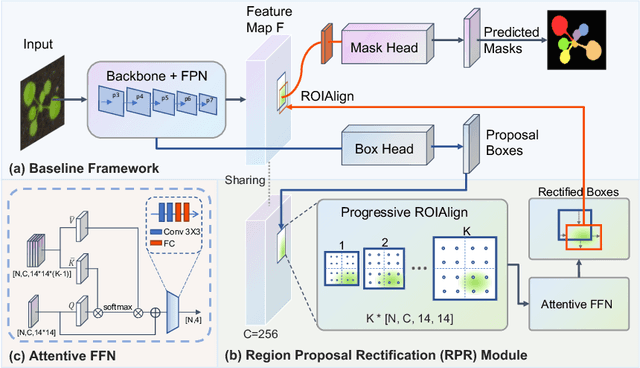
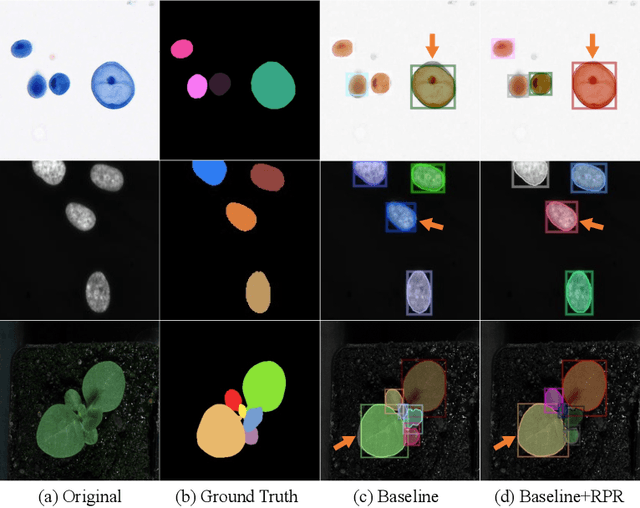
Top-down instance segmentation framework has shown its superiority in object detection compared to the bottom-up framework. While it is efficient in addressing over-segmentation, top-down instance segmentation suffers from over-crop problem. However, a complete segmentation mask is crucial for biological image analysis as it delivers important morphological properties such as shapes and volumes. In this paper, we propose a region proposal rectification (RPR) module to address this challenging incomplete segmentation problem. In particular, we offer a progressive ROIAlign module to introduce neighbor information into a series of ROIs gradually. The ROI features are fed into an attentive feed-forward network (FFN) for proposal box regression. With additional neighbor information, the proposed RPR module shows significant improvement in correction of region proposal locations and thereby exhibits favorable instance segmentation performances on three biological image datasets compared to state-of-the-art baseline methods. Experimental results demonstrate that the proposed RPR module is effective in both anchor-based and anchor-free top-down instance segmentation approaches, suggesting the proposed method can be applied to general top-down instance segmentation of biological images.