 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Spatial-Temporal Hierarchical Analysis for Flexible Video Anomaly Detection
May 12, 2023



Video anomaly detection (VAD) is a vital task with great practical applications in industrial surveillance, security system, and traffic control. Unlike previous unsupervised VAD methods that adopt a fixed structure to learn normality without considering different detection demands, we design a spatial-temporal hierarchical architecture (STHA) as a configurable architecture to flexibly detect different degrees of anomaly. The comprehensive structure of the STHA is delineated into a tripartite hierarchy, encompassing the following tiers: the stream level, the stack level, and the block level. Specifically, we design several auto-encoder-based blocks that possess varying capacities for extracting normal patterns. Then, we stack blocks according to the complexity degrees with both intra-stack and inter-stack residual links to learn hierarchical normality gradually. Considering the multisource knowledge of videos, we also model the spatial normality of video frames and temporal normality of RGB difference by designing two parallel streams consisting of stacks. Thus, STHA can provide various representation learning abilities by expanding or contracting hierarchically to detect anomalies of different degrees. Since the anomaly set is complicated and unbounded, our STHA can adjust its detection ability to adapt to the human detection demands and the complexity degree of anomaly that happened in the history of a scene. We conduct experiments on three benchmarks and perform extensive analysis, and the results demonstrate that our method performs comparablely to the state-of-the-art methods. In addition, we design a toy dataset to prove that our model can better balance the learning ability to adapt to different detection demands.
LGN-Net: Local-Global Normality Network for Video Anomaly Detection
Nov 21, 2022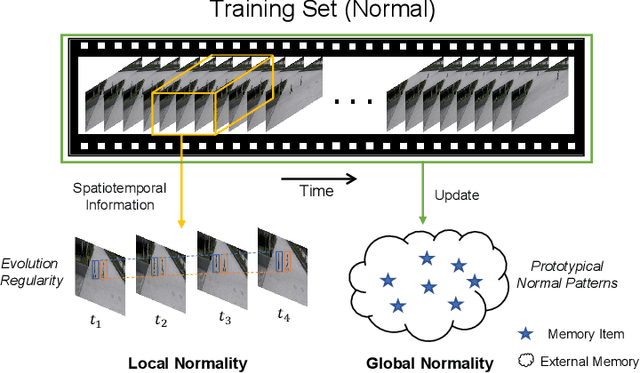
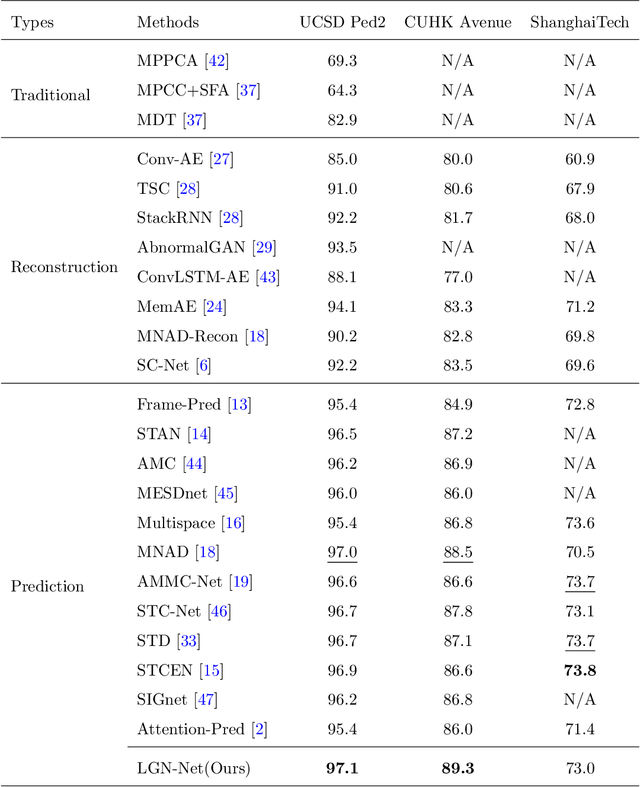
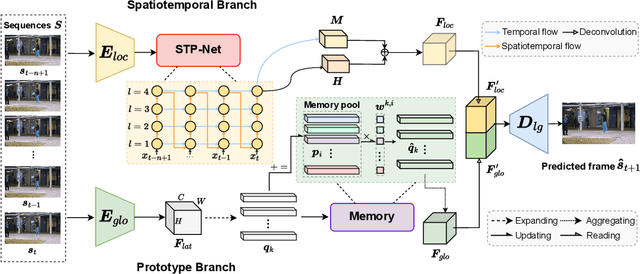
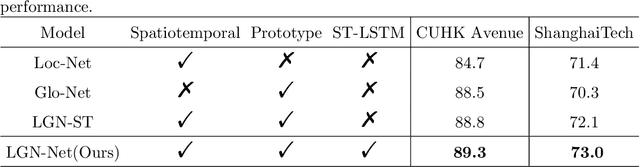
Video anomaly detection (VAD) has been intensively studied for years because of its potential applications in intelligent video systems. Existing unsupervised VAD methods tend to learn normality from training sets consisting of only normal videos and regard instances deviating from such normality as anomalies. However, they often consider only local or global normality. Some of them focus on learning local spatiotemporal representations from consecutive frames in video clips to enhance the representation for normal events. But powerful representation allows these methods to represent some anomalies and causes missed detections. In contrast, the other methods are devoted to memorizing global prototypical patterns of whole training videos to weaken the generalization for anomalies, which also restricts them to represent diverse normal patterns and causes false alarms. To this end, we propose a two-branch model, Local-Global Normality Network (LGN-Net), to learn local and global normality simultaneously. Specifically, one branch learns the evolution regularities of appearance and motion from consecutive frames as local normality utilizing a spatiotemporal prediction network, while the other branch memorizes prototype features of the whole videos as global normality by a memory module. LGN-Net achieves a balance of representing normal and abnormal instances by fusing local and global normality. The fused normality enables our model more generalized to various scenes compared to exploiting single normality. Experiments demonstrate the effectiveness and superior performance of our method. The code is available online: https://github.com/Myzhao1999/LGN-Net.