 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRTSearch: Unified Detection and Parameter Inference of Fast Radio Transients using Instance Segmentation
Apr 14, 2026The exponential growth of data from modern radio telescopes presents a significant challenge to traditional single-pulse search algorithms, which are computationally intensive and prone to high false-positive rates due to Radio Frequency Interference (RFI). In this work, we introduce FRTSearch, an end-to-end framework unifying the detection and physical characterization of Fast Radio Transients (FRTs). Leveraging the morphological universality of dispersive trajectories in time-frequency dynamic spectra, we reframe FRT detection as a pattern recognition problem governed by the cold plasma dispersion relation. To facilitate this, we constructed CRAFTS-FRT, a pixel-level annotated dataset derived from the Commensal Radio Astronomy FAST Survey (CRAFTS), comprising 2{,}392 instances across diverse source classes. This dataset enables the training of a Mask R-CNN model for precise trajectory segmentation. Coupled with our physics-driven IMPIC algorithm, the framework maps the geometric coordinates of segmented trajectories to directly infer the Dispersion Measure (DM) and Time of Arrival (ToA). Benchmarking on the FAST-FREX dataset shows that FRTSearch achieves a 98.0\% recall, competitive with exhaustive search methods, while reducing false positives by over 99.9\% compared to PRESTO and delivering a processing speedup of up to $13.9\times$. Furthermore, the framework demonstrates robust cross-facility generalization, detecting all 19 tested FRBs from the ASKAP survey without retraining. By shifting the paradigm from ``search-then-identify'' to ``detect-and-infer,'' FRTSearch provides a scalable, high-precision solution for real-time discovery in the era of petabyte-scale radio astronomy.
A3R: Agentic Affordance Reasoning via Cross-Dimensional Evidence in 3D Gaussian Scenes
Apr 02, 2026Affordance reasoning in 3D Gaussian scenes aims to identify the region that supports the action specified by a given text instruction in complex environments. Existing methods typically cast this problem as one-shot prediction from static scene observations, assuming sufficient evidence is already available for reasoning. However, in complex 3D scenes, many failure cases arise not from weak prediction capacity, but from incomplete task-relevant evidence under fixed observations. To address this limitation, we reformulate fine-grained affordance reasoning as a sequential evidence acquisition process, where ambiguity is progressively reduced through complementary 3D geometric and 2D semantic evidence. Building on this formulation, we propose A3R, an agentic affordance reasoning framework that enables an MLLM-based policy to iteratively select evidence acquisition actions and update the affordance belief through cross-dimensional evidence acquisition. To optimize such sequential decision making, we further introduce a GRPO-based policy learning strategy that improves evidence acquisition efficiency and reasoning accuracy. Extensive experiments on scene-level benchmarks show that A3R consistently surpasses static one-shot baselines, demonstrating the advantage of agentic cross-dimensional evidence acquisition for fine-grained affordance reasoning in complex 3D Gaussian scenes.
Are VLMs Lost Between Sky and Space? LinkS$^2$Bench for UAV-Satellite Dynamic Cross-View Spatial Intelligence
Apr 02, 2026Synergistic spatial intelligence between UAVs and satellites is indispensable for emergency response and security operations, as it uniquely integrates macro-scale global coverage with dynamic, real-time local perception. However, the capacity of Vision-Language Models (VLMs) to master this complex interplay remains largely unexplored. This gap persists primarily because existing benchmarks are confined to isolated Unmanned Aerial Vehicle (UAV) videos or static satellite imagery, failing to evaluate the dynamic local-to-global spatial mapping essential for comprehensive cross-view reasoning. To bridge this gap, we introduce LinkS$^2$Bench, the first comprehensive benchmark designed to evaluate VLMs' wide-area, dynamic cross-view spatial intelligence. LinkS$^2$Bench links 1,022 minutes of dynamic UAV footage with high-resolution satellite imagery covering over 200 km$^2$. Through an LMM-assisted pipeline and rigorous human annotation, we constructed 17.9k high-quality question-answer pairs comprising 12 fine-grained tasks across four dimensions: perception, localization, relation, and reasoning. Evaluations of 18 representative VLMs reveal a substantial gap compared to human baselines, identifying accurate cross-view dynamic alignment as the critical bottleneck. To alleviate this, we design a Cross-View Alignment Adapter, demonstrating that explicit alignment significantly improves model performance. Furthermore, fine-tuning experiments underscore the potential of LinkS$^2$Bench in advancing VLM adaptation for complex spatial reasoning.
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Jul 31, 20253D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.
Feature Calibration enhanced Parameter Synthesis for CLIP-based Class-incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables models to continuously learn new class knowledge while memorizing previous classes, facilitating their adaptation and evolution in dynamic environments. Traditional CIL methods are mainly based on visual features, which limits their ability to handle complex scenarios. In contrast, Vision-Language Models (VLMs) show promising potential to promote CIL by integrating pretrained knowledge with textual features. However, previous methods make it difficult to overcome catastrophic forgetting while preserving the generalization capabilities of VLMs. To tackle these challenges, we propose Feature Calibration enhanced Parameter Synthesis (FCPS) in this paper. Specifically, our FCPS employs a specific parameter adjustment mechanism to iteratively refine the proportion of original visual features participating in the final class determination, ensuring the model's foundational generalization capabilities. Meanwhile, parameter integration across different tasks achieves a balance between learning new class knowledge and retaining old knowledge. Experimental results on popular benchmarks (e.g., CIFAR100 and ImageNet100) validate the superiority of the proposed method.
EgoSplat: Open-Vocabulary Egocentric Scene Understanding with Language Embedded 3D Gaussian Splatting
Mar 14, 2025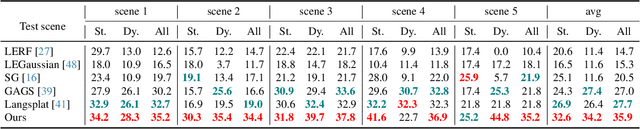
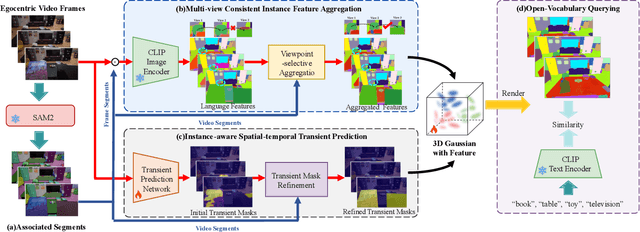
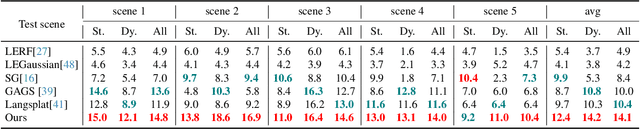
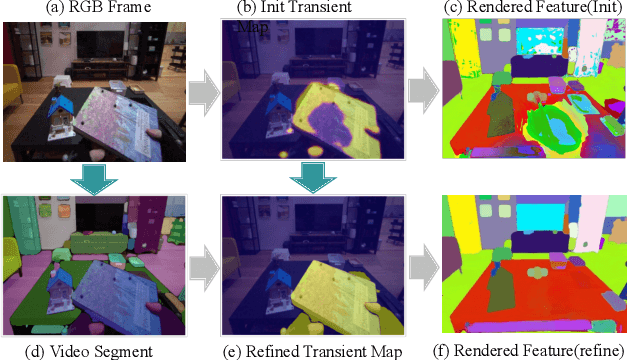
Egocentric scenes exhibit frequent occlusions, varied viewpoints, and dynamic interactions compared to typical scene understanding tasks. Occlusions and varied viewpoints can lead to multi-view semantic inconsistencies, while dynamic objects may act as transient distractors, introducing artifacts into semantic feature modeling. To address these challenges, we propose EgoSplat, a language-embedded 3D Gaussian Splatting framework for open-vocabulary egocentric scene understanding. A multi-view consistent instance feature aggregation method is designed to leverage the segmentation and tracking capabilities of SAM2 to selectively aggregate complementary features across views for each instance, ensuring precise semantic representation of scenes. Additionally, an instance-aware spatial-temporal transient prediction module is constructed to improve spatial integrity and temporal continuity in predictions by incorporating spatial-temporal associations across multi-view instances, effectively reducing artifacts in the semantic reconstruction of egocentric scenes. EgoSplat achieves state-of-the-art performance in both localization and segmentation tasks on two datasets, outperforming existing methods with a 8.2% improvement in localization accuracy and a 3.7% improvement in segmentation mIoU on the ADT dataset, and setting a new benchmark in open-vocabulary egocentric scene understanding. The code will be made publicly available.
Multi-Teacher Multi-Objective Meta-Learning for Zero-Shot Hyperspectral Band Selection
Jun 12, 2024



Band selection plays a crucial role in hyperspectral image classification by removing redundant and noisy bands and retaining discriminative ones. However, most existing deep learning-based methods are aimed at dealing with a specific band selection dataset, and need to retrain parameters for new datasets, which significantly limits their generalizability.To address this issue, a novel multi-teacher multi-objective meta-learning network (M$^3$BS) is proposed for zero-shot hyperspectral band selection. In M$^3$BS, a generalizable graph convolution network (GCN) is constructed to generate dataset-agnostic base, and extract compatible meta-knowledge from multiple band selection tasks. To enhance the ability of meta-knowledge extraction, multiple band selection teachers are introduced to provide diverse high-quality experiences.strategy Finally, subsequent classification tasks are attached and jointly optimized with multi-teacher band selection tasks through multi-objective meta-learning in an end-to-end trainable way. Multi-objective meta-learning guarantees to coordinate diverse optimization objectives automatically and adapt to various datasets simultaneously. Once the optimization is accomplished, the acquired meta-knowledge can be directly transferred to unseen datasets without any retraining or fine-tuning. Experimental results demonstrate the effectiveness and efficiency of our proposed method on par with state-of-the-art baselines for zero-shot hyperspectral band selection.
Automated Identification and Segmentation of Hi Sources in CRAFTS Using Deep Learning Method
Mar 29, 2024



We introduce a machine learning-based method for extracting HI sources from 3D spectral data, and construct a dedicated dataset of HI sources from CRAFTS. Our custom dataset provides comprehensive resources for HI source detection. Utilizing the 3D-Unet segmentation architecture, our method reliably identifies and segments HI sources, achieving notable performance metrics with recall rates reaching 91.6% and accuracy levels at 95.7%. These outcomes substantiate the value of our custom dataset and the efficacy of our proposed network in identifying HI source. Our code is publicly available at https://github.com/fishszh/HISF.
Deep Learning for Day Forecasts from Sparse Observations
Jun 12, 2023



Deep neural networks offer an alternative paradigm for modeling weather conditions. The ability of neural models to make a prediction in less than a second once the data is available and to do so with very high temporal and spatial resolution, and the ability to learn directly from atmospheric observations, are just some of these models' unique advantages. Neural models trained using atmospheric observations, the highest fidelity and lowest latency data, have to date achieved good performance only up to twelve hours of lead time when compared with state-of-the-art probabilistic Numerical Weather Prediction models and only for the sole variable of precipitation. In this paper, we present MetNet-3 that extends significantly both the lead time range and the variables that an observation based neural model can predict well. MetNet-3 learns from both dense and sparse data sensors and makes predictions up to 24 hours ahead for precipitation, wind, temperature and dew point. MetNet-3 introduces a key densification technique that implicitly captures data assimilation and produces spatially dense forecasts in spite of the network training on extremely sparse targets. MetNet-3 has a high temporal and spatial resolution of, respectively, up to 2 minutes and 1 km as well as a low operational latency. We find that MetNet-3 is able to outperform the best single- and multi-member NWPs such as HRRR and ENS over the CONUS region for up to 24 hours ahead setting a new performance milestone for observation based neural models. MetNet-3 is operational and its forecasts are served in Google Search in conjunction with other models.
GAS: A Gaussian Mixture Distribution-Based Adaptive Sampling Method for PINNs
Apr 07, 2023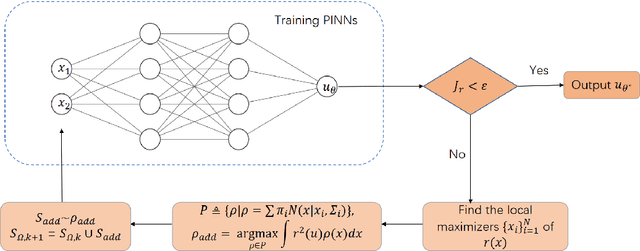

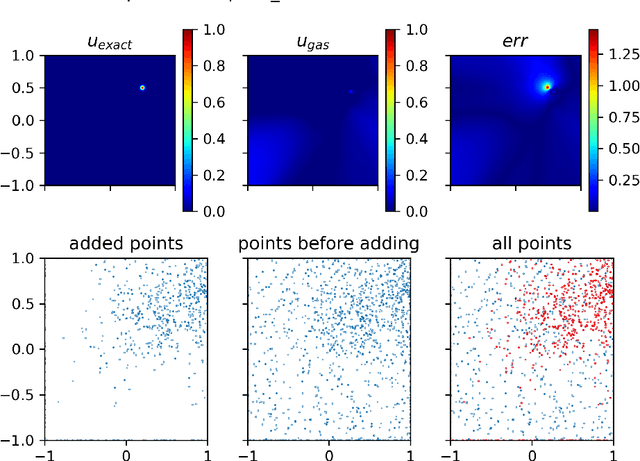

With the recent study of deep learning in scientific computation, the Physics-Informed Neural Networks (PINNs) method has drawn widespread attention for solving Partial Differential Equations (PDEs). Compared to traditional methods, PINNs can efficiently handle high-dimensional problems, but the accuracy is relatively low, especially for highly irregular problems. Inspired by the idea of adaptive finite element methods and incremental learning, we propose GAS, a Gaussian mixture distribution-based adaptive sampling method for PINNs. During the training procedure, GAS uses the current residual information to generate a Gaussian mixture distribution for the sampling of additional points, which are then trained together with historical data to speed up the convergence of the loss and achieve higher accuracy. Several numerical simulations on 2D and 10D problems show that GAS is a promising method that achieves state-of-the-art accuracy among deep solvers, while being comparable with traditional numerical solvers.