 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheta-regularized Kriging: Modelling and Algorithms
Apr 16, 2026To obtain more accurate model parameters and improve prediction accuracy, we proposed a regularized Kriging model that penalizes the hyperparameter theta in the Gaussian stochastic process, termed the Theta-regularized Kriging. We derived the optimization problem for this model from a maximum likelihood perspective. Additionally, we presented specific implementation details for the iterative process, including the regularized optimization algorithm and the geometric search cross-validation tuning algorithm. Three distinct penalty methods, Lasso, Ridge, and Elastic-net regularization, were meticulously considered. Meanwhile, the proposed Theta-regularized Kriging models were tested on nine common numerical functions and two practical engineering examples. The results demonstrate that, compared with other penalized Kriging models, the proposed model performs better in terms of accuracy and stability.
Spatial-Spectral Adaptive Fidelity and Noise Prior Reduction Guided Hyperspectral Image Denoising
Apr 14, 2026The core challenge of hyperspectral image denoising is striking the right balance between data fidelity and noise prior modeling. Most existing methods place too much emphasis on the intrinsic priors of the image while overlooking diverse noise assumptions and the dynamic trade-off between fidelity and priors. To address these issues, we propose a denoising framework that integrates noise prior reduction and a spatial-spectral adaptive fidelity term. This framework considers comprehensive noise priors with fewer parameters and introduces an adaptive weight tensor to dynamically balance the fidelity and prior regularization terms. Within this framework, we further develop a fast and robust pixel-wise model combined with the representative coefficient total variation regularizer to accurately remove mixed noise in HSIs. The proposed method not only efficiently handles various types of noise but also accurately captures the spectral low-rank structure and local smoothness of HSIs. An efficient optimization algorithm based on the alternating direction method of multipliers is designed to ensure stable and fast convergence. Extensive experiments on simulated and real-world datasets demonstrate that the proposed model achieves superior denoising performance while maintaining competitive computational efficiency.
Quantum Compiling with Reinforcement Learning on a Superconducting Processor
Jun 18, 2024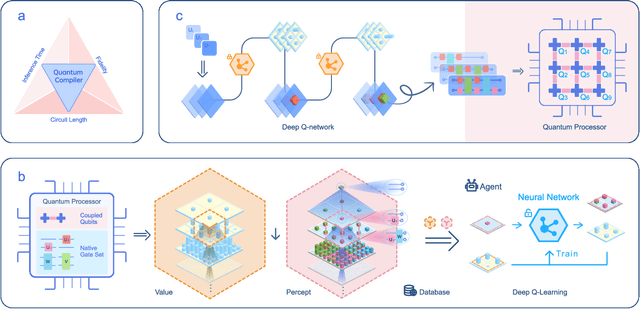

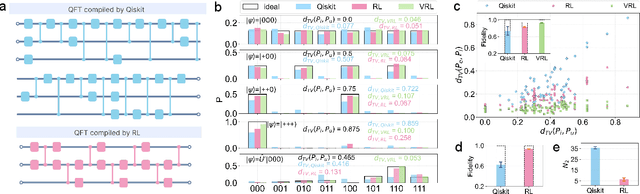
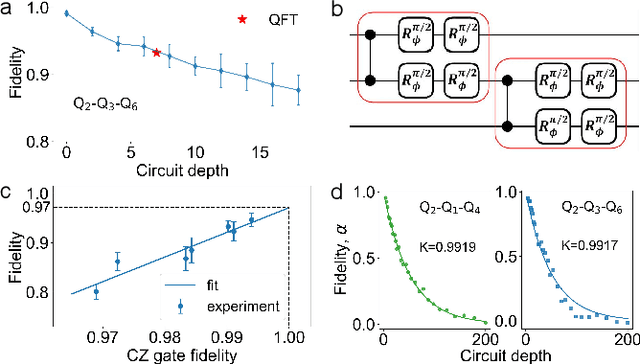
To effectively implement quantum algorithms on noisy intermediate-scale quantum (NISQ) processors is a central task in modern quantum technology. NISQ processors feature tens to a few hundreds of noisy qubits with limited coherence times and gate operations with errors, so NISQ algorithms naturally require employing circuits of short lengths via quantum compilation. Here, we develop a reinforcement learning (RL)-based quantum compiler for a superconducting processor and demonstrate its capability of discovering novel and hardware-amenable circuits with short lengths. We show that for the three-qubit quantum Fourier transformation, a compiled circuit using only seven CZ gates with unity circuit fidelity can be achieved. The compiler is also able to find optimal circuits under device topological constraints, with lengths considerably shorter than those by the conventional method. Our study exemplifies the codesign of the software with hardware for efficient quantum compilation, offering valuable insights for the advancement of RL-based compilers.
Accelerating Ill-conditioned Hankel Matrix Recovery via Structured Newton-like Descent
Jun 11, 2024



This paper studies the robust Hankel recovery problem, which simultaneously removes the sparse outliers and fulfills missing entries from the partial observation. We propose a novel non-convex algorithm, coined Hankel Structured Newton-Like Descent (HSNLD), to tackle the robust Hankel recovery problem. HSNLD is highly efficient with linear convergence, and its convergence rate is independent of the condition number of the underlying Hankel matrix. The recovery guarantee has been established under some mild conditions. Numerical experiments on both synthetic and real datasets show the superior performance of HSNLD against state-of-the-art algorithms.
Take Care of Your Prompt Bias! Investigating and Mitigating Prompt Bias in Factual Knowledge Extraction
Mar 26, 2024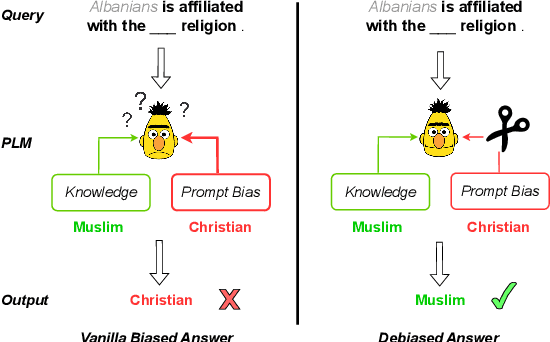
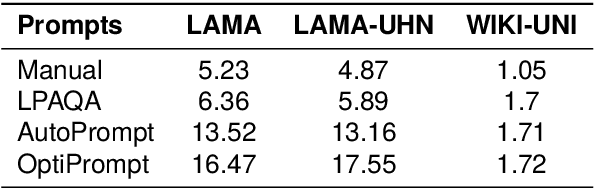
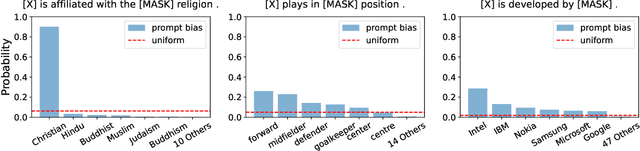
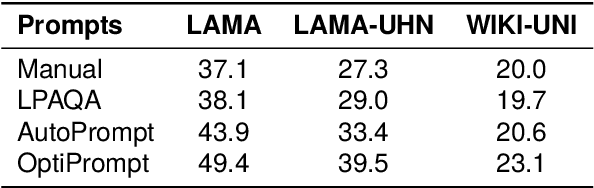
Recent research shows that pre-trained language models (PLMs) suffer from "prompt bias" in factual knowledge extraction, i.e., prompts tend to introduce biases toward specific labels. Prompt bias presents a significant challenge in assessing the factual knowledge within PLMs. Therefore, this paper aims to improve the reliability of existing benchmarks by thoroughly investigating and mitigating prompt bias. We show that: 1) all prompts in the experiments exhibit non-negligible bias, with gradient-based prompts like AutoPrompt and OptiPrompt displaying significantly higher levels of bias; 2) prompt bias can amplify benchmark accuracy unreasonably by overfitting the test datasets, especially on imbalanced datasets like LAMA. Based on these findings, we propose a representation-based approach to mitigate the prompt bias during inference time. Specifically, we first estimate the biased representation using prompt-only querying, and then remove it from the model's internal representations to generate the debiased representations, which are used to produce the final debiased outputs. Experiments across various prompts, PLMs, and benchmarks show that our approach can not only correct the overfitted performance caused by prompt bias, but also significantly improve the prompt retrieval capability (up to 10% absolute performance gain). These results indicate that our approach effectively alleviates prompt bias in knowledge evaluation, thereby enhancing the reliability of benchmark assessments. Hopefully, our plug-and-play approach can be a golden standard to strengthen PLMs toward reliable knowledge bases. Code and data are released in https://github.com/FelliYang/PromptBias.
Neural Network Approximation for Pessimistic Offline Reinforcement Learning
Dec 19, 2023



Deep reinforcement learning (RL) has shown remarkable success in specific offline decision-making scenarios, yet its theoretical guarantees are still under development. Existing works on offline RL theory primarily emphasize a few trivial settings, such as linear MDP or general function approximation with strong assumptions and independent data, which lack guidance for practical use. The coupling of deep learning and Bellman residuals makes this problem challenging, in addition to the difficulty of data dependence. In this paper, we establish a non-asymptotic estimation error of pessimistic offline RL using general neural network approximation with $\mathcal{C}$-mixing data regarding the structure of networks, the dimension of datasets, and the concentrability of data coverage, under mild assumptions. Our result shows that the estimation error consists of two parts: the first converges to zero at a desired rate on the sample size with partially controllable concentrability, and the second becomes negligible if the residual constraint is tight. This result demonstrates the explicit efficiency of deep adversarial offline RL frameworks. We utilize the empirical process tool for $\mathcal{C}$-mixing sequences and the neural network approximation theory for the H\"{o}lder class to achieve this. We also develop methods to bound the Bellman estimation error caused by function approximation with empirical Bellman constraint perturbations. Additionally, we present a result that lessens the curse of dimensionality using data with low intrinsic dimensionality and function classes with low complexity. Our estimation provides valuable insights into the development of deep offline RL and guidance for algorithm model design.
Provable Advantage of Parameterized Quantum Circuit in Function Approximation
Oct 11, 2023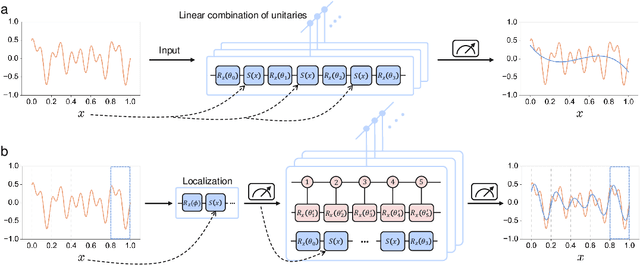
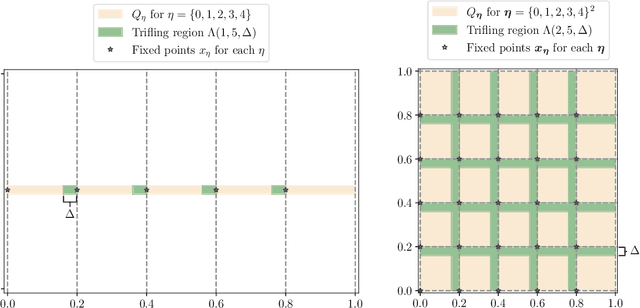
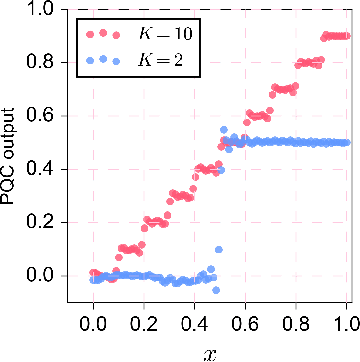
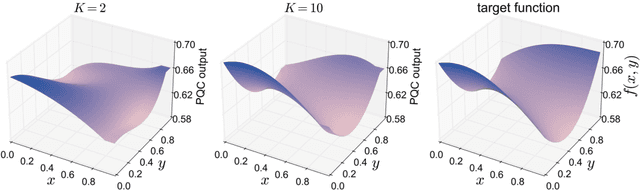
Understanding the power of parameterized quantum circuits (PQCs) in accomplishing machine learning tasks is one of the most important questions in quantum machine learning. In this paper, we analyze the expressivity of PQCs through the lens of function approximation. Previously established universal approximation theorems for PQCs are mainly nonconstructive, leading us to the following question: How large do the PQCs need to be to approximate the target function up to a given error? We exhibit explicit constructions of data re-uploading PQCs for approximating continuous and smooth functions and establish quantitative approximation error bounds in terms of the width, the depth and the number of trainable parameters of the PQCs. To achieve this, we utilize techniques from quantum signal processing and linear combinations of unitaries to construct PQCs that implement multivariate polynomials. We implement global and local approximation techniques using Bernstein polynomials and local Taylor expansion and analyze their performances in the quantum setting. We also compare our proposed PQCs to nearly optimal deep neural networks in approximating high-dimensional smooth functions, showing that the ratio between model sizes of PQC and deep neural networks is exponentially small with respect to the input dimension. This suggests a potentially novel avenue for showcasing quantum advantages in quantum machine learning.
Current density impedance imaging with PINNs
Jun 24, 2023In this paper, we introduce CDII-PINNs, a computationally efficient method for solving CDII using PINNs in the framework of Tikhonov regularization. This method constructs a physics-informed loss function by merging the regularized least-squares output functional with an underlying differential equation, which describes the relationship between the conductivity and voltage. A pair of neural networks representing the conductivity and voltage, respectively, are coupled by this loss function. Then, minimizing the loss function provides a reconstruction. A rigorous theoretical guarantee is provided. We give an error analysis for CDII-PINNs and establish a convergence rate, based on prior selected neural network parameters in terms of the number of samples. The numerical simulations demonstrate that CDII-PINNs are efficient, accurate and robust to noise levels ranging from $1\%$ to $20\%$.
GAS: A Gaussian Mixture Distribution-Based Adaptive Sampling Method for PINNs
Apr 07, 2023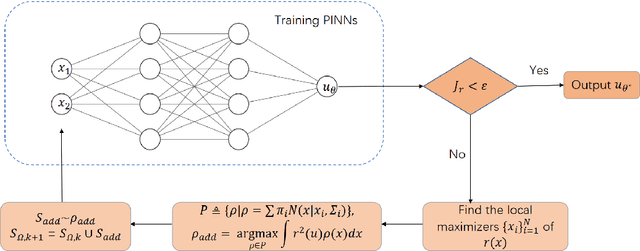

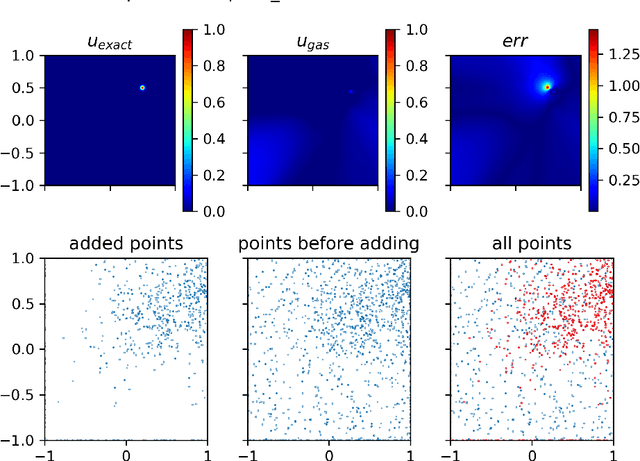

With the recent study of deep learning in scientific computation, the Physics-Informed Neural Networks (PINNs) method has drawn widespread attention for solving Partial Differential Equations (PDEs). Compared to traditional methods, PINNs can efficiently handle high-dimensional problems, but the accuracy is relatively low, especially for highly irregular problems. Inspired by the idea of adaptive finite element methods and incremental learning, we propose GAS, a Gaussian mixture distribution-based adaptive sampling method for PINNs. During the training procedure, GAS uses the current residual information to generate a Gaussian mixture distribution for the sampling of additional points, which are then trained together with historical data to speed up the convergence of the loss and achieve higher accuracy. Several numerical simulations on 2D and 10D problems show that GAS is a promising method that achieves state-of-the-art accuracy among deep solvers, while being comparable with traditional numerical solvers.
Imaging Conductivity from Current Density Magnitude using Neural Networks
Apr 18, 2022
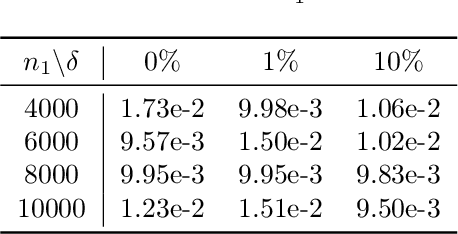
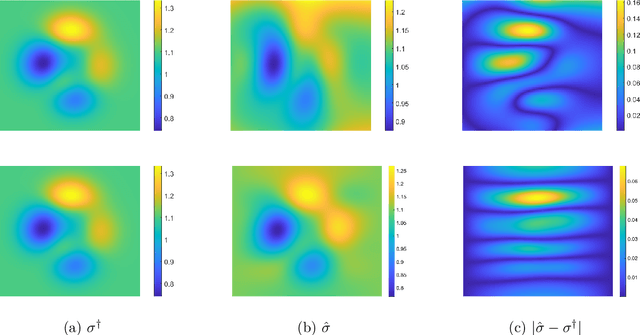
Conductivity imaging represents one of the most important tasks in medical imaging. In this work we develop a neural network based reconstruction technique for imaging the conductivity from the magnitude of the internal current density. It is achieved by formulating the problem as a relaxed weighted least-gradient problem, and then approximating its minimizer by standard fully connected feedforward neural networks. We derive bounds on two components of the generalization error, i.e., approximation error and statistical error, explicitly in terms of properties of the neural networks (e.g., depth, total number of parameters, and the bound of the network parameters). We illustrate the performance and distinct features of the approach on several numerical experiments. Numerically, it is observed that the approach enjoys remarkable robustness with respect to the presence of data noise.