 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Model for Manifold Data: Score Decomposition, Curvature, and Statistical Complexity
Mar 21, 2026Diffusion models have become a leading framework in generative modeling, yet their theoretical understanding -- especially for high-dimensional data concentrated on low-dimensional structures -- remains incomplete. This paper investigates how diffusion models learn such structured data, focusing on two key aspects: statistical complexity and influence of data geometric properties. By modeling data as samples from a smooth Riemannian manifold, our analysis reveals crucial decompositions of score functions in diffusion models under different levels of injected noise. We also highlight the interplay of manifold curvature with the structures in the score function. These analyses enable an efficient neural network approximation to the score function, built upon which we further provide statistical rates for score estimation and distribution learning. Remarkably, the obtained statistical rates are governed by the intrinsic dimension of data and the manifold curvature. These results advance the statistical foundations of diffusion models, bridging theory and practice for generative modeling on manifolds.
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
May 26, 2025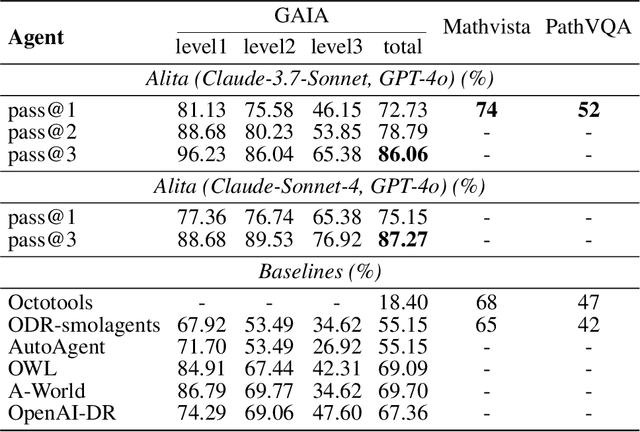
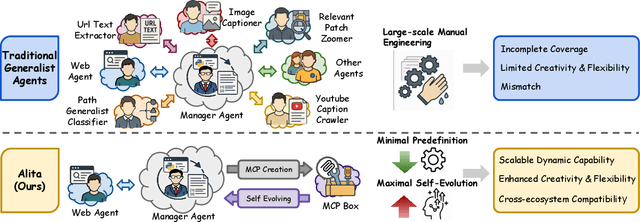
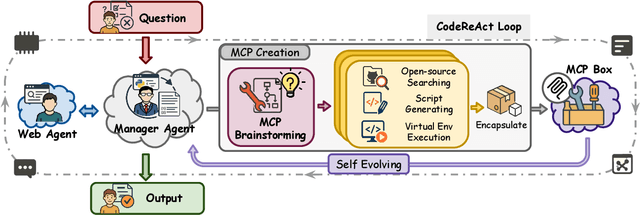

Recent advances in large language models (LLMs) have enabled agents to autonomously perform complex, open-ended tasks. However, many existing frameworks depend heavily on manually predefined tools and workflows, which hinder their adaptability, scalability, and generalization across domains. In this work, we introduce Alita--a generalist agent designed with the principle of "Simplicity is the ultimate sophistication," enabling scalable agentic reasoning through minimal predefinition and maximal self-evolution. For minimal predefinition, Alita is equipped with only one component for direct problem-solving, making it much simpler and neater than previous approaches that relied heavily on hand-crafted, elaborate tools and workflows. This clean design enhances its potential to generalize to challenging questions, without being limited by tools. For Maximal self-evolution, we enable the creativity of Alita by providing a suite of general-purpose components to autonomously construct, refine, and reuse external capabilities by generating task-related model context protocols (MCPs) from open source, which contributes to scalable agentic reasoning. Notably, Alita achieves 75.15% pass@1 and 87.27% pass@3 accuracy, which is top-ranking among general-purpose agents, on the GAIA benchmark validation dataset, 74.00% and 52.00% pass@1, respectively, on Mathvista and PathVQA, outperforming many agent systems with far greater complexity. More details will be updated at $\href{https://github.com/CharlesQ9/Alita}{https://github.com/CharlesQ9/Alita}$.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Large Wireless Localization Model (LWLM): A Foundation Model for Positioning in 6G Networks
May 15, 2025



Accurate and robust localization is a critical enabler for emerging 5G and 6G applications, including autonomous driving, extended reality (XR), and smart manufacturing. While data-driven approaches have shown promise, most existing models require large amounts of labeled data and struggle to generalize across deployment scenarios and wireless configurations. To address these limitations, we propose a foundation-model-based solution tailored for wireless localization. We first analyze how different self-supervised learning (SSL) tasks acquire general-purpose and task-specific semantic features based on information bottleneck (IB) theory. Building on this foundation, we design a pretraining methodology for the proposed Large Wireless Localization Model (LWLM). Specifically, we propose an SSL framework that jointly optimizes three complementary objectives: (i) spatial-frequency masked channel modeling (SF-MCM), (ii) domain-transformation invariance (DTI), and (iii) position-invariant contrastive learning (PICL). These objectives jointly capture the underlying semantics of wireless channel from multiple perspectives. We further design lightweight decoders for key downstream tasks, including time-of-arrival (ToA) estimation, angle-of-arrival (AoA) estimation, single base station (BS) localization, and multiple BS localization. Comprehensive experimental results confirm that LWLM consistently surpasses both model-based and supervised learning baselines across all localization tasks. In particular, LWLM achieves 26.0%--87.5% improvement over transformer models without pretraining, and exhibits strong generalization under label-limited fine-tuning and unseen BS configurations, confirming its potential as a foundation model for wireless localization.
Temporal Consistency for LLM Reasoning Process Error Identification
Mar 18, 2025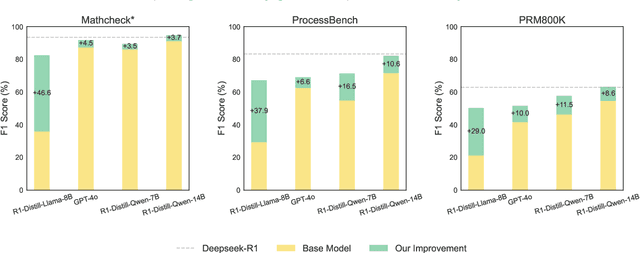



Verification is crucial for effective mathematical reasoning. We present a new temporal consistency method where verifiers iteratively refine their judgments based on the previous assessment. Unlike one-round verification or multi-model debate approaches, our method leverages consistency in a sequence of self-reflection actions to improve verification accuracy. Empirical evaluations across diverse mathematical process error identification benchmarks (Mathcheck, ProcessBench, and PRM800K) show consistent performance improvements over baseline methods. When applied to the recent DeepSeek R1 distilled models, our method demonstrates strong performance, enabling 7B/8B distilled models to outperform all 70B/72B models and GPT-4o on ProcessBench. Notably, the distilled 14B model with our method achieves performance comparable to Deepseek-R1. Our codes are available at https://github.com/jcguo123/Temporal-Consistency
Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models
Feb 27, 2025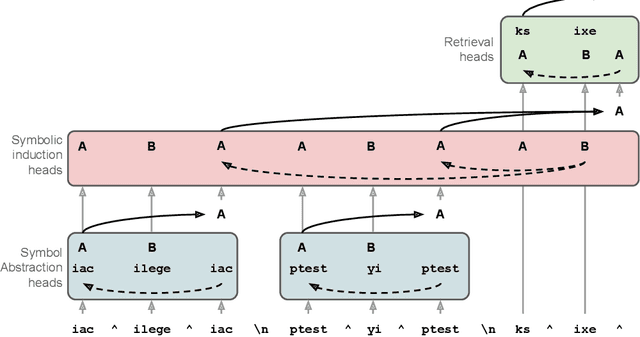
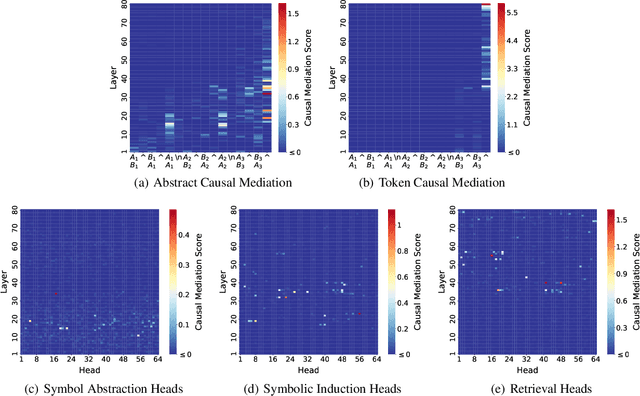
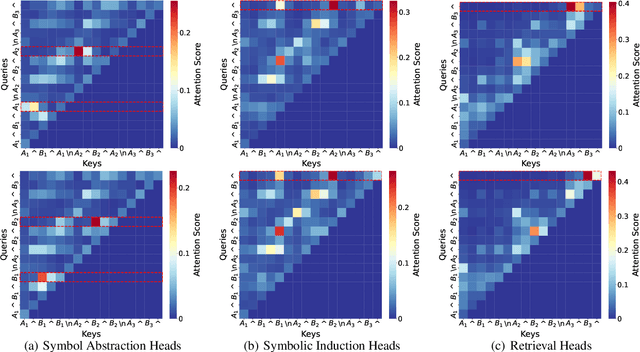
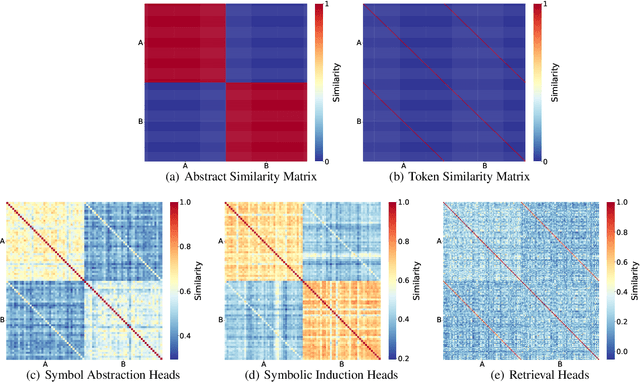
Many recent studies have found evidence for emergent reasoning capabilities in large language models, but debate persists concerning the robustness of these capabilities, and the extent to which they depend on structured reasoning mechanisms. To shed light on these issues, we perform a comprehensive study of the internal mechanisms that support abstract rule induction in an open-source language model (Llama3-70B). We identify an emergent symbolic architecture that implements abstract reasoning via a series of three computations. In early layers, symbol abstraction heads convert input tokens to abstract variables based on the relations between those tokens. In intermediate layers, symbolic induction heads perform sequence induction over these abstract variables. Finally, in later layers, retrieval heads predict the next token by retrieving the value associated with the predicted abstract variable. These results point toward a resolution of the longstanding debate between symbolic and neural network approaches, suggesting that emergent reasoning in neural networks depends on the emergence of symbolic mechanisms.
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations
Feb 10, 2025



Large language models have demonstrated impressive performance on challenging mathematical reasoning tasks, which has triggered the discussion of whether the performance is achieved by true reasoning capability or memorization. To investigate this question, prior work has constructed mathematical benchmarks when questions undergo simple perturbations -- modifications that still preserve the underlying reasoning patterns of the solutions. However, no work has explored hard perturbations, which fundamentally change the nature of the problem so that the original solution steps do not apply. To bridge the gap, we construct MATH-P-Simple and MATH-P-Hard via simple perturbation and hard perturbation, respectively. Each consists of 279 perturbed math problems derived from level-5 (hardest) problems in the MATH dataset (Hendrycksmath et. al., 2021). We observe significant performance drops on MATH-P-Hard across various models, including o1-mini (-16.49%) and gemini-2.0-flash-thinking (-12.9%). We also raise concerns about a novel form of memorization where models blindly apply learned problem-solving skills without assessing their applicability to modified contexts. This issue is amplified when using original problems for in-context learning. We call for research efforts to address this challenge, which is critical for developing more robust and reliable reasoning models.
A Theoretical Perspective for Speculative Decoding Algorithm
Oct 30, 2024



Transformer-based autoregressive sampling has been the major bottleneck for slowing down large language model inferences. One effective way to accelerate inference is \emph{Speculative Decoding}, which employs a small model to sample a sequence of draft tokens and a large model to validate. Given its empirical effectiveness, the theoretical understanding of Speculative Decoding is falling behind. This paper tackles this gap by conceptualizing the decoding problem via markov chain abstraction and studying the key properties, \emph{output quality and inference acceleration}, from a theoretical perspective. Our analysis covers the theoretical limits of speculative decoding, batch algorithms, and output quality-inference acceleration tradeoffs. Our results reveal the fundamental connections between different components of LLMs via total variation distances and show how they jointly affect the efficiency of decoding algorithms.
TreeBoN: Enhancing Inference-Time Alignment with Speculative Tree-Search and Best-of-N Sampling
Oct 18, 2024

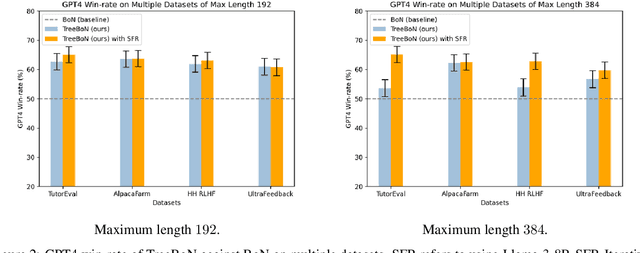

Inference-time alignment enhances the performance of large language models without requiring additional training or fine-tuning but presents challenges due to balancing computational efficiency with high-quality output. Best-of-N (BoN) sampling, as a simple yet powerful approach, generates multiple responses and selects the best one, achieving improved performance but with a high computational cost. We propose TreeBoN, a novel framework that integrates a speculative tree-search strategy into Best-of-N (BoN) Sampling. TreeBoN maintains a set of parent nodes, iteratively branching and pruning low-quality responses, thereby reducing computational overhead while maintaining high output quality. Our approach also leverages token-level rewards from Direct Preference Optimization (DPO) to guide tree expansion and prune low-quality paths. We evaluate TreeBoN using AlpacaFarm, UltraFeedback, GSM8K, HH-RLHF, and TutorEval datasets, demonstrating consistent improvements. Specifically, TreeBoN achieves a 65% win rate at maximum lengths of 192 and 384 tokens, outperforming standard BoN with the same computational cost. Furthermore, TreeBoN achieves around a 60% win rate across longer responses, showcasing its scalability and alignment efficacy.
Latent Diffusion Models for Controllable RNA Sequence Generation
Sep 15, 2024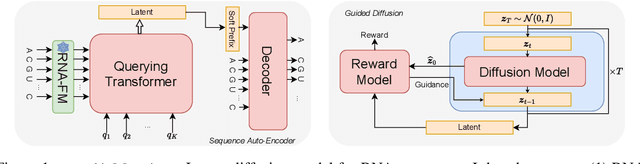
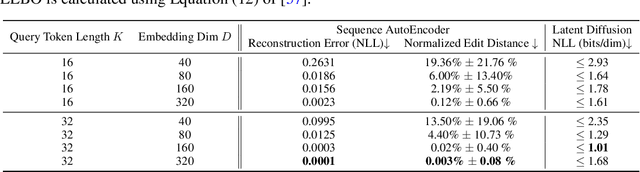

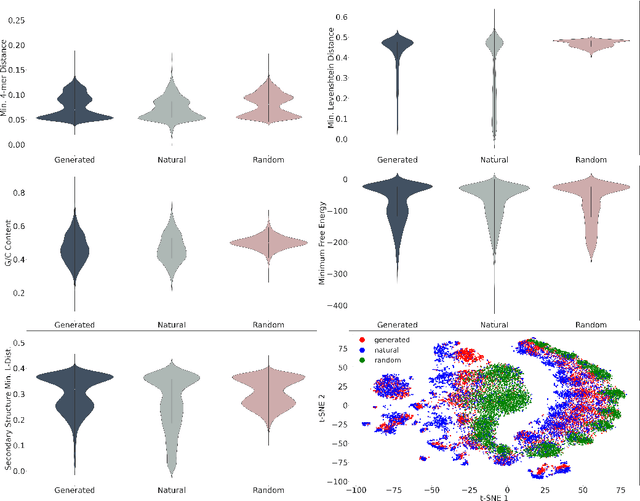
This paper presents RNAdiffusion, a latent diffusion model for generating and optimizing discrete RNA sequences. RNA is a particularly dynamic and versatile molecule in biological processes. RNA sequences exhibit high variability and diversity, characterized by their variable lengths, flexible three-dimensional structures, and diverse functions. We utilize pretrained BERT-type models to encode raw RNAs into token-level biologically meaningful representations. A Q-Former is employed to compress these representations into a fixed-length set of latent vectors, with an autoregressive decoder trained to reconstruct RNA sequences from these latent variables. We then develop a continuous diffusion model within this latent space. To enable optimization, we train reward networks to estimate functional properties of RNA from the latent variables. We employ gradient-based guidance during the backward diffusion process, aiming to generate RNA sequences that are optimized for higher rewards. Empirical experiments confirm that RNAdiffusion generates non-coding RNAs that align with natural distributions across various biological indicators. We fine-tuned the diffusion model on untranslated regions (UTRs) of mRNA and optimize sample sequences for protein translation efficiencies. Our guided diffusion model effectively generates diverse UTR sequences with high Mean Ribosome Loading (MRL) and Translation Efficiency (TE), surpassing baselines. These results hold promise for studies on RNA sequence-function relationships, protein synthesis, and enhancing therapeutic RNA design.