 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
May 22, 2026Multi-agent LLM workflows route inference through specialized roles to lift end-task accuracy, but jointly training those roles with reinforcement learning is unstable in ways that are poorly understood. We study when end-to-end RL training of multi-agent LLM workflows improves over their base models, comparing Shared-Policy training, where all roles update one policy, with Isolated-Policy training, where each role has its own parameters. Our experimental matrix spans Eval-Opt, Voting, and Orch-Workers workflows, math and code tasks, and three model scales (0.6B, 1.7B, 4B). We find that multi-agent RL usually improves over base models, but gains depend jointly on workflow, task, and scale, not on policy sharing alone. Isolated-Policy tends to reach higher peak accuracy yet more often falls off a terminal accuracy cliff, while Shared-Policy training does not eliminate failure; it redistributes failure into qualitatively different patterns. We then explain the strongest of these patterns through role-level gradient dynamics induced by workflow topology and policy routing: under Isolated-Policy, parallel same-role agents on shared prompts amplify per-role gradients and drive terminal degradation in Voting and Orch-Workers workflows; under Shared-Policy, asymmetric per-step gradient mass causes the shared policy to be captured by the dominant role, producing different failure signatures by task and workflow. Together, the empirical map and its underlying mechanisms show that policy sharing routes training pressure through different channels rather than offering uniform stability, making it a design choice with workflow- and task-conditional tradeoffs.
WebGraphEval: Multi-Turn Trajectory Evaluation for Web Agents using Graph Representation
Oct 22, 2025Current evaluation of web agents largely reduces to binary success metrics or conformity to a single reference trajectory, ignoring the structural diversity present in benchmark datasets. We present WebGraphEval, a framework that abstracts trajectories from multiple agents into a unified, weighted action graph. This representation is directly compatible with benchmarks such as WebArena, leveraging leaderboard runs and newly collected trajectories without modifying environments. The framework canonically encodes actions, merges recurring behaviors, and applies structural analyses including reward propagation and success-weighted edge statistics. Evaluations across thousands of trajectories from six web agents show that the graph abstraction captures cross-model regularities, highlights redundancy and inefficiency, and identifies critical decision points overlooked by outcome-based metrics. By framing web interaction as graph-structured data, WebGraphEval establishes a general methodology for multi-path, cross-agent, and efficiency-aware evaluation of web agents.
Structuralist Approach to AI Literary Criticism: Leveraging Greimas Semiotic Square for Large Language Models
Jun 26, 2025Large Language Models (LLMs) excel in understanding and generating text but struggle with providing professional literary criticism for works with profound thoughts and complex narratives. This paper proposes GLASS (Greimas Literary Analysis via Semiotic Square), a structured analytical framework based on Greimas Semiotic Square (GSS), to enhance LLMs' ability to conduct in-depth literary analysis. GLASS facilitates the rapid dissection of narrative structures and deep meanings in narrative works. We propose the first dataset for GSS-based literary criticism, featuring detailed analyses of 48 works. Then we propose quantitative metrics for GSS-based literary criticism using the LLM-as-a-judge paradigm. Our framework's results, compared with expert criticism across multiple works and LLMs, show high performance. Finally, we applied GLASS to 39 classic works, producing original and high-quality analyses that address existing research gaps. This research provides an AI-based tool for literary research and education, offering insights into the cognitive mechanisms underlying literary engagement.
QuantMCP: Grounding Large Language Models in Verifiable Financial Reality
Jun 12, 2025



Large Language Models (LLMs) hold immense promise for revolutionizing financial analysis and decision-making, yet their direct application is often hampered by issues of data hallucination and lack of access to real-time, verifiable financial information. This paper introduces QuantMCP, a novel framework designed to rigorously ground LLMs in financial reality. By leveraging the Model Context Protocol (MCP) for standardized and secure tool invocation, QuantMCP enables LLMs to accurately interface with a diverse array of Python-accessible financial data APIs (e.g., Wind, yfinance). Users can interact via natural language to precisely retrieve up-to-date financial data, thereby overcoming LLM's inherent limitations in factual data recall. More critically, once furnished with this verified, structured data, the LLM's analytical capabilities are unlocked, empowering it to perform sophisticated data interpretation, generate insights, and ultimately support more informed financial decision-making processes. QuantMCP provides a robust, extensible, and secure bridge between conversational AI and the complex world of financial data, aiming to enhance both the reliability and the analytical depth of LLM applications in finance.
\textit{QuantMCP}: Grounding Large Language Models in Verifiable Financial Reality
Jun 07, 2025Large Language Models (LLMs) hold immense promise for revolutionizing financial analysis and decision-making, yet their direct application is often hampered by issues of data hallucination and lack of access to real-time, verifiable financial information. This paper introduces QuantMCP, a novel framework designed to rigorously ground LLMs in financial reality. By leveraging the Model Context Protocol (MCP) for standardized and secure tool invocation, QuantMCP enables LLMs to accurately interface with a diverse array of Python-accessible financial data APIs (e.g., Wind, yfinance). Users can interact via natural language to precisely retrieve up-to-date financial data, thereby overcoming LLM's inherent limitations in factual data recall. More critically, once furnished with this verified, structured data, the LLM's analytical capabilities are unlocked, empowering it to perform sophisticated data interpretation, generate insights, and ultimately support more informed financial decision-making processes. QuantMCP provides a robust, extensible, and secure bridge between conversational AI and the complex world of financial data, aiming to enhance both the reliability and the analytical depth of LLM applications in finance.
CSAGC-IDS: A Dual-Module Deep Learning Network Intrusion Detection Model for Complex and Imbalanced Data
May 20, 2025As computer networks proliferate, the gravity of network intrusions has escalated, emphasizing the criticality of network intrusion detection systems for safeguarding security. While deep learning models have exhibited promising results in intrusion detection, they face challenges in managing high-dimensional, complex traffic patterns and imbalanced data categories. This paper presents CSAGC-IDS, a network intrusion detection model based on deep learning techniques. CSAGC-IDS integrates SC-CGAN, a self-attention-enhanced convolutional conditional generative adversarial network that generates high-quality data to mitigate class imbalance. Furthermore, CSAGC-IDS integrates CSCA-CNN, a convolutional neural network enhanced through cost sensitive learning and channel attention mechanism, to extract features from complex traffic data for precise detection. Experiments conducted on the NSL-KDD dataset. CSAGC-IDS achieves an accuracy of 84.55% and an F1-score of 84.52% in five-class classification task, and an accuracy of 91.09% and an F1 score of 92.04% in binary classification task.Furthermore, this paper provides an interpretability analysis of the proposed model, using SHAP and LIME to explain the decision-making mechanisms of the model.
Divide, Optimize, Merge: Fine-Grained LLM Agent Optimization at Scale
May 06, 2025LLM-based optimization has shown remarkable potential in enhancing agentic systems. However, the conventional approach of prompting LLM optimizer with the whole training trajectories on training dataset in a single pass becomes untenable as datasets grow, leading to context window overflow and degraded pattern recognition. To address these challenges, we propose Fine-Grained Optimization (FGO), a scalable framework that divides large optimization tasks into manageable subsets, performs targeted optimizations, and systematically combines optimized components through progressive merging. Evaluation across ALFWorld, LogisticsQA, and GAIA benchmarks demonstrate that FGO outperforms existing approaches by 1.6-8.6% while reducing average prompt token consumption by 56.3%. Our framework provides a practical solution for scaling up LLM-based optimization of increasingly sophisticated agent systems. Further analysis demonstrates that FGO achieves the most consistent performance gain in all training dataset sizes, showcasing its scalability and efficiency.
Memory-Augmented Agent Training for Business Document Understanding
Dec 17, 2024



Traditional enterprises face significant challenges in processing business documents, where tasks like extracting transport references from invoices remain largely manual despite their crucial role in logistics operations. While Large Language Models offer potential automation, their direct application to specialized business domains often yields unsatisfactory results. We introduce Matrix (Memory-Augmented agent Training through Reasoning and Iterative eXploration), a novel paradigm that enables LLM agents to progressively build domain expertise through experience-driven memory refinement and iterative learning. To validate this approach, we collaborate with one of the world's largest logistics companies to create a dataset of Universal Business Language format invoice documents, focusing on the task of transport reference extraction. Experiments demonstrate that Matrix outperforms prompting a single LLM by 30.3%, vanilla LLM agent by 35.2%. We further analyze the metrics of the optimized systems and observe that the agent system requires less API calls, fewer costs and can analyze longer documents on average. Our methods establish a new approach to transform general-purpose LLMs into specialized business tools through systematic memory enhancement in document processing tasks.
HistoLens: An LLM-Powered Framework for Multi-Layered Analysis of Historical Texts -- A Case Application of Yantie Lun
Nov 15, 2024This paper proposes HistoLens, a multi-layered analysis framework for historical texts based on Large Language Models (LLMs). Using the important Western Han dynasty text "Yantie Lun" as a case study, we demonstrate the framework's potential applications in historical research and education. HistoLens integrates NLP technology (especially LLMs), including named entity recognition, knowledge graph construction, and geographic information visualization. The paper showcases how HistoLens explores Western Han culture in "Yantie Lun" through multi-dimensional, visual, and quantitative methods, focusing particularly on the influence of Confucian and Legalist thoughts on political, economic, military, and ethnic. We also demonstrate how HistoLens constructs a machine teaching scenario using LLMs for explainable analysis, based on a dataset of Confucian and Legalist ideas extracted with LLM assistance. This approach offers novel and diverse perspectives for studying historical texts like "Yantie Lun" and provides new auxiliary tools for history education. The framework aims to equip historians and learners with LLM-assisted tools to facilitate in-depth, multi-layered analysis of historical texts and foster innovation in historical education.
TreeBoN: Enhancing Inference-Time Alignment with Speculative Tree-Search and Best-of-N Sampling
Oct 18, 2024

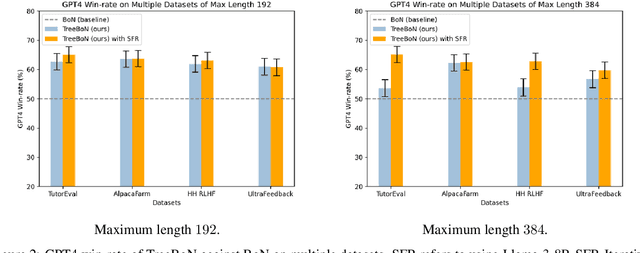

Inference-time alignment enhances the performance of large language models without requiring additional training or fine-tuning but presents challenges due to balancing computational efficiency with high-quality output. Best-of-N (BoN) sampling, as a simple yet powerful approach, generates multiple responses and selects the best one, achieving improved performance but with a high computational cost. We propose TreeBoN, a novel framework that integrates a speculative tree-search strategy into Best-of-N (BoN) Sampling. TreeBoN maintains a set of parent nodes, iteratively branching and pruning low-quality responses, thereby reducing computational overhead while maintaining high output quality. Our approach also leverages token-level rewards from Direct Preference Optimization (DPO) to guide tree expansion and prune low-quality paths. We evaluate TreeBoN using AlpacaFarm, UltraFeedback, GSM8K, HH-RLHF, and TutorEval datasets, demonstrating consistent improvements. Specifically, TreeBoN achieves a 65% win rate at maximum lengths of 192 and 384 tokens, outperforming standard BoN with the same computational cost. Furthermore, TreeBoN achieves around a 60% win rate across longer responses, showcasing its scalability and alignment efficacy.