 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Uncertainty-Based Explore for Index Construction and Retrieval in Recommendation System
Aug 06, 2024



In recommendation systems, the relevance and novelty of the final results are selected through a cascade system of Matching -> Ranking -> Strategy. The matching model serves as the starting point of the pipeline and determines the upper bound of the subsequent stages. Balancing the relevance and novelty of matching results is a crucial step in the design and optimization of recommendation systems, contributing significantly to improving recommendation quality. However, the typical matching algorithms have not simultaneously addressed the relevance and novelty perfectly. One main reason is that deep matching algorithms exhibit significant uncertainty when estimating items in the long tail (e.g., due to insufficient training samples) items.The uncertainty not only affects the training of the models but also influences the confidence in the index construction and beam search retrieval process of these models. This paper proposes the UICR (Uncertainty-based explore for Index Construction and Retrieval) algorithm, which introduces the concept of uncertainty modeling in the matching stage and achieves multi-task modeling of model uncertainty and index uncertainty. The final matching results are obtained by combining the relevance score and uncertainty score infered by the model. Experimental results demonstrate that the UICR improves novelty without sacrificing relevance on realworld industrial productive environments and multiple open-source datasets. Remarkably, online A/B test results of display advertising in Shopee demonstrates the effectiveness of the proposed algorithm.
A New Creative Generation Pipeline for Click-Through Rate with Stable Diffusion Model
Jan 17, 2024



In online advertising scenario, sellers often create multiple creatives to provide comprehensive demonstrations, making it essential to present the most appealing design to maximize the Click-Through Rate (CTR). However, sellers generally struggle to consider users preferences for creative design, leading to the relatively lower aesthetics and quantities compared to Artificial Intelligence (AI)-based approaches. Traditional AI-based approaches still face the same problem of not considering user information while having limited aesthetic knowledge from designers. In fact that fusing the user information, the generated creatives can be more attractive because different users may have different preferences. To optimize the results, the generated creatives in traditional methods are then ranked by another module named creative ranking model. The ranking model can predict the CTR score for each creative considering user features. However, the two above stages are regarded as two different tasks and are optimized separately. In this paper, we proposed a new automated Creative Generation pipeline for Click-Through Rate (CG4CTR) with the goal of improving CTR during the creative generation stage. Our contributions have 4 parts: 1) The inpainting mode in stable diffusion is firstly applied to creative generation task in online advertising scene. A self-cyclic generation pipeline is proposed to ensure the convergence of training. 2) Prompt model is designed to generate individualized creatives for different user groups, which can further improve the diversity and quality. 3) Reward model comprehensively considers the multimodal features of image and text to improve the effectiveness of creative ranking task, and it is also critical in self-cyclic pipeline. 4) The significant benefits obtained in online and offline experiments verify the significance of our proposed method.
Deep Ensemble Shape Calibration: Multi-Field Post-hoc Calibration in Online Advertising
Jan 17, 2024



In the e-commerce advertising scenario, estimating the true probabilities (known as a calibrated estimate) on CTR and CVR is critical and can directly affect the benefits of the buyer, seller and platform. Previous research has introduced numerous solutions for addressing the calibration problem. These methods typically involve the training of calibrators using a validation set and subsequently applying these calibrators to correct the original estimated values during online inference. However, what sets e-commerce advertising scenarios is the challenge of multi-field calibration. Multi-field calibration can be subdivided into two distinct sub-problems: value calibration and shape calibration. Value calibration is defined as no over- or under-estimation for each value under concerned fields. Shape calibration is defined as no over- or under-estimation for each subset of the pCTR within the specified range under condition of concerned fields. In order to achieve shape calibration and value calibration, it is necessary to have a strong data utilization ability.Because the quantity of pCTR specified range for single field-value sample is relative small, which makes the calibrator more difficult to train. However the existing methods cannot simultaneously fulfill both value calibration and shape calibration. To solve these problems, we propose a new method named Deep Ensemble Shape Calibration (DESC). We introduce innovative basis calibration functions, which enhance both function expression capabilities and data utilization by combining these basis calibration functions. A significant advancement lies in the development of an allocator capable of allocating the most suitable shape calibrators to different estimation error distributions within diverse fields and values.
Joint Network Function Placement and Routing Optimization in Dynamic Software-defined Satellite-Terrestrial Integrated Networks
Oct 21, 2023Software-defined satellite-terrestrial integrated networks (SDSTNs) are seen as a promising paradigm for achieving high resource flexibility and global communication coverage. However, low latency service provisioning is still challenging due to the fast variation of network topology and limited onboard resource at low earth orbit satellites. To address this issue, we study service provisioning in SDSTNs via joint optimization of virtual network function (VNF) placement and routing planning with network dynamics characterized by a time-evolving graph. Aiming at minimizing average service latency, the corresponding problem is formulated as an integer nonlinear programming under resource, VNF deployment, and time-slotted flow constraints. Since exhaustive search is intractable, we transform the primary problem into an integer linear programming by involving auxiliary variables and then propose a Benders decomposition based branch-and-cut (BDBC) algorithm. Towards practical use, a time expansion-based decoupled greedy (TEDG) algorithm is further designed with rigorous complexity analysis. Extensive experiments demonstrate the optimality of BDBC algorithm and the low complexity of TEDG algorithm. Meanwhile, it is indicated that they can improve the number of completed services within a configuration period by up to 58% and reduce the average service latency by up to 17% compared to baseline schemes.
Exploring Model Dynamics for Accumulative Poisoning Discovery
Jun 06, 2023Adversarial poisoning attacks pose huge threats to various machine learning applications. Especially, the recent accumulative poisoning attacks show that it is possible to achieve irreparable harm on models via a sequence of imperceptible attacks followed by a trigger batch. Due to the limited data-level discrepancy in real-time data streaming, current defensive methods are indiscriminate in handling the poison and clean samples. In this paper, we dive into the perspective of model dynamics and propose a novel information measure, namely, Memorization Discrepancy, to explore the defense via the model-level information. By implicitly transferring the changes in the data manipulation to that in the model outputs, Memorization Discrepancy can discover the imperceptible poison samples based on their distinct dynamics from the clean samples. We thoroughly explore its properties and propose Discrepancy-aware Sample Correction (DSC) to defend against accumulative poisoning attacks. Extensive experiments comprehensively characterized Memorization Discrepancy and verified its effectiveness. The code is publicly available at: https://github.com/tmlr-group/Memorization-Discrepancy.
ROI-Constrained Bidding via Curriculum-Guided Bayesian Reinforcement Learning
Jun 23, 2022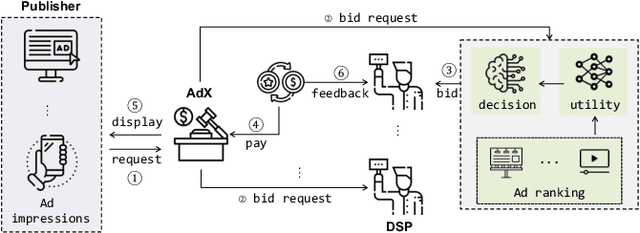
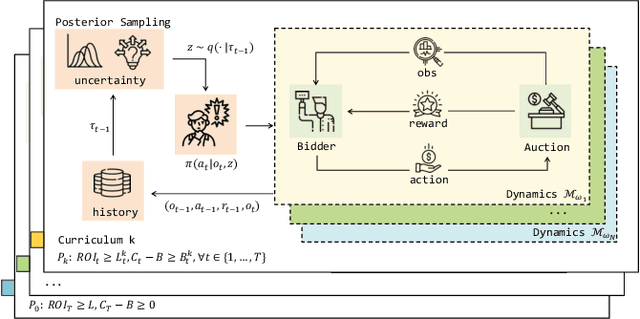
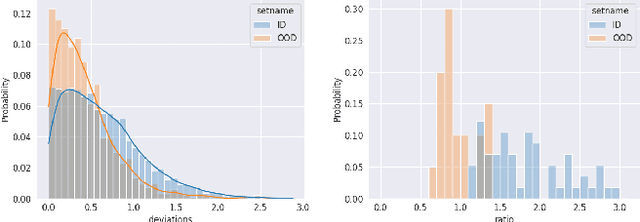
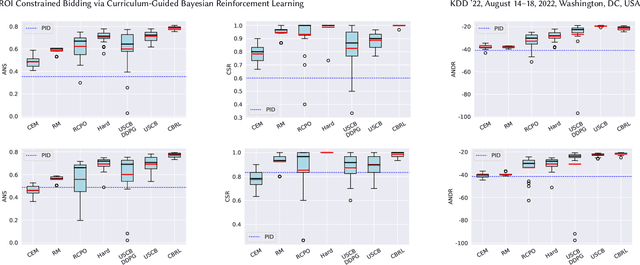
Real-Time Bidding (RTB) is an important mechanism in modern online advertising systems. Advertisers employ bidding strategies in RTB to optimize their advertising effects subject to various financial requirements, especially the return-on-investment (ROI) constraint. ROIs change non-monotonically during the sequential bidding process, and often induce a see-saw effect between constraint satisfaction and objective optimization. While some existing approaches show promising results in static or mildly changing ad markets, they fail to generalize to highly dynamic ad markets with ROI constraints, due to their inability to adaptively balance constraints and objectives amidst non-stationarity and partial observability. In this work, we specialize in ROI-Constrained Bidding in non-stationary markets. Based on a Partially Observable Constrained Markov Decision Process, our method exploits an indicator-augmented reward function free of extra trade-off parameters and develops a Curriculum-Guided Bayesian Reinforcement Learning (CBRL) framework to adaptively control the constraint-objective trade-off in non-stationary ad markets. Extensive experiments on a large-scale industrial dataset with two problem settings reveal that CBRL generalizes well in both in-distribution and out-of-distribution data regimes, and enjoys superior learning efficiency and stability.
Joint Sensing, Communication, and Computation Resource Allocation for Cooperative Perception in Fog-Based Vehicular Networks
Dec 12, 2021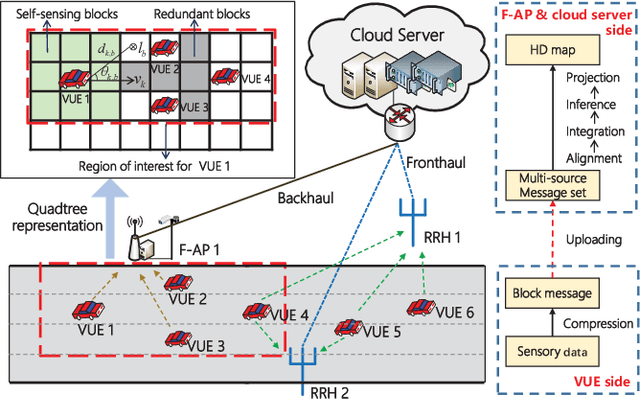
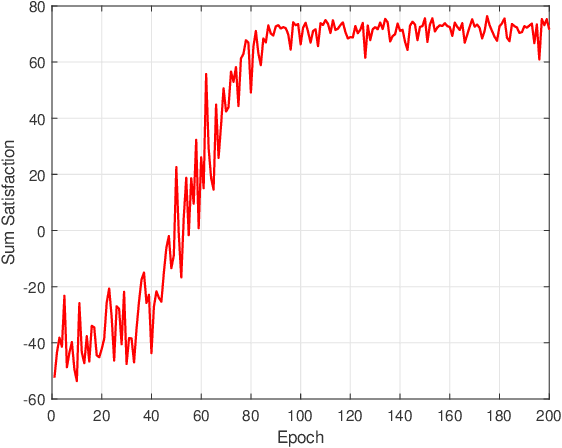
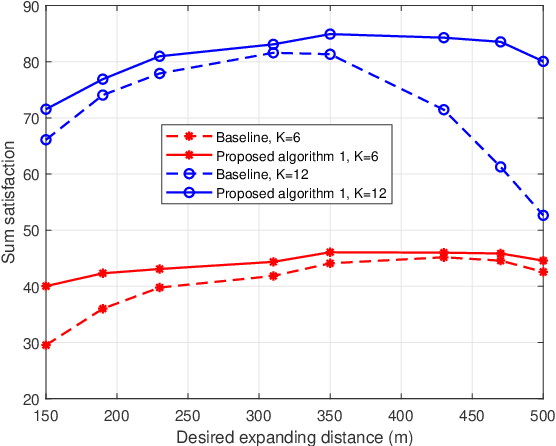
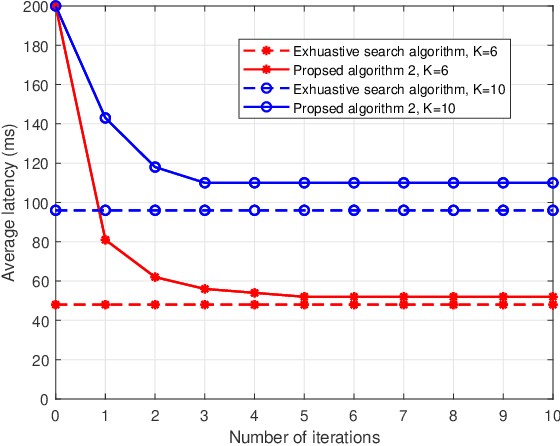
To enlarge the perception range and reliability of individual autonomous vehicles, cooperative perception has been received much attention. However, considering the high volume of shared messages, limited bandwidth and computation resources in vehicular networks become bottlenecks. In this paper, we investigate how to balance the volume of shared messages and constrained resources in fog-based vehicular networks. To this end, we first characterize sum satisfaction of cooperative perception taking account of its spatial-temporal value and latency performance. Next, the sensing block message, communication resource block, and computation resource are jointly allocated to maximize the sum satisfaction of cooperative perception, while satisfying the maximum latency and sojourn time constraints of vehicles. Owing to its non-convexity, we decouple the original problem into two separate sub-problems and devise corresponding solutions. Simulation results demonstrate that our proposed scheme can effectively boost the sum satisfaction of cooperative perception compared with existing baselines.
Secure and Efficient Federated Learning Through Layering and Sharding Blockchain
Apr 27, 2021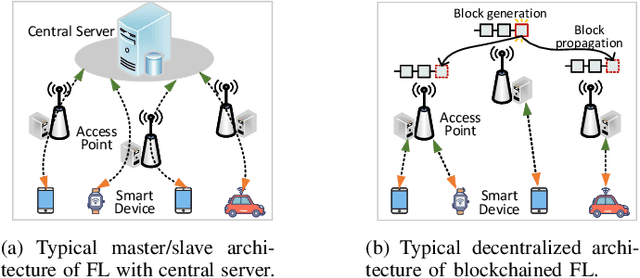
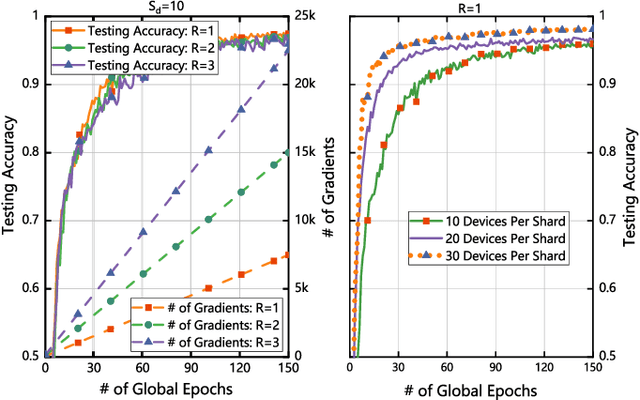
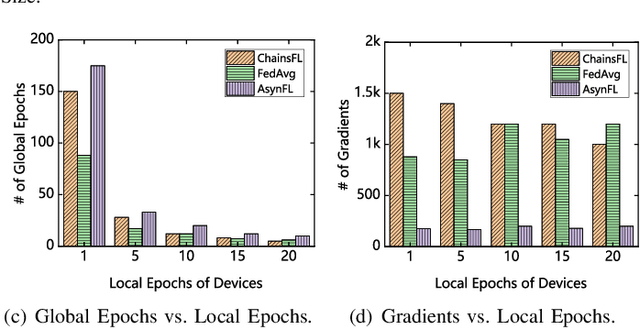

Federated learning (FL) has emerged as a promising master/slave learning paradigm to alleviate systemic privacy risks and communication costs incurred by cloud-centric machine learning methods. However, it is very challenging to resist the single point of failure of the master aggregator and attacks from malicious participants while guaranteeing model convergence speed and accuracy. Recently, blockchain has been brought into FL systems transforming the paradigm to a decentralized manner thus further improve the system security and learning reliability. Unfortunately, the traditional consensus mechanism and architecture of blockchain systems can hardly handle the large-scale FL task due to the huge resource consumption, limited transaction throughput, and high communication complexity. To address these issues, this paper proposes a two-layer blockchaindriven FL framework, called as ChainsFL, which is composed of multiple subchain networks (subchain layer) and a direct acyclic graph (DAG)-based mainchain (mainchain layer). In ChainsFL, the subchain layer limits the scale of each shard for a small range of information exchange, and the mainchain layer allows each shard to share and validate the learning model in parallel and asynchronously to improve the efficiency of cross-shard validation. Furthermore, the FL procedure is customized to deeply integrate with blockchain technology, and the modified DAG consensus mechanism is proposed to mitigate the distortion caused by abnormal models. In order to provide a proof-ofconcept implementation and evaluation, multiple subchains base on Hyperledger Fabric are deployed as the subchain layer, and the self-developed DAG-based mainchain is deployed as the mainchain layer. The experimental results show that ChainsFL provides acceptable and sometimes better training efficiency and stronger robustness compared with the typical existing FL systems.
Exploration in Online Advertising Systems with Deep Uncertainty-Aware Learning
Nov 25, 2020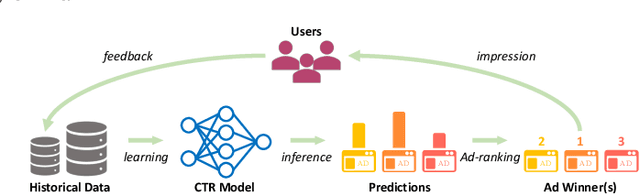
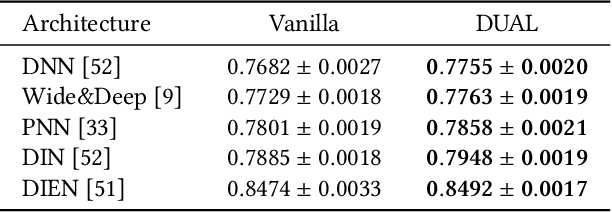
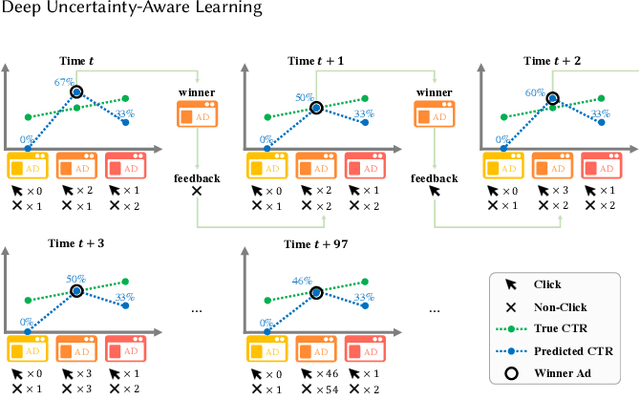
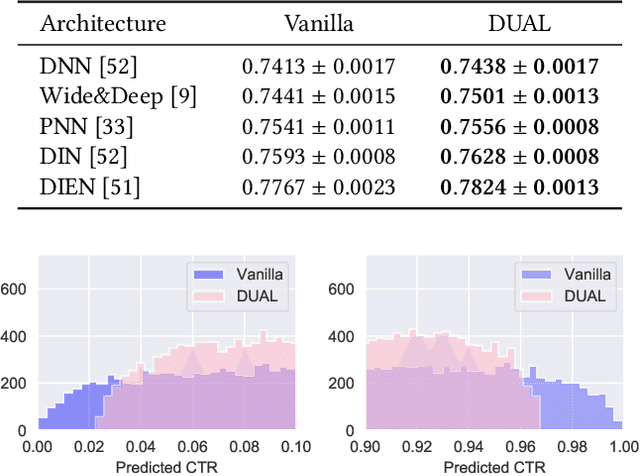
Modern online advertising systems inevitably rely on personalization methods, such as click-through rate (CTR) prediction. Recent progress in CTR prediction enjoys the rich representation capabilities of deep learning and achieves great success in large-scale industrial applications. However, these methods can suffer from lack of exploration. Another line of prior work addresses the exploration-exploitation trade-off problem with contextual bandit methods, which are less studied in the industry recently due to the difficulty in extending their flexibility with deep models. In this paper, we propose a novel Deep Uncertainty-Aware Learning (DUAL) method to learn deep CTR models based on Gaussian processes, which can provide efficient uncertainty estimations along with the CTR predictions while maintaining the flexibility of deep neural networks. By linking the ability to estimate predictive uncertainties of DUAL to well-known bandit algorithms, we further present DUAL-based Ad-ranking strategies to boost up long-term utilities such as the social welfare in advertising systems. Experimental results on several public datasets demonstrate the effectiveness of our methods. Remarkably, an online A/B test deployed in the Alibaba display advertising platform shows an $8.2\%$ social welfare improvement and an $8.0\%$ revenue lift.