 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Uncertainty-Based Explore for Index Construction and Retrieval in Recommendation System
Aug 06, 2024



In recommendation systems, the relevance and novelty of the final results are selected through a cascade system of Matching -> Ranking -> Strategy. The matching model serves as the starting point of the pipeline and determines the upper bound of the subsequent stages. Balancing the relevance and novelty of matching results is a crucial step in the design and optimization of recommendation systems, contributing significantly to improving recommendation quality. However, the typical matching algorithms have not simultaneously addressed the relevance and novelty perfectly. One main reason is that deep matching algorithms exhibit significant uncertainty when estimating items in the long tail (e.g., due to insufficient training samples) items.The uncertainty not only affects the training of the models but also influences the confidence in the index construction and beam search retrieval process of these models. This paper proposes the UICR (Uncertainty-based explore for Index Construction and Retrieval) algorithm, which introduces the concept of uncertainty modeling in the matching stage and achieves multi-task modeling of model uncertainty and index uncertainty. The final matching results are obtained by combining the relevance score and uncertainty score infered by the model. Experimental results demonstrate that the UICR improves novelty without sacrificing relevance on realworld industrial productive environments and multiple open-source datasets. Remarkably, online A/B test results of display advertising in Shopee demonstrates the effectiveness of the proposed algorithm.
Cross-Element Combinatorial Selection for Multi-Element Creative in Display Advertising
Jul 04, 2023



The effectiveness of ad creatives is greatly influenced by their visual appearance. Advertising platforms can generate ad creatives with different appearances by combining creative elements provided by advertisers. However, with the increasing number of ad creative elements, it becomes challenging to select a suitable combination from the countless possibilities. The industry's mainstream approach is to select individual creative elements independently, which often overlooks the importance of interaction between creative elements during the modeling process. In response, this paper proposes a Cross-Element Combinatorial Selection framework for multiple creative elements, termed CECS. In the encoder process, a cross-element interaction is adopted to dynamically adjust the expression of a single creative element based on the current candidate creatives. In the decoder process, the creative combination problem is transformed into a cascade selection problem of multiple creative elements. A pointer mechanism with a cascade design is used to model the associations among candidates. Comprehensive experiments on real-world datasets show that CECS achieved the SOTA score on offline metrics. Moreover, the CECS algorithm has been deployed in our industrial application, resulting in a significant 6.02% CTR and 10.37% GMV lift, which is beneficial to the business.
A Collaborative Transfer Learning Framework for Cross-domain Recommendation
Jun 26, 2023In the recommendation systems, there are multiple business domains to meet the diverse interests and needs of users, and the click-through rate(CTR) of each domain can be quite different, which leads to the demand for CTR prediction modeling for different business domains. The industry solution is to use domain-specific models or transfer learning techniques for each domain. The disadvantage of the former is that the data from other domains is not utilized by a single domain model, while the latter leverage all the data from different domains, but the fine-tuned model of transfer learning may trap the model in a local optimum of the source domain, making it difficult to fit the target domain. Meanwhile, significant differences in data quantity and feature schemas between different domains, known as domain shift, may lead to negative transfer in the process of transferring. To overcome these challenges, we propose the Collaborative Cross-Domain Transfer Learning Framework (CCTL). CCTL evaluates the information gain of the source domain on the target domain using a symmetric companion network and adjusts the information transfer weight of each source domain sample using the information flow network. This approach enables full utilization of other domain data while avoiding negative migration. Additionally, a representation enhancement network is used as an auxiliary task to preserve domain-specific features. Comprehensive experiments on both public and real-world industrial datasets, CCTL achieved SOTA score on offline metrics. At the same time, the CCTL algorithm has been deployed in Meituan, bringing 4.37% CTR and 5.43% GMV lift, which is significant to the business.
Graph Based Long-Term And Short-Term Interest Model for Click-Through Rate Prediction
Jun 05, 2023



Click-through rate (CTR) prediction aims to predict the probability that the user will click an item, which has been one of the key tasks in online recommender and advertising systems. In such systems, rich user behavior (viz. long- and short-term) has been proved to be of great value in capturing user interests. Both industry and academy have paid much attention to this topic and propose different approaches to modeling with long-term and short-term user behavior data. But there are still some unresolved issues. More specially, (1) rule and truncation based methods to extract information from long-term behavior are easy to cause information loss, and (2) single feedback behavior regardless of scenario to extract information from short-term behavior lead to information confusion and noise. To fill this gap, we propose a Graph based Long-term and Short-term interest Model, termed GLSM. It consists of a multi-interest graph structure for capturing long-term user behavior, a multi-scenario heterogeneous sequence model for modeling short-term information, then an adaptive fusion mechanism to fused information from long-term and short-term behaviors. Comprehensive experiments on real-world datasets, GLSM achieved SOTA score on offline metrics. At the same time, the GLSM algorithm has been deployed in our industrial application, bringing 4.9% CTR and 4.3% GMV lift, which is significant to the business.
DCAF: A Dynamic Computation Allocation Framework for Online Serving System
Jun 17, 2020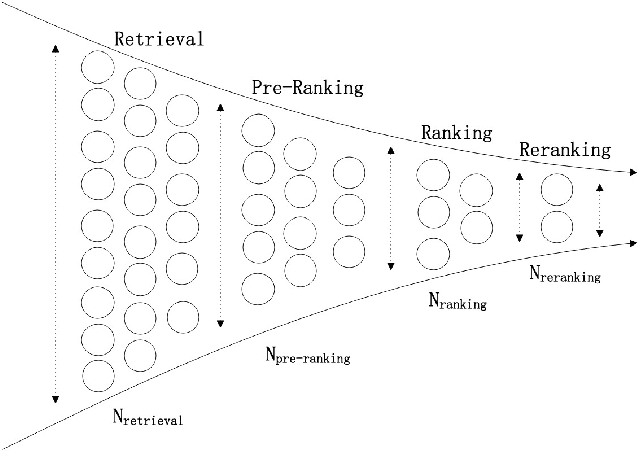
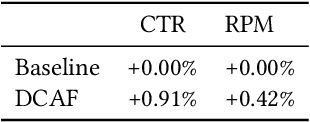
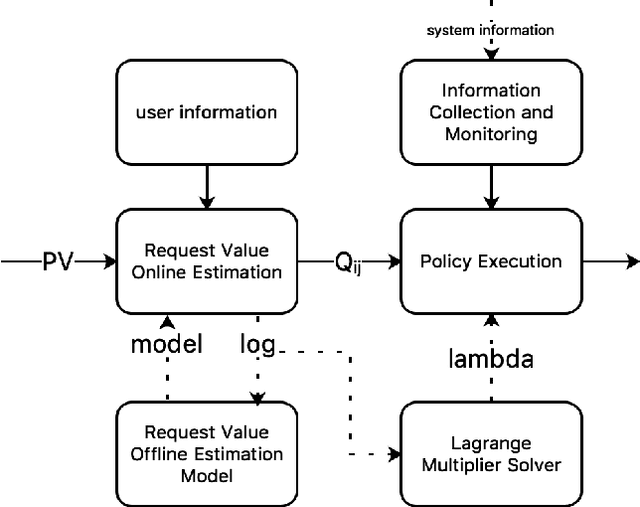

Modern large-scale systems such as recommender system and online advertising system are built upon computation-intensive infrastructure. The typical objective in these applications is to maximize the total revenue, e.g. GMV~(Gross Merchandise Volume), under a limited computation resource. Usually, the online serving system follows a multi-stage cascade architecture, which consists of several stages including retrieval, pre-ranking, ranking, etc. These stages usually allocate resource manually with specific computing power budgets, which requires the serving configuration to adapt accordingly. As a result, the existing system easily falls into suboptimal solutions with respect to maximizing the total revenue. The limitation is due to the face that, although the value of traffic requests vary greatly, online serving system still spends equal computing power among them. In this paper, we introduce a novel idea that online serving system could treat each traffic request differently and allocate "personalized" computation resource based on its value. We formulate this resource allocation problem as a knapsack problem and propose a Dynamic Computation Allocation Framework~(DCAF). Under some general assumptions, DCAF can theoretically guarantee that the system can maximize the total revenue within given computation budget. DCAF brings significant improvement and has been deployed in the display advertising system of Taobao for serving the main traffic. With DCAF, we are able to maintain the same business performance with 20\% computation resource reduction.
Joint Optimization of Tree-based Index and Deep Model for Recommender Systems
Feb 19, 2019



Large-scale industrial recommender systems are usually confronted with computational problems due to the enormous corpus size. To retrieve and recommend the most relevant items to users under response time limits, resorting to an efficient index structure is an effective and practical solution. Tree-based Deep Model (TDM) for recommendation \cite{zhu2018learning} greatly improves recommendation accuracy using tree index. By indexing items in a tree hierarchy and training a user-node preference prediction model satisfying a max-heap like property in the tree, TDM provides logarithmic computational complexity w.r.t. the corpus size, enabling the use of arbitrary advanced models in candidate retrieval and recommendation. In tree-based recommendation methods, the quality of both the tree index and the trained user preference prediction model determines the recommendation accuracy for the most part. We argue that the learning of tree index and user preference model has interdependence. Our purpose, in this paper, is to develop a method to jointly learn the index structure and user preference prediction model. In our proposed joint optimization framework, the learning of index and user preference prediction model are carried out under a unified performance measure. Besides, we come up with a novel hierarchical user preference representation utilizing the tree index hierarchy. Experimental evaluations with two large-scale real-world datasets show that the proposed method improves recommendation accuracy significantly. Online A/B test results at Taobao display advertising also demonstrate the effectiveness of the proposed method in production environments.
Learning Tree-based Deep Model for Recommender Systems
Nov 01, 2018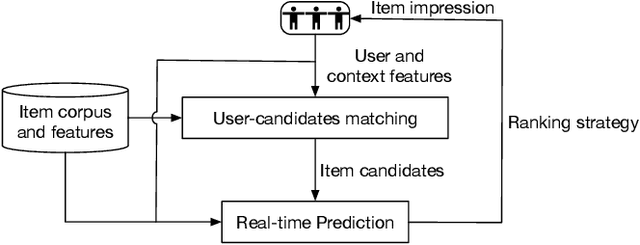
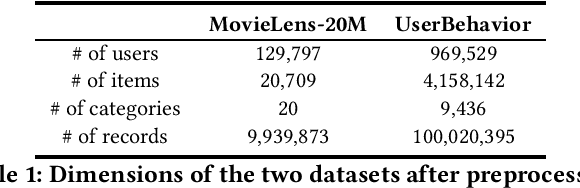
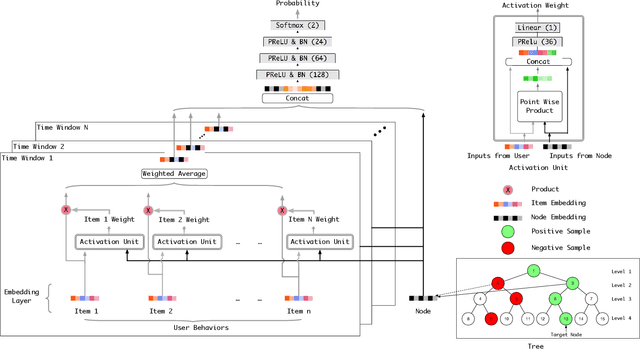
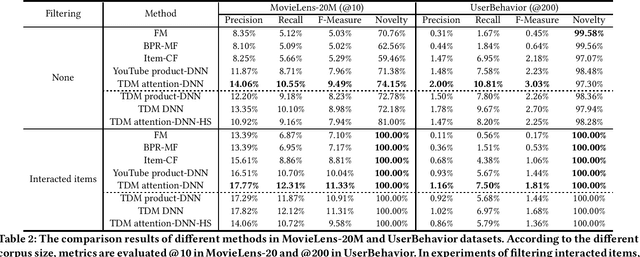
Model-based methods for recommender systems have been studied extensively in recent years. In systems with large corpus, however, the calculation cost for the learnt model to predict all user-item preferences is tremendous, which makes full corpus retrieval extremely difficult. To overcome the calculation barriers, models such as matrix factorization resort to inner product form (i.e., model user-item preference as the inner product of user, item latent factors) and indexes to facilitate efficient approximate k-nearest neighbor searches. However, it still remains challenging to incorporate more expressive interaction forms between user and item features, e.g., interactions through deep neural networks, because of the calculation cost. In this paper, we focus on the problem of introducing arbitrary advanced models to recommender systems with large corpus. We propose a novel tree-based method which can provide logarithmic complexity w.r.t. corpus size even with more expressive models such as deep neural networks. Our main idea is to predict user interests from coarse to fine by traversing tree nodes in a top-down fashion and making decisions for each user-node pair. We also show that the tree structure can be jointly learnt towards better compatibility with users' interest distribution and hence facilitate both training and prediction. Experimental evaluations with two large-scale real-world datasets show that the proposed method significantly outperforms traditional methods. Online A/B test results in Taobao display advertising platform also demonstrate the effectiveness of the proposed method in production environments.