 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
Jan 27, 2021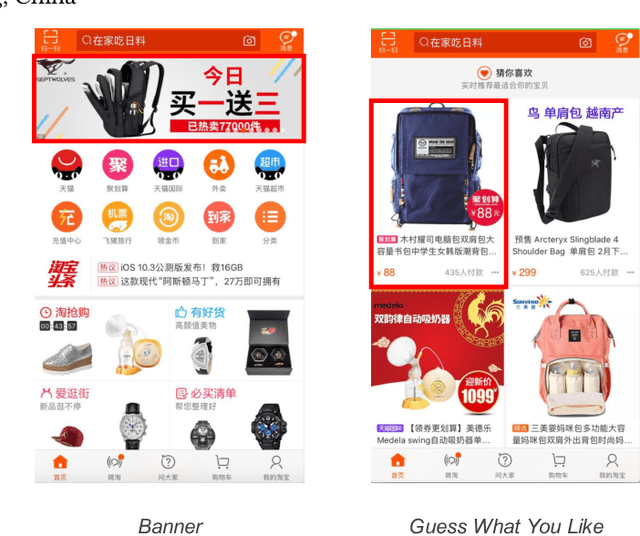
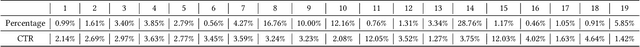
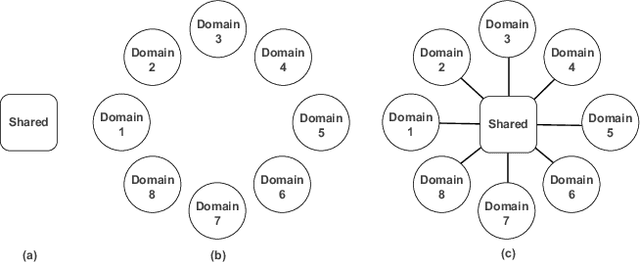
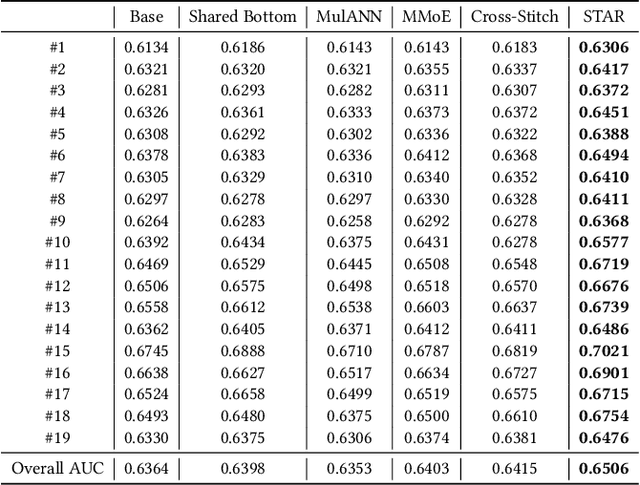
Traditional industrial recommenders are usually trained on a single business domain and then serve for this domain. In large commercial platforms, however, it is often the case that the recommenders need to make click-through rate (CTR) predictions for multiple business domains. Different domains have overlapping user groups and items, thus exist commonalities. Since the specific user group may be different and the user behaviors may change within a specific domain, different domains also have distinctions. The distinctions result in different domain-specific data distributions, which makes it hard for a single shared model to work well on all domains. To address the problem, we present Star Topology Adaptive Recommender (STAR), where one model is learned to serve all domains effectively. Concretely, STAR has the star topology, which consists of the shared centered parameters and domain-specific parameters. The shared parameters are used to learn commonalities of all domains and the domain-specific parameters capture domain distinction for more refined prediction. Given requests from different domains, STAR can adapt its parameters conditioned on the domain. The experimental result from production data validates the superiority of the proposed STAR model. Up to now, STAR has been deployed in the display advertising system of Alibaba, obtaining averaging 8.0% improvement on CTR and 6.0% on RPM (Revenue Per Mille).
DCAF: A Dynamic Computation Allocation Framework for Online Serving System
Jun 17, 2020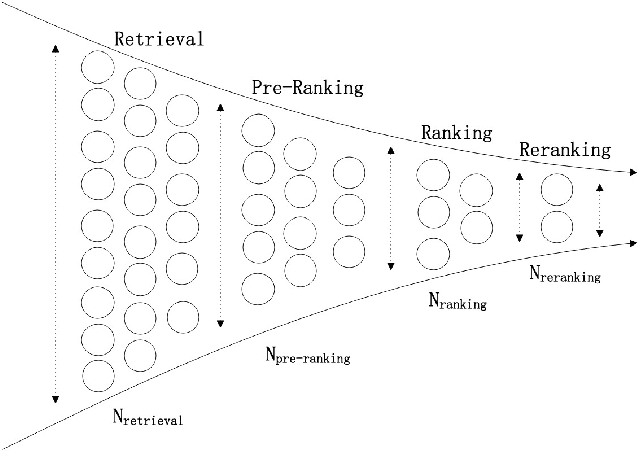
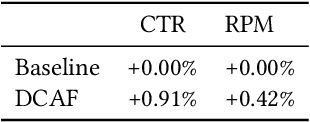
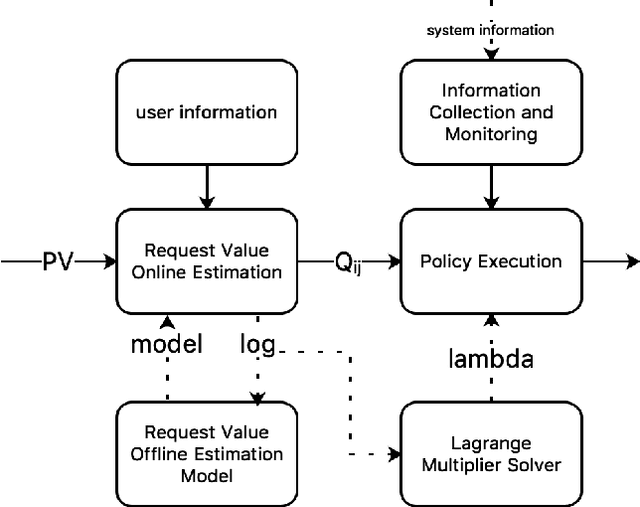

Modern large-scale systems such as recommender system and online advertising system are built upon computation-intensive infrastructure. The typical objective in these applications is to maximize the total revenue, e.g. GMV~(Gross Merchandise Volume), under a limited computation resource. Usually, the online serving system follows a multi-stage cascade architecture, which consists of several stages including retrieval, pre-ranking, ranking, etc. These stages usually allocate resource manually with specific computing power budgets, which requires the serving configuration to adapt accordingly. As a result, the existing system easily falls into suboptimal solutions with respect to maximizing the total revenue. The limitation is due to the face that, although the value of traffic requests vary greatly, online serving system still spends equal computing power among them. In this paper, we introduce a novel idea that online serving system could treat each traffic request differently and allocate "personalized" computation resource based on its value. We formulate this resource allocation problem as a knapsack problem and propose a Dynamic Computation Allocation Framework~(DCAF). Under some general assumptions, DCAF can theoretically guarantee that the system can maximize the total revenue within given computation budget. DCAF brings significant improvement and has been deployed in the display advertising system of Taobao for serving the main traffic. With DCAF, we are able to maintain the same business performance with 20\% computation resource reduction.