 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKuaiLive: A Real-time Interactive Dataset for Live Streaming Recommendation
Aug 07, 2025
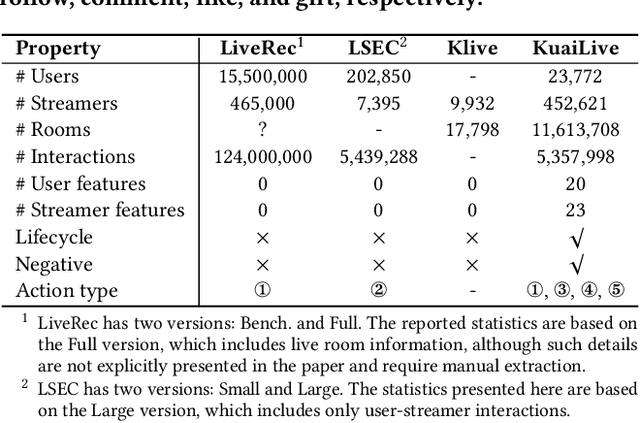

Live streaming platforms have become a dominant form of online content consumption, offering dynamically evolving content, real-time interactions, and highly engaging user experiences. These unique characteristics introduce new challenges that differentiate live streaming recommendation from traditional recommendation settings and have garnered increasing attention from industry in recent years. However, research progress in academia has been hindered by the lack of publicly available datasets that accurately reflect the dynamic nature of live streaming environments. To address this gap, we introduce KuaiLive, the first real-time, interactive dataset collected from Kuaishou, a leading live streaming platform in China with over 400 million daily active users. The dataset records the interaction logs of 23,772 users and 452,621 streamers over a 21-day period. Compared to existing datasets, KuaiLive offers several advantages: it includes precise live room start and end timestamps, multiple types of real-time user interactions (click, comment, like, gift), and rich side information features for both users and streamers. These features enable more realistic simulation of dynamic candidate items and better modeling of user and streamer behaviors. We conduct a thorough analysis of KuaiLive from multiple perspectives and evaluate several representative recommendation methods on it, establishing a strong benchmark for future research. KuaiLive can support a wide range of tasks in the live streaming domain, such as top-K recommendation, click-through rate prediction, watch time prediction, and gift price prediction. Moreover, its fine-grained behavioral data also enables research on multi-behavior modeling, multi-task learning, and fairness-aware recommendation. The dataset and related resources are publicly available at https://imgkkk574.github.io/KuaiLive.
MMBee: Live Streaming Gift-Sending Recommendations via Multi-Modal Fusion and Behaviour Expansion
Jun 15, 2024Live streaming services are becoming increasingly popular due to real-time interactions and entertainment. Viewers can chat and send comments or virtual gifts to express their preferences for the streamers. Accurately modeling the gifting interaction not only enhances users' experience but also increases streamers' revenue. Previous studies on live streaming gifting prediction treat this task as a conventional recommendation problem, and model users' preferences using categorical data and observed historical behaviors. However, it is challenging to precisely describe the real-time content changes in live streaming using limited categorical information. Moreover, due to the sparsity of gifting behaviors, capturing the preferences and intentions of users is quite difficult. In this work, we propose MMBee based on real-time Multi-Modal Fusion and Behaviour Expansion to address these issues. Specifically, we first present a Multi-modal Fusion Module with Learnable Query (MFQ) to perceive the dynamic content of streaming segments and process complex multi-modal interactions, including images, text comments and speech. To alleviate the sparsity issue of gifting behaviors, we present a novel Graph-guided Interest Expansion (GIE) approach that learns both user and streamer representations on large-scale gifting graphs with multi-modal attributes. Comprehensive experiment results show that MMBee achieves significant performance improvements on both public datasets and Kuaishou real-world streaming datasets and the effectiveness has been further validated through online A/B experiments. MMBee has been deployed and is serving hundreds of millions of users at Kuaishou.
Ensure Timeliness and Accuracy: A Novel Sliding Window Data Stream Paradigm for Live Streaming Recommendation
Feb 22, 2024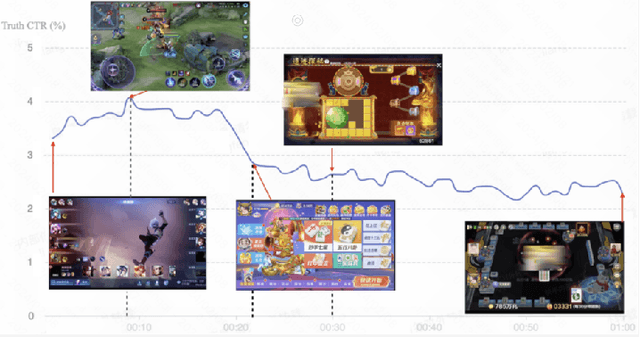

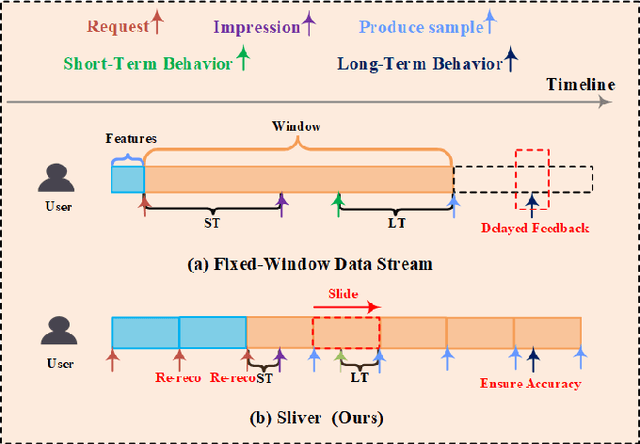

Live streaming recommender system is specifically designed to recommend real-time live streaming of interest to users. Due to the dynamic changes of live content, improving the timeliness of the live streaming recommender system is a critical problem. Intuitively, the timeliness of the data determines the upper bound of the timeliness that models can learn. However, none of the previous works addresses the timeliness problem of the live streaming recommender system from the perspective of data stream design. Employing the conventional fixed window data stream paradigm introduces a trade-off dilemma between labeling accuracy and timeliness. In this paper, we propose a new data stream design paradigm, dubbed Sliver, that addresses the timeliness and accuracy problem of labels by reducing the window size and implementing a sliding window correspondingly. Meanwhile, we propose a time-sensitive re-reco strategy reducing the latency between request and impression to improve the timeliness of the recommendation service and features by periodically requesting the recommendation service. To demonstrate the effectiveness of our approach, we conduct offline experiments on a multi-task live streaming dataset with labeling timestamps collected from the Kuaishou live streaming platform. Experimental results demonstrate that Sliver outperforms two fixed-window data streams with varying window sizes across all targets in four typical multi-task recommendation models. Furthermore, we deployed Sliver on the Kuaishou live streaming platform. Results of the online A/B test show a significant improvement in click-through rate (CTR), and new follow number (NFN), further validating the effectiveness of Sliver.
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
Jan 27, 2021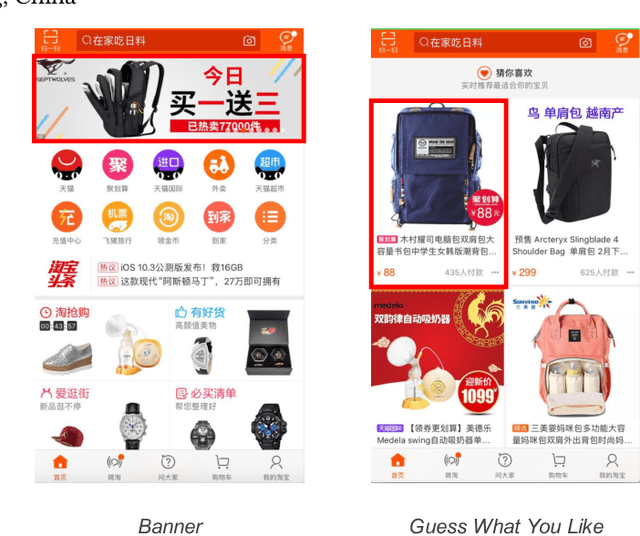
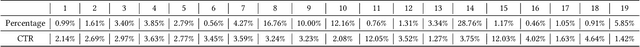
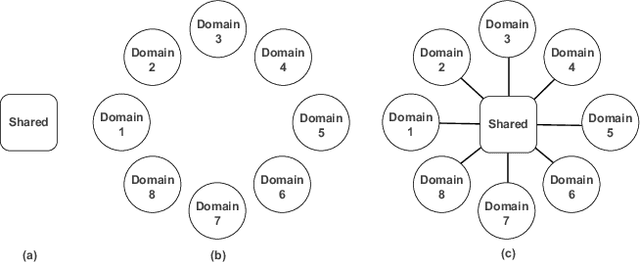
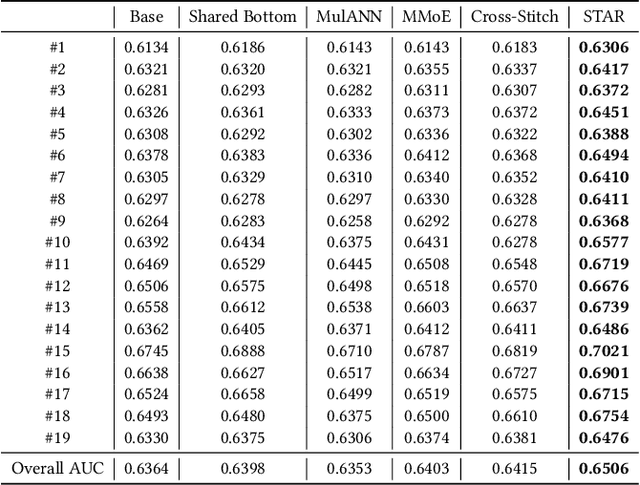
Traditional industrial recommenders are usually trained on a single business domain and then serve for this domain. In large commercial platforms, however, it is often the case that the recommenders need to make click-through rate (CTR) predictions for multiple business domains. Different domains have overlapping user groups and items, thus exist commonalities. Since the specific user group may be different and the user behaviors may change within a specific domain, different domains also have distinctions. The distinctions result in different domain-specific data distributions, which makes it hard for a single shared model to work well on all domains. To address the problem, we present Star Topology Adaptive Recommender (STAR), where one model is learned to serve all domains effectively. Concretely, STAR has the star topology, which consists of the shared centered parameters and domain-specific parameters. The shared parameters are used to learn commonalities of all domains and the domain-specific parameters capture domain distinction for more refined prediction. Given requests from different domains, STAR can adapt its parameters conditioned on the domain. The experimental result from production data validates the superiority of the proposed STAR model. Up to now, STAR has been deployed in the display advertising system of Alibaba, obtaining averaging 8.0% improvement on CTR and 6.0% on RPM (Revenue Per Mille).
COLD: Towards the Next Generation of Pre-Ranking System
Aug 17, 2020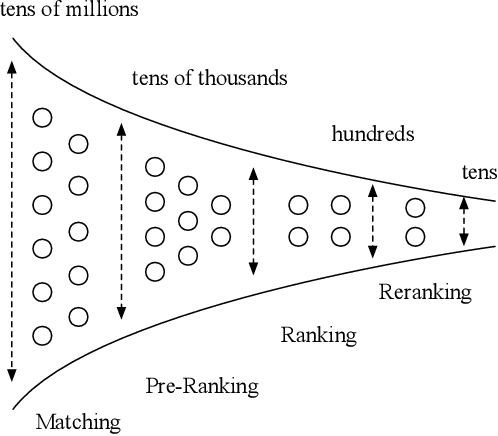

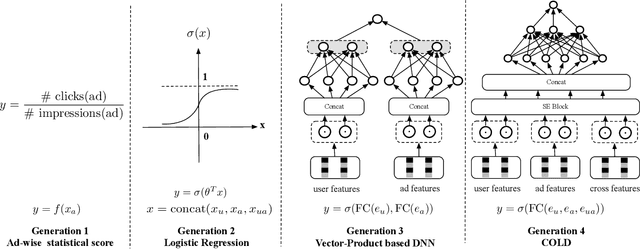

Multi-stage cascade architecture exists widely in many industrial systems such as recommender systems and online advertising, which often consists of sequential modules including matching, pre-ranking, ranking, etc. For a long time, it is believed pre-ranking is just a simplified version of the ranking module, considering the larger size of the candidate set to be ranked. Thus, efforts are made mostly on simplifying ranking model to handle the explosion of computing power for online inference. In this paper, we rethink the challenge of the pre-ranking system from an algorithm-system co-design view. Instead of saving computing power with restriction of model architecture which causes loss of model performance, here we design a new pre-ranking system by joint optimization of both the pre-ranking model and the computing power it costs. We name it COLD (Computing power cost-aware Online and Lightweight Deep pre-ranking system). COLD beats SOTA in three folds: (i) an arbitrary deep model with cross features can be applied in COLD under a constraint of controllable computing power cost. (ii) computing power cost is explicitly reduced by applying optimization tricks for inference acceleration. This further brings space for COLD to apply more complex deep models to reach better performance. (iii) COLD model works in an online learning and severing manner, bringing it excellent ability to handle the challenge of the data distribution shift. Meanwhile, the fully online pre-ranking system of COLD provides us with a flexible infrastructure that supports efficient new model developing and online A/B testing.Since 2019, COLD has been deployed in almost all products involving the pre-ranking module in the display advertising system in Alibaba, bringing significant improvements.
Image Matters: Visually modeling user behaviors using Advanced Model Server
Sep 04, 2018



In Taobao, the largest e-commerce platform in China, billions of items are provided and typically displayed with their images. For better user experience and business effectiveness, Click Through Rate (CTR) prediction in online advertising system exploits abundant user historical behaviors to identify whether a user is interested in a candidate ad. Enhancing behavior representations with user behavior images will help understand user's visual preference and improve the accuracy of CTR prediction greatly. So we propose to model user preference jointly with user behavior ID features and behavior images. However, training with user behavior images brings tens to hundreds of images in one sample, giving rise to a great challenge in both communication and computation. To handle these challenges, we propose a novel and efficient distributed machine learning paradigm called Advanced Model Server (AMS). With the well known Parameter Server (PS) framework, each server node handles a separate part of parameters and updates them independently. AMS goes beyond this and is designed to be capable of learning a unified image descriptor model shared by all server nodes which embeds large images into low dimensional high level features before transmitting images to worker nodes. AMS thus dramatically reduces the communication load and enables the arduous joint training process. Based on AMS, the methods of effectively combining the images and ID features are carefully studied, and then we propose a Deep Image CTR Model. Our approach is shown to achieve significant improvements in both online and offline evaluations, and has been deployed in Taobao display advertising system serving the main traffic.
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
Apr 24, 2018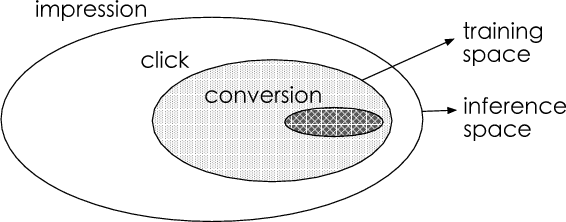

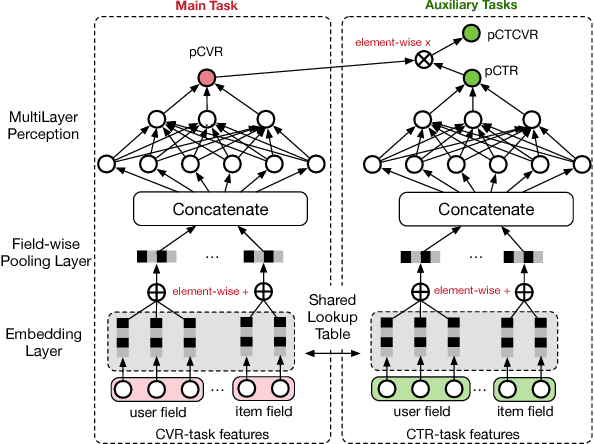

Estimating post-click conversion rate (CVR) accurately is crucial for ranking systems in industrial applications such as recommendation and advertising. Conventional CVR modeling applies popular deep learning methods and achieves state-of-the-art performance. However it encounters several task-specific problems in practice, making CVR modeling challenging. For example, conventional CVR models are trained with samples of clicked impressions while utilized to make inference on the entire space with samples of all impressions. This causes a sample selection bias problem. Besides, there exists an extreme data sparsity problem, making the model fitting rather difficult. In this paper, we model CVR in a brand-new perspective by making good use of sequential pattern of user actions, i.e., impression -> click -> conversion. The proposed Entire Space Multi-task Model (ESMM) can eliminate the two problems simultaneously by i) modeling CVR directly over the entire space, ii) employing a feature representation transfer learning strategy. Experiments on dataset gathered from Taobao's recommender system demonstrate that ESMM significantly outperforms competitive methods. We also release a sampling version of this dataset to enable future research. To the best of our knowledge, this is the first public dataset which contains samples with sequential dependence of click and conversion labels for CVR modeling.