 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Prediction Models
Sep 04, 2022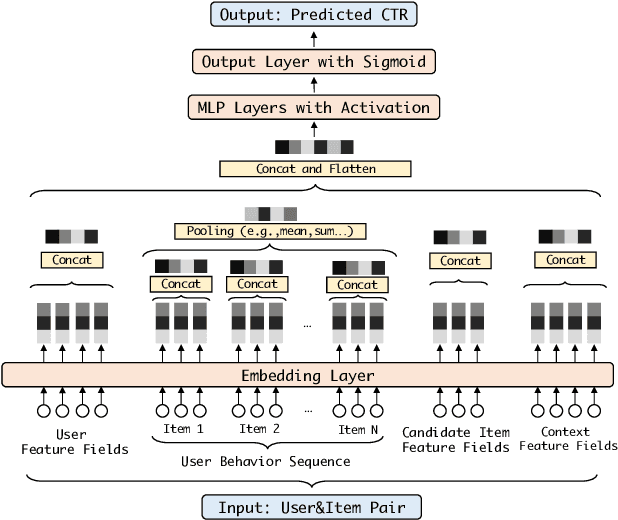
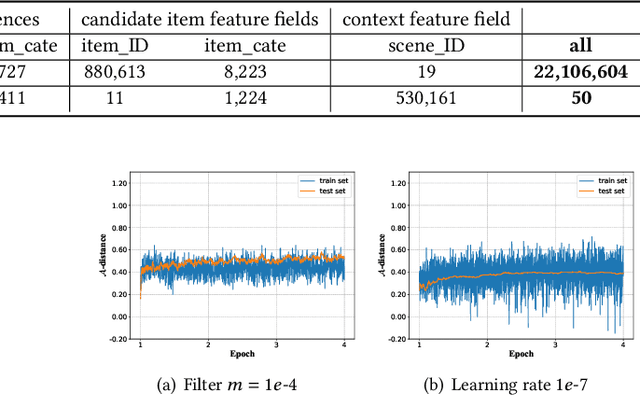
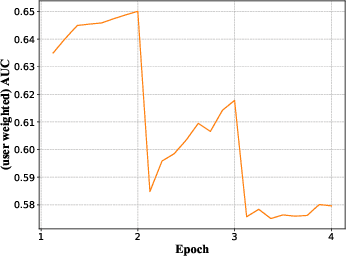

Deep learning techniques have been applied widely in industrial recommendation systems. However, far less attention has been paid to the overfitting problem of models in recommendation systems, which, on the contrary, is recognized as a critical issue for deep neural networks. In the context of Click-Through Rate (CTR) prediction, we observe an interesting one-epoch overfitting problem: the model performance exhibits a dramatic degradation at the beginning of the second epoch. Such a phenomenon has been witnessed widely in real-world applications of CTR models. Thereby, the best performance is usually achieved by training with only one epoch. To understand the underlying factors behind the one-epoch phenomenon, we conduct extensive experiments on the production data set collected from the display advertising system of Alibaba. The results show that the model structure, the optimization algorithm with a fast convergence rate, and the feature sparsity are closely related to the one-epoch phenomenon. We also provide a likely hypothesis for explaining such a phenomenon and conduct a set of proof-of-concept experiments. We hope this work can shed light on future research on training more epochs for better performance.
Truncation-Free Matching System for Display Advertising at Alibaba
Feb 18, 2021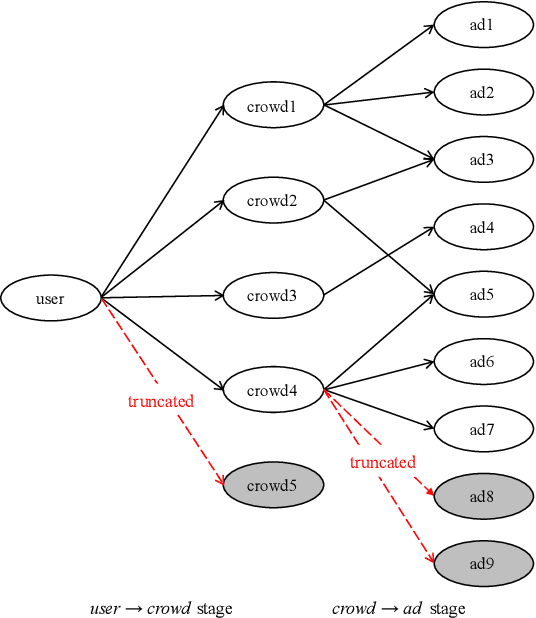


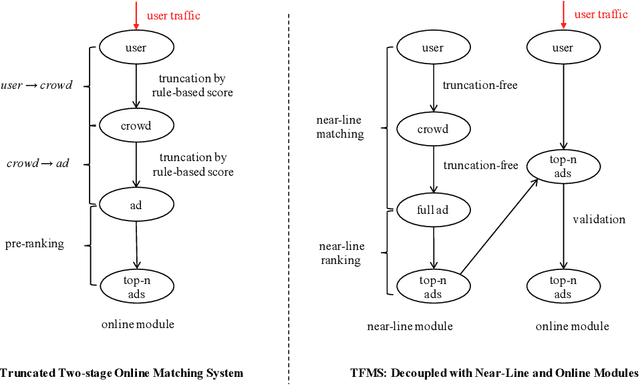
Matching module plays a critical role in display advertising systems. Without query from user, it is challenging for system to match user traffic and ads suitably. System packs up a group of users with common properties such as the same gender or similar shopping interests into a crowd. Here term crowd can be viewed as a tag over users. Then advertisers bid for different crowds and deliver their ads to those targeted users. Matching module in most industrial display advertising systems follows a two-stage paradigm. When receiving a user request, matching system (i) finds the crowds that the user belongs to; (ii) retrieves all ads that have targeted those crowds. However, in applications such as display advertising at Alibaba, with very large volumes of crowds and ads, both stages of matching have to truncate the long-tailed parts for online serving, under limited latency. That's to say, not all ads have the chance to participate in online matching. This results in sub-optimal result for both advertising performance and platform revenue. In this paper, we study the truncation problem and propose a Truncation Free Matching System (TFMS). The basic idea is to decouple the matching computation from the online pipeline. Instead of executing the two-stage matching when user visits, TFMS utilizes a near-line truncation-free matching to pre-calculate and store those top valuable ads for each user. Then the online pipeline just needs to fetch the pre-stored ads as matching results. In this way, we can jump out of online system's latency and computation cost limitations, and leverage flexible computation resource to finish the user-ad matching. TFMS has been deployed in our productive system since 2019, bringing (i) more than 50% improvement of impressions for advertisers who encountered truncation before, (ii) 9.4% Revenue Per Mile gain, which is significant enough for the business.
COLD: Towards the Next Generation of Pre-Ranking System
Aug 17, 2020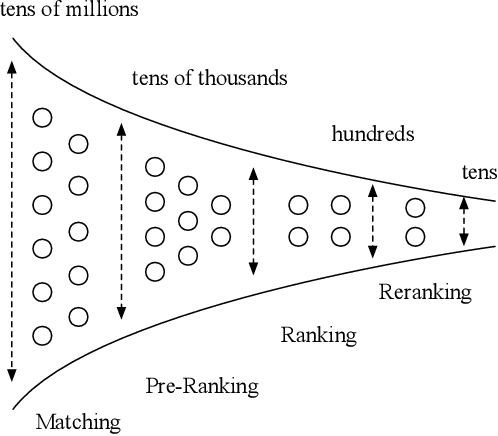

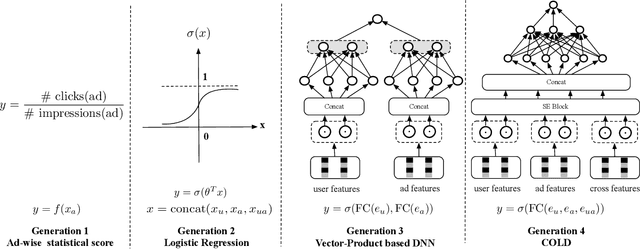

Multi-stage cascade architecture exists widely in many industrial systems such as recommender systems and online advertising, which often consists of sequential modules including matching, pre-ranking, ranking, etc. For a long time, it is believed pre-ranking is just a simplified version of the ranking module, considering the larger size of the candidate set to be ranked. Thus, efforts are made mostly on simplifying ranking model to handle the explosion of computing power for online inference. In this paper, we rethink the challenge of the pre-ranking system from an algorithm-system co-design view. Instead of saving computing power with restriction of model architecture which causes loss of model performance, here we design a new pre-ranking system by joint optimization of both the pre-ranking model and the computing power it costs. We name it COLD (Computing power cost-aware Online and Lightweight Deep pre-ranking system). COLD beats SOTA in three folds: (i) an arbitrary deep model with cross features can be applied in COLD under a constraint of controllable computing power cost. (ii) computing power cost is explicitly reduced by applying optimization tricks for inference acceleration. This further brings space for COLD to apply more complex deep models to reach better performance. (iii) COLD model works in an online learning and severing manner, bringing it excellent ability to handle the challenge of the data distribution shift. Meanwhile, the fully online pre-ranking system of COLD provides us with a flexible infrastructure that supports efficient new model developing and online A/B testing.Since 2019, COLD has been deployed in almost all products involving the pre-ranking module in the display advertising system in Alibaba, bringing significant improvements.
DCAF: A Dynamic Computation Allocation Framework for Online Serving System
Jun 17, 2020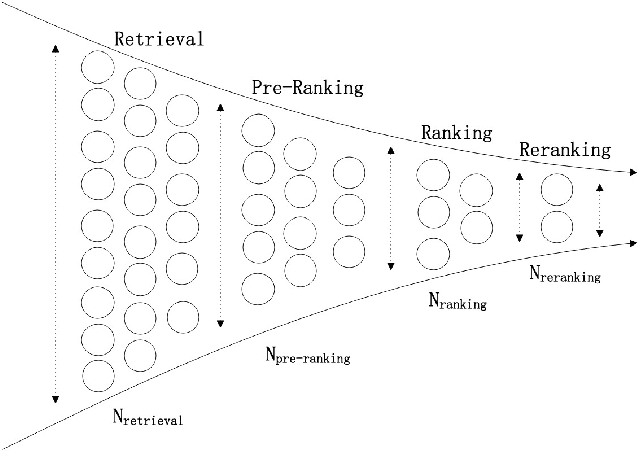
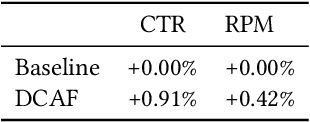
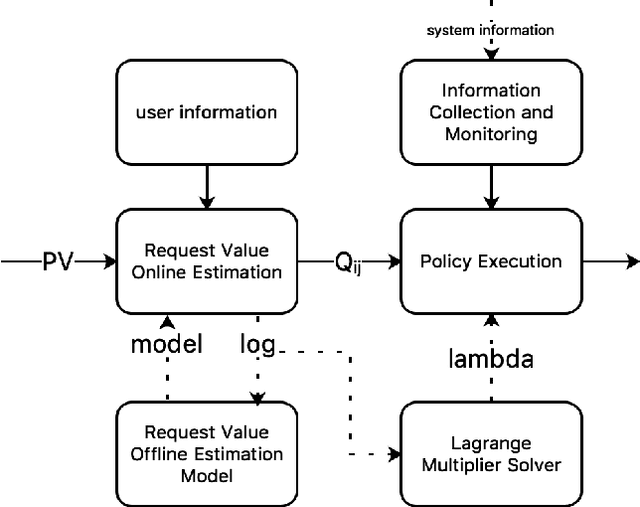

Modern large-scale systems such as recommender system and online advertising system are built upon computation-intensive infrastructure. The typical objective in these applications is to maximize the total revenue, e.g. GMV~(Gross Merchandise Volume), under a limited computation resource. Usually, the online serving system follows a multi-stage cascade architecture, which consists of several stages including retrieval, pre-ranking, ranking, etc. These stages usually allocate resource manually with specific computing power budgets, which requires the serving configuration to adapt accordingly. As a result, the existing system easily falls into suboptimal solutions with respect to maximizing the total revenue. The limitation is due to the face that, although the value of traffic requests vary greatly, online serving system still spends equal computing power among them. In this paper, we introduce a novel idea that online serving system could treat each traffic request differently and allocate "personalized" computation resource based on its value. We formulate this resource allocation problem as a knapsack problem and propose a Dynamic Computation Allocation Framework~(DCAF). Under some general assumptions, DCAF can theoretically guarantee that the system can maximize the total revenue within given computation budget. DCAF brings significant improvement and has been deployed in the display advertising system of Taobao for serving the main traffic. With DCAF, we are able to maintain the same business performance with 20\% computation resource reduction.
Diagnostic Visualization for Deep Neural Networks Using Stochastic Gradient Langevin Dynamics
Dec 11, 2018

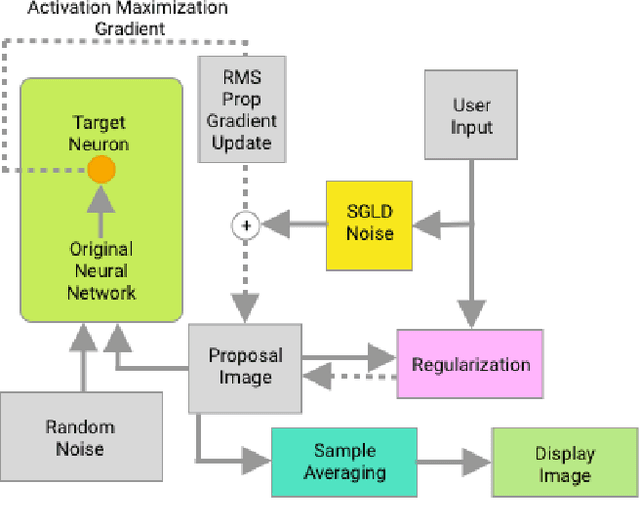

The internal states of most deep neural networks are difficult to interpret, which makes diagnosis and debugging during training challenging. Activation maximization methods are widely used, but lead to multiple optima and are hard to interpret (appear noise-like) for complex neurons. Image-based methods use maximally-activating image regions which are easier to interpret, but do not provide pixel-level insight into why the neuron responds to them. In this work we introduce an MCMC method: Langevin Dynamics Activation Maximization (LDAM), which is designed for diagnostic visualization. LDAM provides two affordances in combination: the ability to explore the set of maximally activating pre-images, and the ability to trade-off interpretability and pixel-level accuracy using a GAN-style discriminator as a regularizer. We present case studies on MNIST, CIFAR and ImageNet datasets exploring these trade-offs. Finally we show that diagnostic visualization using LDAM leads to a novel insight into the parameter averaging method for deep net training.
SAME but Different: Fast and High-Quality Gibbs Parameter Estimation
Sep 18, 2014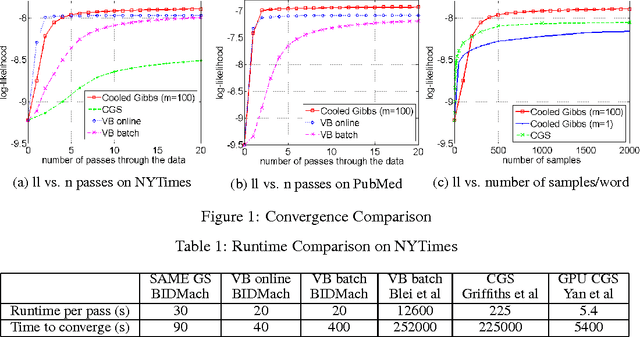
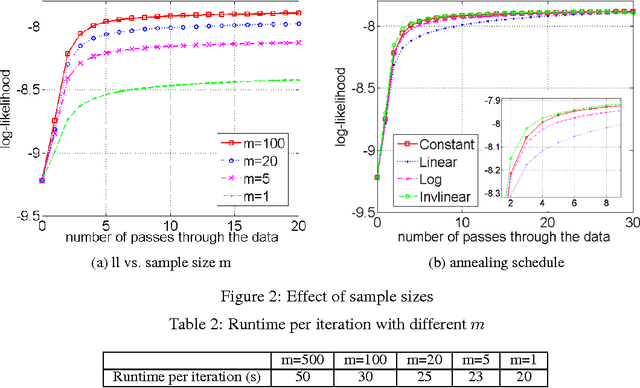
Gibbs sampling is a workhorse for Bayesian inference but has several limitations when used for parameter estimation, and is often much slower than non-sampling inference methods. SAME (State Augmentation for Marginal Estimation) \cite{Doucet99,Doucet02} is an approach to MAP parameter estimation which gives improved parameter estimates over direct Gibbs sampling. SAME can be viewed as cooling the posterior parameter distribution and allows annealed search for the MAP parameters, often yielding very high quality (lower loss) estimates. But it does so at the expense of additional samples per iteration and generally slower performance. On the other hand, SAME dramatically increases the parallelism in the sampling schedule, and is an excellent match for modern (SIMD) hardware. In this paper we explore the application of SAME to graphical model inference on modern hardware. We show that combining SAME with factored sample representation (or approximation) gives throughput competitive with the fastest symbolic methods, but with potentially better quality. We describe experiments on Latent Dirichlet Allocation, achieving speeds similar to the fastest reported methods (online Variational Bayes) and lower cross-validated loss than other LDA implementations. The method is simple to implement and should be applicable to many other models.