 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Collaboration Reconfigures Group Regulation from Socially Shared to Hybrid Co-Regulation
Apr 09, 2026Generative AI (GenAI) is increasingly used in collaborative learning, yet its effects on how groups regulate collaboration remain unclear. Effective collaboration depends not only on what groups discuss, but on how they jointly manage goals, participation, strategy use, monitoring, and repair through co-regulation and socially shared regulation. We compared collaborative regulation between Human-AI and Human-Human groups in a parallel-group randomised experiment with 71 university students completing the same collaborative tasks with GenAI either available or unavailable. Focusing on human discourse, we used statistical analyses to examine differences in the distribution of collaborative regulation across regulatory modes, regulatory processes, and participatory focuses. Results showed that GenAI availability shifted regulation away from predominantly socially shared forms towards more hybrid co-regulatory forms, with selective increases in directive, obstacle-oriented, and affective regulatory processes. Participatory-focus distributions, however, were broadly similar across conditions. These findings suggest that GenAI reshapes the distribution of regulatory responsibility in collaboration and offer implications for the human-centred design of AI-supported collaborative learning.
LogicPoison: Logical Attacks on Graph Retrieval-Augmented Generation
Apr 03, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) enhances the reasoning capabilities of Large Language Models (LLMs) by grounding their responses in structured knowledge graphs. Leveraging community detection and relation filtering techniques, GraphRAG systems demonstrate inherent resistance to traditional RAG attacks, such as text poisoning and prompt injection. However, in this paper, we find that the security of GraphRAG systems fundamentally relies on the topological integrity of the underlying graph, which can be undermined by implicitly corrupting the logical connections, without altering surface-level text semantics. To exploit this vulnerability, we propose \textsc{LogicPoison}, a novel attack framework that targets logical reasoning rather than injecting false contents. Specifically, \textsc{LogicPoison} employs a type-preserving entity swapping mechanism to perturb both global logic hubs for disrupting overall graph connectivity and query-specific reasoning bridges for severing essential multi-hop inference paths. This approach effectively reroutes valid reasoning into dead ends while maintaining surface-level textual plausibility. Comprehensive experiments across multiple benchmarks demonstrate that \textsc{LogicPoison} successfully bypasses GraphRAG's defenses, significantly degrading performance and outperforming state-of-the-art baselines in both effectiveness and stealth. Our code is available at \textcolor{blue}https://github.com/Jord8061/logicPoison.
Graph-based Agent Memory: Taxonomy, Techniques, and Applications
Feb 05, 2026Memory emerges as the core module in the Large Language Model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. Among diverse paradigms, graph stands out as a powerful structure for agent memory due to the intrinsic capabilities to model relational dependencies, organize hierarchical information, and support efficient retrieval. This survey presents a comprehensive review of agent memory from the graph-based perspective. First, we introduce a taxonomy of agent memory, including short-term vs. long-term memory, knowledge vs. experience memory, non-structural vs. structural memory, with an implementation view of graph-based memory. Second, according to the life cycle of agent memory, we systematically analyze the key techniques in graph-based agent memory, covering memory extraction for transforming the data into the contents, storage for organizing the data efficiently, retrieval for retrieving the relevant contents from memory to support reasoning, and evolution for updating the contents in the memory. Third, we summarize the open-sourced libraries and benchmarks that support the development and evaluation of self-evolving agent memory. We also explore diverse application scenarios. Finally, we identify critical challenges and future research directions. This survey aims to offer actionable insights to advance the development of more efficient and reliable graph-based agent memory systems. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/DEEP-PolyU/Awesome-GraphMemory.
Expectations, Explanations, and Embodiment: Attempts at Robot Failure Recovery
Apr 09, 2025
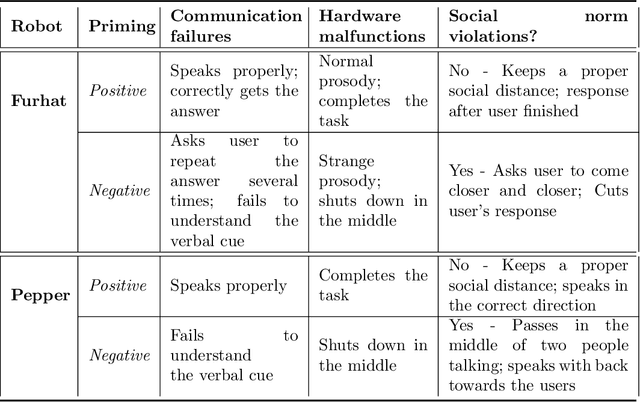
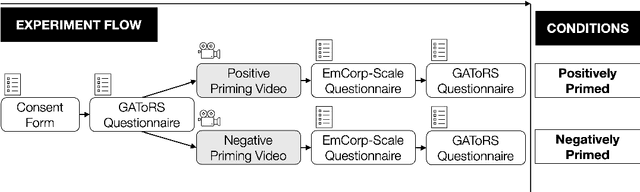
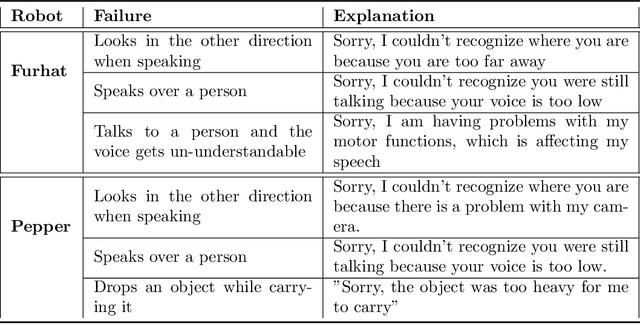
Expectations critically shape how people form judgments about robots, influencing whether they view failures as minor technical glitches or deal-breaking flaws. This work explores how high and low expectations, induced through brief video priming, affect user perceptions of robot failures and the utility of explanations in HRI. We conducted two online studies ($N=600$ total participants); each replicated two robots with different embodiments, Furhat and Pepper. In our first study, grounded in expectation theory, participants were divided into two groups, one primed with positive and the other with negative expectations regarding the robot's performance, establishing distinct expectation frameworks. This validation study aimed to verify whether the videos could reliably establish low and high-expectation profiles. In the second study, participants were primed using the validated videos and then viewed a new scenario in which the robot failed at a task. Half viewed a version where the robot explained its failure, while the other half received no explanation. We found that explanations significantly improved user perceptions of Furhat, especially when participants were primed to have lower expectations. Explanations boosted satisfaction and enhanced the robot's perceived expressiveness, indicating that effectively communicating the cause of errors can help repair user trust. By contrast, Pepper's explanations produced minimal impact on user attitudes, suggesting that a robot's embodiment and style of interaction could determine whether explanations can successfully offset negative impressions. Together, these findings underscore the need to consider users' expectations when tailoring explanation strategies in HRI. When expectations are initially low, a cogent explanation can make the difference between dismissing a failure and appreciating the robot's transparency and effort to communicate.
Benchmarking Large Language Models via Random Variables
Jan 20, 2025With the continuous advancement of large language models (LLMs) in mathematical reasoning, evaluating their performance in this domain has become a prominent research focus. Recent studies have raised concerns about the reliability of current mathematical benchmarks, highlighting issues such as simplistic design and potential data leakage. Therefore, creating a reliable benchmark that effectively evaluates the genuine capabilities of LLMs in mathematical reasoning remains a significant challenge. To address this, we propose RV-Bench, a framework for Benchmarking LLMs via Random Variables in mathematical reasoning. Specifically, the background content of a random variable question (RV question) mirrors the original problem in existing standard benchmarks, but the variable combinations are randomized into different values. LLMs must fully understand the problem-solving process for the original problem to correctly answer RV questions with various combinations of variable values. As a result, the LLM's genuine capability in mathematical reasoning is reflected by its accuracy on RV-Bench. Extensive experiments are conducted with 29 representative LLMs across 900+ RV questions. A leaderboard for RV-Bench ranks the genuine capability of these LLMs. Further analysis of accuracy dropping indicates that current LLMs still struggle with complex mathematical reasoning problems.
Surveying the space of descriptions of a composite system with machine learning
Nov 27, 2024


Multivariate information theory provides a general and principled framework for understanding how the components of a complex system are connected. Existing analyses are coarse in nature -- built up from characterizations of discrete subsystems -- and can be computationally prohibitive. In this work, we propose to study the continuous space of possible descriptions of a composite system as a window into its organizational structure. A description consists of specific information conveyed about each of the components, and the space of possible descriptions is equivalent to the space of lossy compression schemes of the components. We introduce a machine learning framework to optimize descriptions that extremize key information theoretic quantities used to characterize organization, such as total correlation and O-information. Through case studies on spin systems, Sudoku boards, and letter sequences from natural language, we identify extremal descriptions that reveal how system-wide variation emerges from individual components. By integrating machine learning into a fine-grained information theoretic analysis of composite random variables, our framework opens a new avenues for probing the structure of real-world complex systems.
Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights
Jul 28, 2024



Despite the recognized potential of multimodal data to improve model accuracy, many large-scale industrial recommendation systems, including Taobao display advertising system, predominantly depend on sparse ID features in their models. In this work, we explore approaches to leverage multimodal data to enhance the recommendation accuracy. We start from identifying the key challenges in adopting multimodal data in a manner that is both effective and cost-efficient for industrial systems. To address these challenges, we introduce a two-phase framework, including: 1) the pre-training of multimodal representations to capture semantic similarity, and 2) the integration of these representations with existing ID-based models. Furthermore, we detail the architecture of our production system, which is designed to facilitate the deployment of multimodal representations. Since the integration of multimodal representations in mid-2023, we have observed significant performance improvements in Taobao display advertising system. We believe that the insights we have gathered will serve as a valuable resource for practitioners seeking to leverage multimodal data in their systems.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.