 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
Feb 24, 2025Large Language Model (LLM)-based cold-start recommendation systems continue to face significant computational challenges in billion-scale scenarios, as they follow a "Text-to-Judgment" paradigm. This approach processes user-item content pairs as input and evaluates each pair iteratively. To maintain efficiency, existing methods rely on pre-filtering a small candidate pool of user-item pairs. However, this severely limits the inferential capabilities of LLMs by reducing their scope to only a few hundred pre-filtered candidates. To overcome this limitation, we propose a novel "Text-to-Distribution" paradigm, which predicts an item's interaction probability distribution for the entire user set in a single inference. Specifically, we present FilterLLM, a framework that extends the next-word prediction capabilities of LLMs to billion-scale filtering tasks. FilterLLM first introduces a tailored distribution prediction and cold-start framework. Next, FilterLLM incorporates an efficient user-vocabulary structure to train and store the embeddings of billion-scale users. Finally, we detail the training objectives for both distribution prediction and user-vocabulary construction. The proposed framework has been deployed on the Alibaba platform, where it has been serving cold-start recommendations for two months, processing over one billion cold items. Extensive experiments demonstrate that FilterLLM significantly outperforms state-of-the-art methods in cold-start recommendation tasks, achieving over 30 times higher efficiency. Furthermore, an online A/B test validates its effectiveness in billion-scale recommendation systems.
Knapsack Optimization-based Schema Linking for LLM-based Text-to-SQL Generation
Feb 18, 2025Generating SQLs from user queries is a long-standing challenge, where the accuracy of initial schema linking significantly impacts subsequent SQL generation performance. However, current schema linking models still struggle with missing relevant schema elements or an excess of redundant ones. A crucial reason for this is that commonly used metrics, recall and precision, fail to capture relevant element missing and thus cannot reflect actual schema linking performance. Motivated by this, we propose an enhanced schema linking metric by introducing a restricted missing indicator. Accordingly, we introduce Knapsack optimization-based Schema Linking Agent (KaSLA), a plug-in schema linking agent designed to prevent the missing of relevant schema elements while minimizing the inclusion of redundant ones. KaSLA employs a hierarchical linking strategy that first identifies the optimal table linking and subsequently links columns within the selected table to reduce linking candidate space. In each linking process, it utilize a knapsack optimization approach to link potentially relevant elements while accounting for a limited tolerance of potential redundant ones.With this optimization, KaSLA-1.6B achieves superior schema linking results compared to large-scale LLMs, including deepseek-v3 with state-of-the-art (SOTA) schema linking method. Extensive experiments on Spider and BIRD benchmarks verify that KaSLA can significantly improve the SQL generation performance of SOTA text-to-SQL models by substituting their schema linking processes.
Benchmarking Large Language Models via Random Variables
Jan 20, 2025With the continuous advancement of large language models (LLMs) in mathematical reasoning, evaluating their performance in this domain has become a prominent research focus. Recent studies have raised concerns about the reliability of current mathematical benchmarks, highlighting issues such as simplistic design and potential data leakage. Therefore, creating a reliable benchmark that effectively evaluates the genuine capabilities of LLMs in mathematical reasoning remains a significant challenge. To address this, we propose RV-Bench, a framework for Benchmarking LLMs via Random Variables in mathematical reasoning. Specifically, the background content of a random variable question (RV question) mirrors the original problem in existing standard benchmarks, but the variable combinations are randomized into different values. LLMs must fully understand the problem-solving process for the original problem to correctly answer RV questions with various combinations of variable values. As a result, the LLM's genuine capability in mathematical reasoning is reflected by its accuracy on RV-Bench. Extensive experiments are conducted with 29 representative LLMs across 900+ RV questions. A leaderboard for RV-Bench ranks the genuine capability of these LLMs. Further analysis of accuracy dropping indicates that current LLMs still struggle with complex mathematical reasoning problems.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
HNCSE: Advancing Sentence Embeddings via Hybrid Contrastive Learning with Hard Negatives
Nov 19, 2024Unsupervised sentence representation learning remains a critical challenge in modern natural language processing (NLP) research. Recently, contrastive learning techniques have achieved significant success in addressing this issue by effectively capturing textual semantics. Many such approaches prioritize the optimization using negative samples. In fields such as computer vision, hard negative samples (samples that are close to the decision boundary and thus more difficult to distinguish) have been shown to enhance representation learning. However, adapting hard negatives to contrastive sentence learning is complex due to the intricate syntactic and semantic details of text. To address this problem, we propose HNCSE, a novel contrastive learning framework that extends the leading SimCSE approach. The hallmark of HNCSE is its innovative use of hard negative samples to enhance the learning of both positive and negative samples, thereby achieving a deeper semantic understanding. Empirical tests on semantic textual similarity and transfer task datasets validate the superiority of HNCSE.
Graph Cross-Correlated Network for Recommendation
Nov 02, 2024

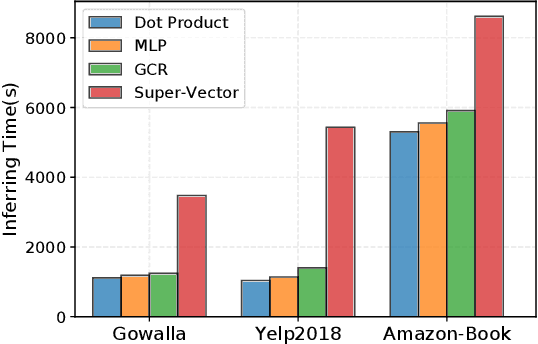

Collaborative filtering (CF) models have demonstrated remarkable performance in recommender systems, which represent users and items as embedding vectors. Recently, due to the powerful modeling capability of graph neural networks for user-item interaction graphs, graph-based CF models have gained increasing attention. They encode each user/item and its subgraph into a single super vector by combining graph embeddings after each graph convolution. However, each hop of the neighbor in the user-item subgraphs carries a specific semantic meaning. Encoding all subgraph information into single vectors and inferring user-item relations with dot products can weaken the semantic information between user and item subgraphs, thus leaving untapped potential. Exploiting this untapped potential provides insight into improving performance for existing recommendation models. To this end, we propose the Graph Cross-correlated Network for Recommendation (GCR), which serves as a general recommendation paradigm that explicitly considers correlations between user/item subgraphs. GCR first introduces the Plain Graph Representation (PGR) to extract information directly from each hop of neighbors into corresponding PGR vectors. Then, GCR develops Cross-Correlated Aggregation (CCA) to construct possible cross-correlated terms between PGR vectors of user/item subgraphs. Finally, GCR comprehensively incorporates the cross-correlated terms for recommendations. Experimental results show that GCR outperforms state-of-the-art models on both interaction prediction and click-through rate prediction tasks.
CLR-Bench: Evaluating Large Language Models in College-level Reasoning
Oct 23, 2024



Large language models (LLMs) have demonstrated their remarkable performance across various language understanding tasks. While emerging benchmarks have been proposed to evaluate LLMs in various domains such as mathematics and computer science, they merely measure the accuracy in terms of the final prediction on multi-choice questions. However, it remains insufficient to verify the essential understanding of LLMs given a chosen choice. To fill this gap, we present CLR-Bench to comprehensively evaluate the LLMs in complex college-level reasoning. Specifically, (i) we prioritize 16 challenging college disciplines in computer science and artificial intelligence. The dataset contains 5 types of questions, while each question is associated with detailed explanations from experts. (ii) To quantify a fair evaluation of LLMs' reasoning ability, we formalize the criteria with two novel metrics. Q$\rightarrow$A is utilized to measure the performance of direct answer prediction, and Q$\rightarrow$AR effectively considers the joint ability to answer the question and provide rationale simultaneously. Extensive experiments are conducted with 40 LLMs over 1,018 discipline-specific questions. The results demonstrate the key insights that LLMs, even the best closed-source LLM, i.e., GPT-4 turbo, tend to `guess' the college-level answers. It shows a dramatic decrease in accuracy from 63.31% Q$\rightarrow$A to 39.00% Q$\rightarrow$AR, indicating an unsatisfactory reasoning ability.
Graph Neural Patching for Cold-Start Recommendations
Oct 18, 2024



The cold start problem in recommender systems remains a critical challenge. Current solutions often train hybrid models on auxiliary data for both cold and warm users/items, potentially degrading the experience for the latter. This drawback limits their viability in practical scenarios where the satisfaction of existing warm users/items is paramount. Although graph neural networks (GNNs) excel at warm recommendations by effective collaborative signal modeling, they haven't been effectively leveraged for the cold-start issue within a user-item graph, which is largely due to the lack of initial connections for cold user/item entities. Addressing this requires a GNN adept at cold-start recommendations without sacrificing performance for existing ones. To this end, we introduce Graph Neural Patching for Cold-Start Recommendations (GNP), a customized GNN framework with dual functionalities: GWarmer for modeling collaborative signal on existing warm users/items and Patching Networks for simulating and enhancing GWarmer's performance on cold-start recommendations. Extensive experiments on three benchmark datasets confirm GNP's superiority in recommending both warm and cold users/items.
Feedback Reciprocal Graph Collaborative Filtering
Aug 05, 2024Collaborative filtering on user-item interaction graphs has achieved success in the industrial recommendation. However, recommending users' truly fascinated items poses a seesaw dilemma for collaborative filtering models learned from the interaction graph. On the one hand, not all items that users interact with are equally appealing. Some items are genuinely fascinating to users, while others are unfascinated. Training graph collaborative filtering models in the absence of distinction between them can lead to the recommendation of unfascinating items to users. On the other hand, disregarding the interacted but unfascinating items during graph collaborative filtering will result in an incomplete representation of users' interaction intent, leading to a decline in the model's recommendation capabilities. To address this seesaw problem, we propose Feedback Reciprocal Graph Collaborative Filtering (FRGCF), which emphasizes the recommendation of fascinating items while attenuating the recommendation of unfascinating items. Specifically, FRGCF first partitions the entire interaction graph into the Interacted & Fascinated (I&F) graph and the Interacted & Unfascinated (I&U) graph based on the user feedback. Then, FRGCF introduces separate collaborative filtering on the I&F graph and the I&U graph with feedback-reciprocal contrastive learning and macro-level feedback modeling. This enables the I&F graph recommender to learn multi-grained interaction characteristics from the I&U graph without being misdirected by it. Extensive experiments on four benchmark datasets and a billion-scale industrial dataset demonstrate that FRGCF improves the performance by recommending more fascinating items and fewer unfascinating items. Besides, online A/B tests on Taobao's recommender system verify the superiority of FRGCF.
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Jun 12, 2024Generating accurate SQL according to natural language questions (text-to-SQL) is a long-standing problem since it is challenging in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems include human engineering and deep neural networks. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex and corresponding user questions more challenging, PLMs with limited comprehension capabilities can lead to incorrect SQL generation. This necessitates more sophisticated and tailored optimization methods, which, in turn, restricts the applications of PLM-based systems. Most recently, large language models (LLMs) have demonstrated significant abilities in natural language understanding as the model scale remains increasing. Therefore, integrating the LLM-based implementation can bring unique opportunities, challenges, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the current challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future directions.