 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Agent Memory: Taxonomy, Techniques, and Applications
Feb 05, 2026Memory emerges as the core module in the Large Language Model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. Among diverse paradigms, graph stands out as a powerful structure for agent memory due to the intrinsic capabilities to model relational dependencies, organize hierarchical information, and support efficient retrieval. This survey presents a comprehensive review of agent memory from the graph-based perspective. First, we introduce a taxonomy of agent memory, including short-term vs. long-term memory, knowledge vs. experience memory, non-structural vs. structural memory, with an implementation view of graph-based memory. Second, according to the life cycle of agent memory, we systematically analyze the key techniques in graph-based agent memory, covering memory extraction for transforming the data into the contents, storage for organizing the data efficiently, retrieval for retrieving the relevant contents from memory to support reasoning, and evolution for updating the contents in the memory. Third, we summarize the open-sourced libraries and benchmarks that support the development and evaluation of self-evolving agent memory. We also explore diverse application scenarios. Finally, we identify critical challenges and future research directions. This survey aims to offer actionable insights to advance the development of more efficient and reliable graph-based agent memory systems. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/DEEP-PolyU/Awesome-GraphMemory.
Use Graph When It Needs: Efficiently and Adaptively Integrating Retrieval-Augmented Generation with Graphs
Feb 03, 2026Large language models (LLMs) often struggle with knowledge-intensive tasks due to hallucinations and outdated parametric knowledge. While Retrieval-Augmented Generation (RAG) addresses this by integrating external corpora, its effectiveness is limited by fragmented information in unstructured domain documents. Graph-augmented RAG (GraphRAG) emerged to enhance contextual reasoning through structured knowledge graphs, yet paradoxically underperforms vanilla RAG in real-world scenarios, exhibiting significant accuracy drops and prohibitive latency despite gains on complex queries. We identify the rigid application of GraphRAG to all queries, regardless of complexity, as the root cause. To resolve this, we propose an efficient and adaptive GraphRAG framework called EA-GraphRAG that dynamically integrates RAG and GraphRAG paradigms through syntax-aware complexity analysis. Our approach introduces: (i) a syntactic feature constructor that parses each query and extracts a set of structural features; (ii) a lightweight complexity scorer that maps these features to a continuous complexity score; and (iii) a score-driven routing policy that selects dense RAG for low-score queries, invokes graph-based retrieval for high-score queries, and applies complexity-aware reciprocal rank fusion to handle borderline cases. Extensive experiments on a comprehensive benchmark, consisting of two single-hop and two multi-hop QA benchmarks, demonstrate that our EA-GraphRAG significantly improves accuracy, reduces latency, and achieves state-of-the-art performance in handling mixed scenarios involving both simple and complex queries.
You Don't Need Pre-built Graphs for RAG: Retrieval Augmented Generation with Adaptive Reasoning Structures
Aug 08, 2025Large language models (LLMs) often suffer from hallucination, generating factually incorrect statements when handling questions beyond their knowledge and perception. Retrieval-augmented generation (RAG) addresses this by retrieving query-relevant contexts from knowledge bases to support LLM reasoning. Recent advances leverage pre-constructed graphs to capture the relational connections among distributed documents, showing remarkable performance in complex tasks. However, existing Graph-based RAG (GraphRAG) methods rely on a costly process to transform the corpus into a graph, introducing overwhelming token cost and update latency. Moreover, real-world queries vary in type and complexity, requiring different logic structures for accurate reasoning. The pre-built graph may not align with these required structures, resulting in ineffective knowledge retrieval. To this end, we propose a \textbf{\underline{Logic}}-aware \textbf{\underline{R}}etrieval-\textbf{\underline{A}}ugmented \textbf{\underline{G}}eneration framework (\textbf{LogicRAG}) that dynamically extracts reasoning structures at inference time to guide adaptive retrieval without any pre-built graph. LogicRAG begins by decomposing the input query into a set of subproblems and constructing a directed acyclic graph (DAG) to model the logical dependencies among them. To support coherent multi-step reasoning, LogicRAG then linearizes the graph using topological sort, so that subproblems can be addressed in a logically consistent order. Besides, LogicRAG applies graph pruning to reduce redundant retrieval and uses context pruning to filter irrelevant context, significantly reducing the overall token cost. Extensive experiments demonstrate that LogicRAG achieves both superior performance and efficiency compared to state-of-the-art baselines.
LAG: Logic-Augmented Generation from a Cartesian Perspective
Aug 07, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet exhibit critical limitations in knowledge-intensive tasks, often generating hallucinations when faced with questions requiring specialized expertise. While retrieval-augmented generation (RAG) mitigates this by integrating external knowledge, it struggles with complex reasoning scenarios due to its reliance on direct semantic retrieval and lack of structured logical organization. Inspired by Cartesian principles from \textit{Discours de la m\'ethode}, this paper introduces Logic-Augmented Generation (LAG), a novel paradigm that reframes knowledge augmentation through systematic question decomposition and dependency-aware reasoning. Specifically, LAG first decomposes complex questions into atomic sub-questions ordered by logical dependencies. It then resolves these sequentially, using prior answers to guide context retrieval for subsequent sub-questions, ensuring stepwise grounding in logical chain. To prevent error propagation, LAG incorporates a logical termination mechanism that halts inference upon encountering unanswerable sub-questions and reduces wasted computation on excessive reasoning. Finally, it synthesizes all sub-resolutions to generate verified responses. Experiments on four benchmark datasets demonstrate that LAG significantly enhances reasoning robustness, reduces hallucination, and aligns LLM problem-solving with human cognition, offering a principled alternative to existing RAG systems.
When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation
Jun 06, 2025Graph retrieval-augmented generation (GraphRAG) has emerged as a powerful paradigm for enhancing large language models (LLMs) with external knowledge. It leverages graphs to model the hierarchical structure between specific concepts, enabling more coherent and effective knowledge retrieval for accurate reasoning.Despite its conceptual promise, recent studies report that GraphRAG frequently underperforms vanilla RAG on many real-world tasks. This raises a critical question: Is GraphRAG really effective, and in which scenarios do graph structures provide measurable benefits for RAG systems? To address this, we propose GraphRAG-Bench, a comprehensive benchmark designed to evaluate GraphRAG models onboth hierarchical knowledge retrieval and deep contextual reasoning. GraphRAG-Bench features a comprehensive dataset with tasks of increasing difficulty, coveringfact retrieval, complex reasoning, contextual summarization, and creative generation, and a systematic evaluation across the entire pipeline, from graph constructionand knowledge retrieval to final generation. Leveraging this novel benchmark, we systematically investigate the conditions when GraphRAG surpasses traditional RAG and the underlying reasons for its success, offering guidelines for its practical application. All related resources and analyses are collected for the community at https://github.com/GraphRAG-Bench/GraphRAG-Benchmark.
Automated Heterogeneous Network learning with Non-Recursive Message Passing
Jan 10, 2025Heterogeneous information networks (HINs) can be used to model various real-world systems. As HINs consist of multiple types of nodes, edges, and node features, it is nontrivial to directly apply graph neural network (GNN) techniques in heterogeneous cases. There are two remaining major challenges. First, homogeneous message passing in a recursive manner neglects the distinct types of nodes and edges in different hops, leading to unnecessary information mixing. This often results in the incorporation of ``noise'' from uncorrelated intermediate neighbors, thereby degrading performance. Second, feature learning should be handled differently for different types, which is challenging especially when the type sizes are large. To bridge this gap, we develop a novel framework - AutoGNR, to directly utilize and automatically extract effective heterogeneous information. Instead of recursive homogeneous message passing, we introduce a non-recursive message passing mechanism for GNN to mitigate noise from uncorrelated node types in HINs. Furthermore, under the non-recursive framework, we manage to efficiently perform neural architecture search for an optimal GNN structure in a differentiable way, which can automatically define the heterogeneous paths for aggregation. Our tailored search space encompasses more effective candidates while maintaining a tractable size. Experiments show that AutoGNR consistently outperforms state-of-the-art methods on both normal and large scale real-world HIN datasets.
Graph Cross-Correlated Network for Recommendation
Nov 02, 2024

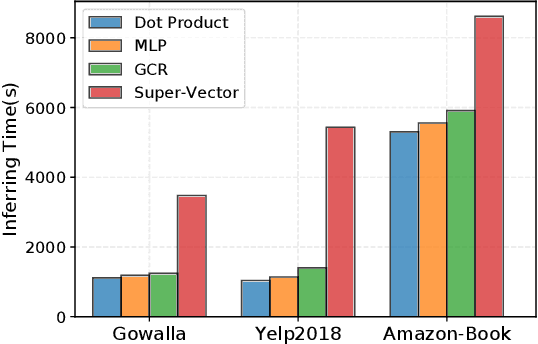

Collaborative filtering (CF) models have demonstrated remarkable performance in recommender systems, which represent users and items as embedding vectors. Recently, due to the powerful modeling capability of graph neural networks for user-item interaction graphs, graph-based CF models have gained increasing attention. They encode each user/item and its subgraph into a single super vector by combining graph embeddings after each graph convolution. However, each hop of the neighbor in the user-item subgraphs carries a specific semantic meaning. Encoding all subgraph information into single vectors and inferring user-item relations with dot products can weaken the semantic information between user and item subgraphs, thus leaving untapped potential. Exploiting this untapped potential provides insight into improving performance for existing recommendation models. To this end, we propose the Graph Cross-correlated Network for Recommendation (GCR), which serves as a general recommendation paradigm that explicitly considers correlations between user/item subgraphs. GCR first introduces the Plain Graph Representation (PGR) to extract information directly from each hop of neighbors into corresponding PGR vectors. Then, GCR develops Cross-Correlated Aggregation (CCA) to construct possible cross-correlated terms between PGR vectors of user/item subgraphs. Finally, GCR comprehensively incorporates the cross-correlated terms for recommendations. Experimental results show that GCR outperforms state-of-the-art models on both interaction prediction and click-through rate prediction tasks.
Neuro-Symbolic Entity Alignment via Variational Inference
Oct 05, 2024



Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. Existing methods can be categorized into symbolic and neural models. Symbolic models, while precise, struggle with substructure heterogeneity and sparsity, whereas neural models, although effective, generally lack interpretability and cannot handle uncertainty. We propose NeuSymEA, a probabilistic neuro-symbolic framework that combines the strengths of both methods. NeuSymEA models the joint probability of all possible pairs' truth scores in a Markov random field, regulated by a set of rules, and optimizes it with the variational EM algorithm. In the E-step, a neural model parameterizes the truth score distributions and infers missing alignments. In the M-step, the rule weights are updated based on the observed and inferred alignments. To facilitate interpretability, we further design a path-ranking-based explainer upon this framework that generates supporting rules for the inferred alignments. Experiments on benchmarks demonstrate that NeuSymEA not only significantly outperforms baselines in terms of effectiveness and robustness, but also provides interpretable results.
Entity Alignment with Noisy Annotations from Large Language Models
May 28, 2024Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. While existing methods heavily rely on human-generated labels, it is prohibitively expensive to incorporate cross-domain experts for annotation in real-world scenarios. The advent of Large Language Models (LLMs) presents new avenues for automating EA with annotations, inspired by their comprehensive capability to process semantic information. However, it is nontrivial to directly apply LLMs for EA since the annotation space in real-world KGs is large. LLMs could also generate noisy labels that may mislead the alignment. To this end, we propose a unified framework, LLM4EA, to effectively leverage LLMs for EA. Specifically, we design a novel active learning policy to significantly reduce the annotation space by prioritizing the most valuable entities based on the entire inter-KG and intra-KG structure. Moreover, we introduce an unsupervised label refiner to continuously enhance label accuracy through in-depth probabilistic reasoning. We iteratively optimize the policy based on the feedback from a base EA model. Extensive experiments demonstrate the advantages of LLM4EA on four benchmark datasets in terms of effectiveness, robustness, and efficiency. Codes are available via https://github.com/chensyCN/llm4ea_official.
QuanGCN: Noise-Adaptive Training for Robust Quantum Graph Convolutional Networks
Nov 09, 2022Quantum neural networks (QNNs), an interdisciplinary field of quantum computing and machine learning, have attracted tremendous research interests due to the specific quantum advantages. Despite lots of efforts developed in computer vision domain, one has not fully explored QNNs for the real-world graph property classification and evaluated them in the quantum device. To bridge the gap, we propose quantum graph convolutional networks (QuanGCN), which learns the local message passing among nodes with the sequence of crossing-gate quantum operations. To mitigate the inherent noises from modern quantum devices, we apply sparse constraint to sparsify the nodes' connections and relieve the error rate of quantum gates, and use skip connection to augment the quantum outputs with original node features to improve robustness. The experimental results show that our QuanGCN is functionally comparable or even superior than the classical algorithms on several benchmark graph datasets. The comprehensive evaluations in both simulator and real quantum machines demonstrate the applicability of QuanGCN to the future graph analysis problem.