 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSC: Accelerating Graph Neural Networks Training via Randomized Sparse Computations
Paper and Code
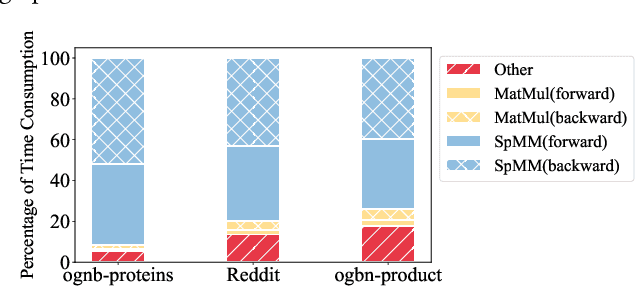



The training of graph neural networks (GNNs) is extremely time consuming because sparse graph-based operations are hard to be accelerated by hardware. Prior art explores trading off the computational precision to reduce the time complexity via sampling-based approximation. Based on the idea, previous works successfully accelerate the dense matrix based operations (e.g., convolution and linear) with negligible accuracy drop. However, unlike dense matrices, sparse matrices are stored in the irregular data format such that each row/column may have different number of non-zero entries. Thus, compared to the dense counterpart, approximating sparse operations has two unique challenges (1) we cannot directly control the efficiency of approximated sparse operation since the computation is only executed on non-zero entries; (2) sub-sampling sparse matrices is much more inefficient due to the irregular data format. To address the issues, our key idea is to control the accuracy-efficiency trade off by optimizing computation resource allocation layer-wisely and epoch-wisely. Specifically, for the first challenge, we customize the computation resource to different sparse operations, while limit the total used resource below a certain budget. For the second challenge, we cache previous sampled sparse matrices to reduce the epoch-wise sampling overhead. Finally, we propose a switching mechanisms to improve the generalization of GNNs trained with approximated operations. To this end, we propose Randomized Sparse Computation, which for the first time demonstrate the potential of training GNNs with approximated operations. In practice, rsc can achieve up to $11.6\times$ speedup for a single sparse operation and a $1.6\times$ end-to-end wall-clock time speedup with negligible accuracy drop.