 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Domains Interact: Asymmetric and Order-Sensitive Cross-Domain Effects in Reinforcement Learning for Reasoning
Feb 01, 2026Group Relative Policy Optimization (GRPO) has become a key technique for improving reasoning abilities in large language models, yet its behavior under different domain sequencing strategies is poorly understood. In particular, the impact of sequential (one domain at a time) versus mixed-domain (multiple domain at a time) training in GRPO has not been systematically studied. We provide the first systematic analysis of training-order effects across math, science, logic, and puzzle reasoning tasks. We found (1) single-domain generalization is highly asymmetric: training on other domains improves math reasoning by approximately 25\% accuracy, while yielding negligible transfer to logic and puzzle; (2) cross-domain interactions are highly order-dependent: training in the order math$\rightarrow$science achieves 83\% / 41\% accuracy on math / science, while reversing the order to science$\rightarrow$math degrades performance to 77\% / 25\%; (3) no single strategy is universally optimal in multi-domain training: sequential training favors math (up to 84\%), mixed training favors science and logic, and poor ordering can incur large performance gaps (from 70\% to 56\%). Overall, our findings demonstrate that GRPO under multi-domain settings exhibits pronounced asymmetry, order sensitivity, and strategy dependence, highlighting the necessity of domain-aware and order-aware training design.
Catastrophic Forgetting in Kolmogorov-Arnold Networks
Nov 16, 2025Catastrophic forgetting is a longstanding challenge in continual learning, where models lose knowledge from earlier tasks when learning new ones. While various mitigation strategies have been proposed for Multi-Layer Perceptrons (MLPs), recent architectural advances like Kolmogorov-Arnold Networks (KANs) have been suggested to offer intrinsic resistance to forgetting by leveraging localized spline-based activations. However, the practical behavior of KANs under continual learning remains unclear, and their limitations are not well understood. To address this, we present a comprehensive study of catastrophic forgetting in KANs and develop a theoretical framework that links forgetting to activation support overlap and intrinsic data dimension. We validate these analyses through systematic experiments on synthetic and vision tasks, measuring forgetting dynamics under varying model configurations and data complexity. Further, we introduce KAN-LoRA, a novel adapter design for parameter-efficient continual fine-tuning of language models, and evaluate its effectiveness in knowledge editing tasks. Our findings reveal that while KANs exhibit promising retention in low-dimensional algorithmic settings, they remain vulnerable to forgetting in high-dimensional domains such as image classification and language modeling. These results advance the understanding of KANs' strengths and limitations, offering practical insights for continual learning system design.
You Only Debias Once: Towards Flexible Accuracy-Fairness Trade-offs at Inference Time
Mar 10, 2025Deep neural networks are prone to various bias issues, jeopardizing their applications for high-stake decision-making. Existing fairness methods typically offer a fixed accuracy-fairness trade-off, since the weight of the well-trained model is a fixed point (fairness-optimum) in the weight space. Nevertheless, more flexible accuracy-fairness trade-offs at inference time are practically desired since: 1) stakes of the same downstream task can vary for different individuals, and 2) different regions have diverse laws or regularization for fairness. If using the previous fairness methods, we have to train multiple models, each offering a specific level of accuracy-fairness trade-off. This is often computationally expensive, time-consuming, and difficult to deploy, making it less practical for real-world applications. To address this problem, we propose You Only Debias Once (YODO) to achieve in-situ flexible accuracy-fairness trade-offs at inference time, using a single model that trained only once. Instead of pursuing one individual fixed point (fairness-optimum) in the weight space, we aim to find a "line" in the weight space that connects the accuracy-optimum and fairness-optimum points using a single model. Points (models) on this line implement varying levels of accuracy-fairness trade-offs. At inference time, by manually selecting the specific position of the learned "line", our proposed method can achieve arbitrary accuracy-fairness trade-offs for different end-users and scenarios. Experimental results on tabular and image datasets show that YODO achieves flexible trade-offs between model accuracy and fairness, at ultra-low overheads. For example, if we need $100$ levels of trade-off on the \acse dataset, YODO takes $3.53$ seconds while training $100$ fixed models consumes $425$ seconds. The code is available at https://github.com/ahxt/yodo.
LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
Mar 05, 2025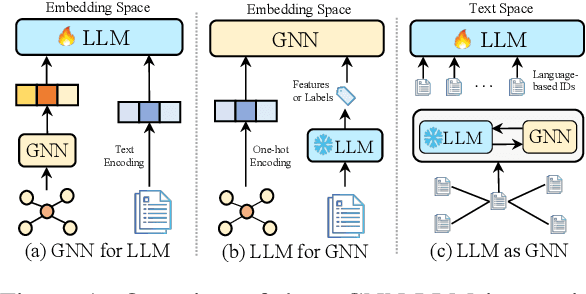
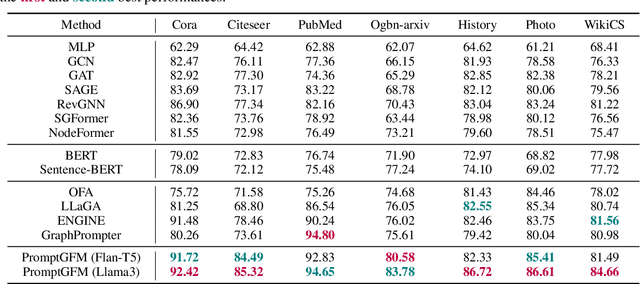
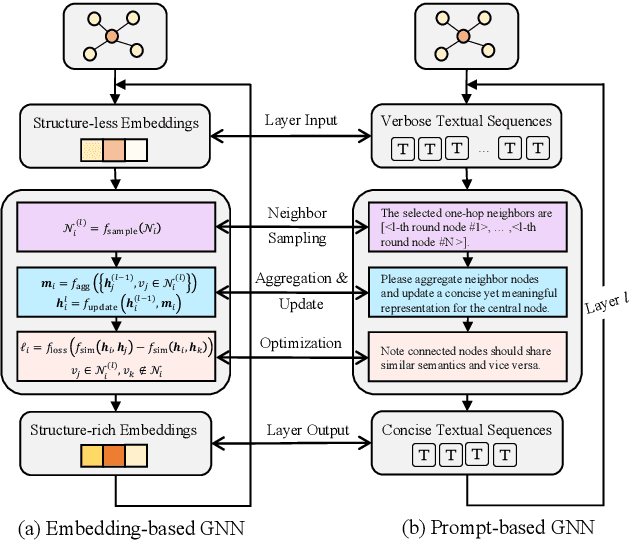
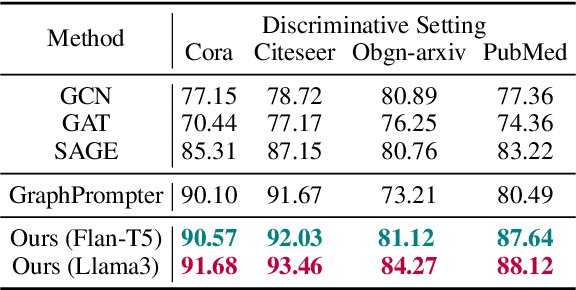
Text-Attributed Graphs (TAGs), where each node is associated with text descriptions, are ubiquitous in real-world scenarios. They typically exhibit distinctive structure and domain-specific knowledge, motivating the development of a Graph Foundation Model (GFM) that generalizes across diverse graphs and tasks. Despite large efforts to integrate Large Language Models (LLMs) and Graph Neural Networks (GNNs) for TAGs, existing approaches suffer from decoupled architectures with two-stage alignment, limiting their synergistic potential. Even worse, existing methods assign out-of-vocabulary (OOV) tokens to graph nodes, leading to graph-specific semantics, token explosion, and incompatibility with task-oriented prompt templates, which hinders cross-graph and cross-task transferability. To address these challenges, we propose PromptGFM, a versatile GFM for TAGs grounded in graph vocabulary learning. PromptGFM comprises two key components: (1) Graph Understanding Module, which explicitly prompts LLMs to replicate the finest GNN workflow within the text space, facilitating seamless GNN-LLM integration and elegant graph-text alignment; (2) Graph Inference Module, which establishes a language-based graph vocabulary ensuring expressiveness, transferability, and scalability, enabling readable instructions for LLM fine-tuning. Extensive experiments demonstrate our superiority and transferability across diverse graphs and tasks. The code is available at this: https://github.com/agiresearch/PromptGFM.
Continually Evolved Multimodal Foundation Models for Cancer Prognosis
Jan 30, 2025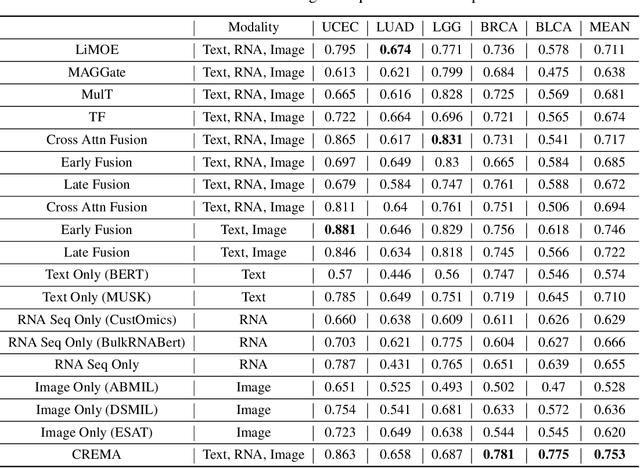
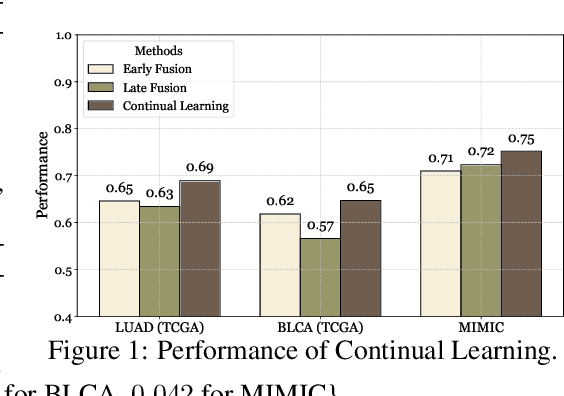
Cancer prognosis is a critical task that involves predicting patient outcomes and survival rates. To enhance prediction accuracy, previous studies have integrated diverse data modalities, such as clinical notes, medical images, and genomic data, leveraging their complementary information. However, existing approaches face two major limitations. First, they struggle to incorporate newly arrived data with varying distributions into training, such as patient records from different hospitals, thus rendering sub-optimal generalizability and limited utility in real-world applications. Second, most multimodal integration methods rely on simplistic concatenation or task-specific pipelines, which fail to capture the complex interdependencies across modalities. To address these, we propose a continually evolving multi-modal foundation model. Extensive experiments on the TCGA dataset demonstrate the effectiveness of our approach, highlighting its potential to advance cancer prognosis by enabling robust and adaptive multimodal integration.
Layer-Level Self-Exposure and Patch: Affirmative Token Mitigation for Jailbreak Attack Defense
Jan 05, 2025As large language models (LLMs) are increasingly deployed in diverse applications, including chatbot assistants and code generation, aligning their behavior with safety and ethical standards has become paramount. However, jailbreak attacks, which exploit vulnerabilities to elicit unintended or harmful outputs, threaten LLMs' safety significantly. In this paper, we introduce Layer-AdvPatcher, a novel methodology designed to defend against jailbreak attacks by utilizing an unlearning strategy to patch specific layers within LLMs through self-augmented datasets. Our insight is that certain layer(s), tend to produce affirmative tokens when faced with harmful prompts. By identifying these layers and adversarially exposing them to generate more harmful data, one can understand their inherent and diverse vulnerabilities to attacks. With these exposures, we then "unlearn" these issues, reducing the impact of affirmative tokens and hence minimizing jailbreak risks while keeping the model's responses to safe queries intact. We conduct extensive experiments on two models, four benchmark datasets, and multiple state-of-the-art jailbreak benchmarks to demonstrate the efficacy of our approach. Results indicate that our framework reduces the harmfulness and attack success rate of jailbreak attacks without compromising utility for benign queries compared to recent defense methods.
The Efficiency vs. Accuracy Trade-off: Optimizing RAG-Enhanced LLM Recommender Systems Using Multi-Head Early Exit
Jan 04, 2025



The deployment of Large Language Models (LLMs) in recommender systems for predicting Click-Through Rates (CTR) necessitates a delicate balance between computational efficiency and predictive accuracy. This paper presents an optimization framework that combines Retrieval-Augmented Generation (RAG) with an innovative multi-head early exit architecture to concurrently enhance both aspects. By integrating Graph Convolutional Networks (GCNs) as efficient retrieval mechanisms, we are able to significantly reduce data retrieval times while maintaining high model performance. The early exit strategy employed allows for dynamic termination of model inference, utilizing real-time predictive confidence assessments across multiple heads. This not only quickens the responsiveness of LLMs but also upholds or improves their accuracy, making it ideal for real-time application scenarios. Our experiments demonstrate how this architecture effectively decreases computation time without sacrificing the accuracy needed for reliable recommendation delivery, establishing a new standard for efficient, real-time LLM deployment in commercial systems.
Integrating Social Determinants of Health into Knowledge Graphs: Evaluating Prediction Bias and Fairness in Healthcare
Nov 29, 2024



Social determinants of health (SDoH) play a crucial role in patient health outcomes, yet their integration into biomedical knowledge graphs remains underexplored. This study addresses this gap by constructing an SDoH-enriched knowledge graph using the MIMIC-III dataset and PrimeKG. We introduce a novel fairness formulation for graph embeddings, focusing on invariance with respect to sensitive SDoH information. Via employing a heterogeneous-GCN model for drug-disease link prediction, we detect biases related to various SDoH factors. To mitigate these biases, we propose a post-processing method that strategically reweights edges connected to SDoHs, balancing their influence on graph representations. This approach represents one of the first comprehensive investigations into fairness issues within biomedical knowledge graphs incorporating SDoH. Our work not only highlights the importance of considering SDoH in medical informatics but also provides a concrete method for reducing SDoH-related biases in link prediction tasks, paving the way for more equitable healthcare recommendations. Our code is available at \url{https://github.com/hwq0726/SDoH-KG}.
Exploring the Alignment Landscape: LLMs and Geometric Deep Models in Protein Representation
Nov 08, 2024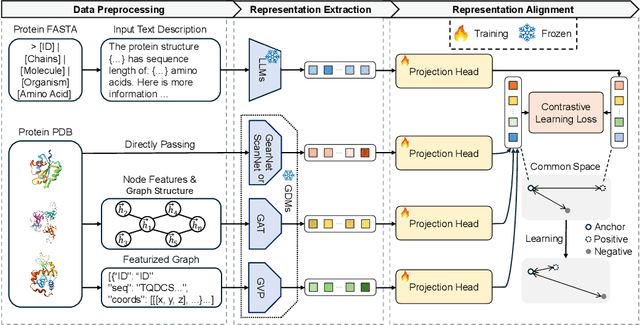

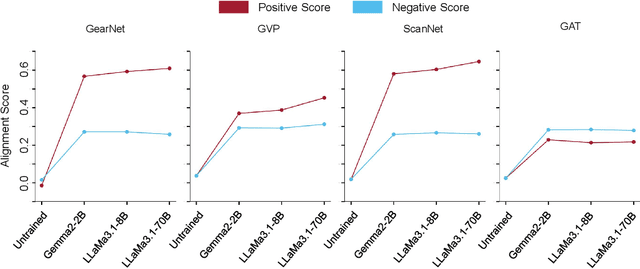

Latent representation alignment has become a foundational technique for constructing multimodal large language models (MLLM) by mapping embeddings from different modalities into a shared space, often aligned with the embedding space of large language models (LLMs) to enable effective cross-modal understanding. While preliminary protein-focused MLLMs have emerged, they have predominantly relied on heuristic approaches, lacking a fundamental understanding of optimal alignment practices across representations. In this study, we explore the alignment of multimodal representations between LLMs and Geometric Deep Models (GDMs) in the protein domain. We comprehensively evaluate three state-of-the-art LLMs (Gemma2-2B, LLaMa3.1-8B, and LLaMa3.1-70B) with four protein-specialized GDMs (GearNet, GVP, ScanNet, GAT). Our work examines alignment factors from both model and protein perspectives, identifying challenges in current alignment methodologies and proposing strategies to improve the alignment process. Our key findings reveal that GDMs incorporating both graph and 3D structural information align better with LLMs, larger LLMs demonstrate improved alignment capabilities, and protein rarity significantly impacts alignment performance. We also find that increasing GDM embedding dimensions, using two-layer projection heads, and fine-tuning LLMs on protein-specific data substantially enhance alignment quality. These strategies offer potential enhancements to the performance of protein-related multimodal models. Our code and data are available at https://github.com/Tizzzzy/LLM-GDM-alignment.
Gradient Rewiring for Editable Graph Neural Network Training
Oct 21, 2024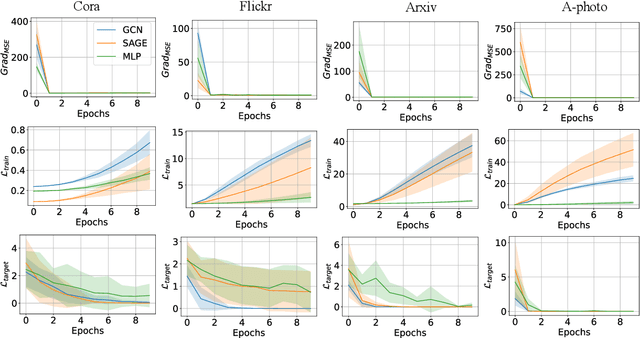
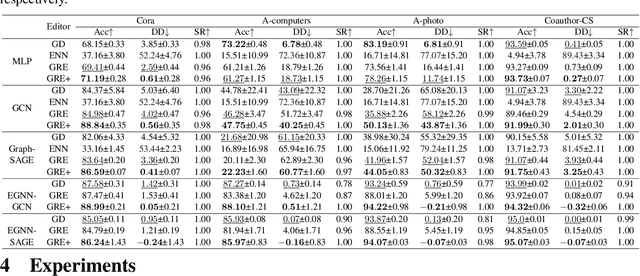
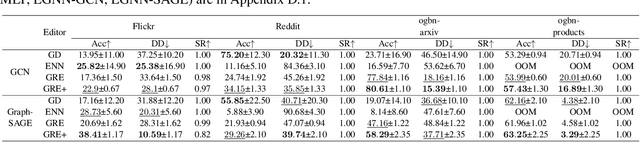
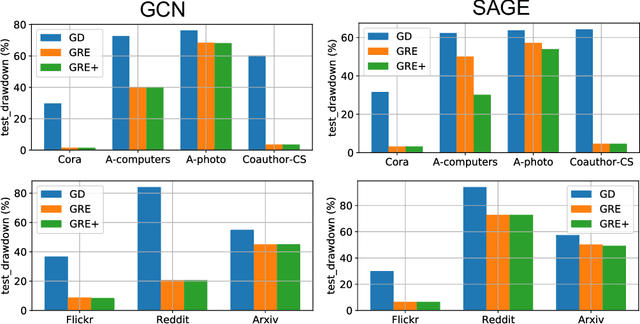
Deep neural networks are ubiquitously adopted in many applications, such as computer vision, natural language processing, and graph analytics. However, well-trained neural networks can make prediction errors after deployment as the world changes. \textit{Model editing} involves updating the base model to correct prediction errors with less accessible training data and computational resources. Despite recent advances in model editors in computer vision and natural language processing, editable training in graph neural networks (GNNs) is rarely explored. The challenge with editable GNN training lies in the inherent information aggregation across neighbors, which can lead model editors to affect the predictions of other nodes unintentionally. In this paper, we first observe the gradient of cross-entropy loss for the target node and training nodes with significant inconsistency, which indicates that directly fine-tuning the base model using the loss on the target node deteriorates the performance on training nodes. Motivated by the gradient inconsistency observation, we propose a simple yet effective \underline{G}radient \underline{R}ewiring method for \underline{E}ditable graph neural network training, named \textbf{GRE}. Specifically, we first store the anchor gradient of the loss on training nodes to preserve the locality. Subsequently, we rewire the gradient of the loss on the target node to preserve performance on the training node using anchor gradient. Experiments demonstrate the effectiveness of GRE on various model architectures and graph datasets in terms of multiple editing situations. The source code is available at \url{https://github.com/zhimengj0326/Gradient_rewiring_editing}