 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWordCraft: Scaffolding the Keyword Method for L2 Vocabulary Learning with Multimodal LLMs
Jan 31, 2026Applying the keyword method for vocabulary memorization remains a significant challenge for L1 Chinese-L2 English learners. They frequently struggle to generate phonologically appropriate keywords, construct coherent associations, and create vivid mental imagery to aid long-term retention. Existing approaches, including fully automated keyword generation and outcome-oriented mnemonic aids, either compromise learner engagement or lack adequate process-oriented guidance. To address these limitations, we conducted a formative study with L1 Chinese-L2 English learners and educators (N=18), which revealed key difficulties and requirements in applying the keyword method to vocabulary learning. Building on these insights, we introduce WordCraft, a learner-centered interactive tool powered by Multimodal Large Language Models (MLLMs). WordCraft scaffolds the keyword method by guiding learners through keyword selection, association construction, and image formation, thereby enhancing the effectiveness of vocabulary memorization. Two user studies demonstrate that WordCraft not only preserves the generation effect but also achieves high levels of effectiveness and usability.
Plan Then Action:High-Level Planning Guidance Reinforcement Learning for LLM Reasoning
Oct 02, 2025Large language models (LLMs) have demonstrated remarkable reasoning abilities in complex tasks, often relying on Chain-of-Thought (CoT) reasoning. However, due to their autoregressive token-level generation, the reasoning process is largely constrained to local decision-making and lacks global planning. This limitation frequently results in redundant, incoherent, or inaccurate reasoning, which significantly degrades overall performance. Existing approaches, such as tree-based algorithms and reinforcement learning (RL), attempt to address this issue but suffer from high computational costs and often fail to produce optimal reasoning trajectories. To tackle this challenge, we propose Plan-Then-Action Enhanced Reasoning with Group Relative Policy Optimization PTA-GRPO, a two-stage framework designed to improve both high-level planning and fine-grained CoT reasoning. In the first stage, we leverage advanced LLMs to distill CoT into compact high-level guidance, which is then used for supervised fine-tuning (SFT). In the second stage, we introduce a guidance-aware RL method that jointly optimizes the final output and the quality of high-level guidance, thereby enhancing reasoning effectiveness. We conduct extensive experiments on multiple mathematical reasoning benchmarks, including MATH, AIME2024, AIME2025, and AMC, across diverse base models such as Qwen2.5-7B-Instruct, Qwen3-8B, Qwen3-14B, and LLaMA3.2-3B. Experimental results demonstrate that PTA-GRPO consistently achieves stable and significant improvements across different models and tasks, validating its effectiveness and generalization.
Layer-Level Self-Exposure and Patch: Affirmative Token Mitigation for Jailbreak Attack Defense
Jan 05, 2025As large language models (LLMs) are increasingly deployed in diverse applications, including chatbot assistants and code generation, aligning their behavior with safety and ethical standards has become paramount. However, jailbreak attacks, which exploit vulnerabilities to elicit unintended or harmful outputs, threaten LLMs' safety significantly. In this paper, we introduce Layer-AdvPatcher, a novel methodology designed to defend against jailbreak attacks by utilizing an unlearning strategy to patch specific layers within LLMs through self-augmented datasets. Our insight is that certain layer(s), tend to produce affirmative tokens when faced with harmful prompts. By identifying these layers and adversarially exposing them to generate more harmful data, one can understand their inherent and diverse vulnerabilities to attacks. With these exposures, we then "unlearn" these issues, reducing the impact of affirmative tokens and hence minimizing jailbreak risks while keeping the model's responses to safe queries intact. We conduct extensive experiments on two models, four benchmark datasets, and multiple state-of-the-art jailbreak benchmarks to demonstrate the efficacy of our approach. Results indicate that our framework reduces the harmfulness and attack success rate of jailbreak attacks without compromising utility for benign queries compared to recent defense methods.
Min-K%++: Improved Baseline for Detecting Pre-Training Data from Large Language Models
Apr 03, 2024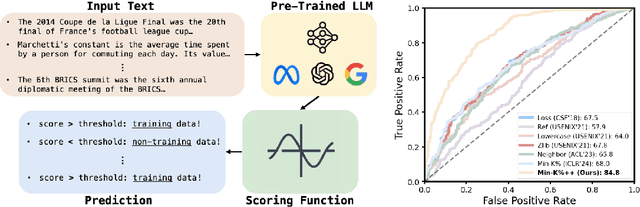
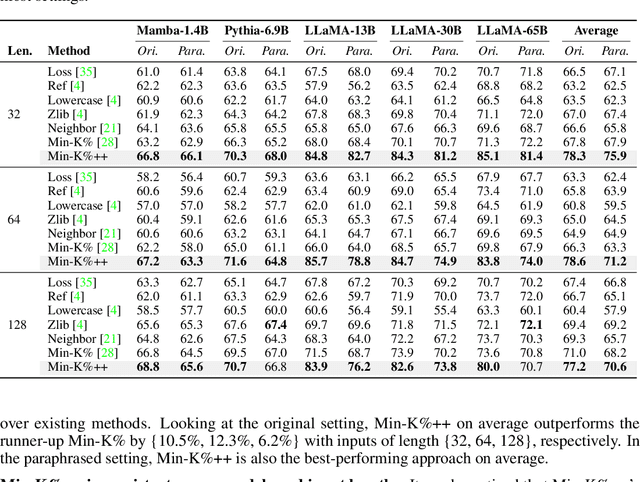
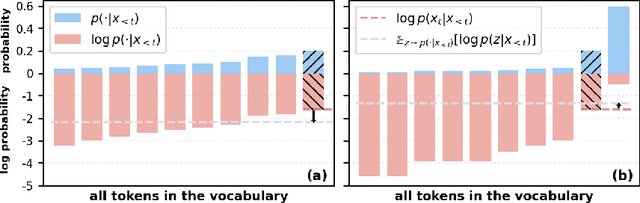
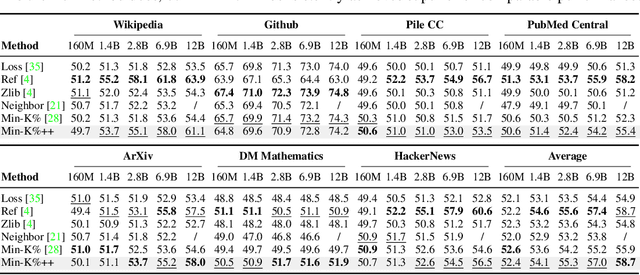
The problem of pre-training data detection for large language models (LLMs) has received growing attention due to its implications in critical issues like copyright violation and test data contamination. The current state-of-the-art approach, Min-K%, measures the raw token probability which we argue may not be the most informative signal. Instead, we propose Min-K%++ to normalize the token probability with statistics of the categorical distribution over the whole vocabulary, which accurately reflects the relative likelihood of the target token compared with other candidate tokens in the vocabulary. Theoretically, we back up our method by showing that the statistic it estimates is explicitly optimized during LLM training, thus serving as a reliable indicator for detecting training data. Empirically, on the WikiMIA benchmark, Min-K%++ outperforms the SOTA Min-K% by 6.2% to 10.5% in detection AUROC averaged over five models. On the more challenging MIMIR benchmark, Min-K%++ consistently improves upon Min-K% and performs on par with reference-based method, despite not requiring an extra reference model.
Towards Better Modeling with Missing Data: A Contrastive Learning-based Visual Analytics Perspective
Sep 18, 2023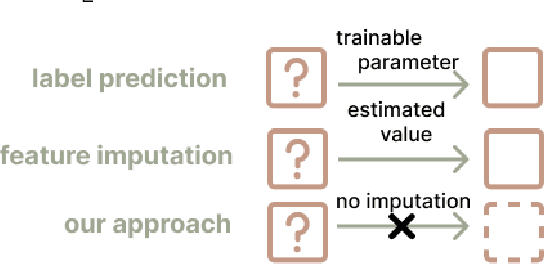
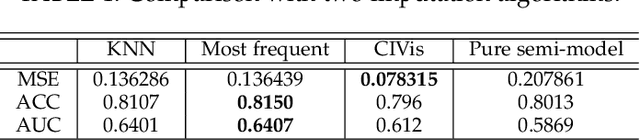
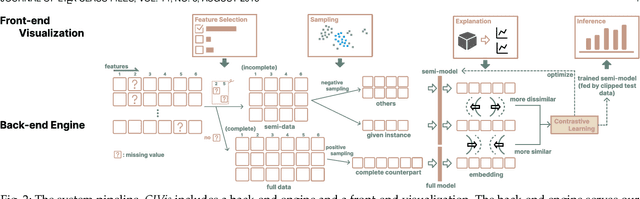
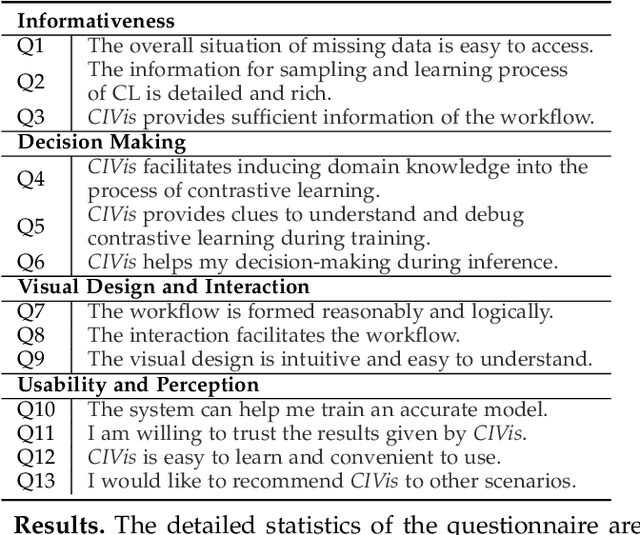
Missing data can pose a challenge for machine learning (ML) modeling. To address this, current approaches are categorized into feature imputation and label prediction and are primarily focused on handling missing data to enhance ML performance. These approaches rely on the observed data to estimate the missing values and therefore encounter three main shortcomings in imputation, including the need for different imputation methods for various missing data mechanisms, heavy dependence on the assumption of data distribution, and potential introduction of bias. This study proposes a Contrastive Learning (CL) framework to model observed data with missing values, where the ML model learns the similarity between an incomplete sample and its complete counterpart and the dissimilarity between other samples. Our proposed approach demonstrates the advantages of CL without requiring any imputation. To enhance interpretability, we introduce CIVis, a visual analytics system that incorporates interpretable techniques to visualize the learning process and diagnose the model status. Users can leverage their domain knowledge through interactive sampling to identify negative and positive pairs in CL. The output of CIVis is an optimized model that takes specified features and predicts downstream tasks. We provide two usage scenarios in regression and classification tasks and conduct quantitative experiments, expert interviews, and a qualitative user study to demonstrate the effectiveness of our approach. In short, this study offers a valuable contribution to addressing the challenges associated with ML modeling in the presence of missing data by providing a practical solution that achieves high predictive accuracy and model interpretability.