 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin-K%++: Improved Baseline for Detecting Pre-Training Data from Large Language Models
Paper and Code
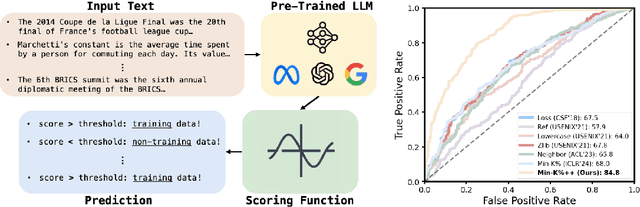
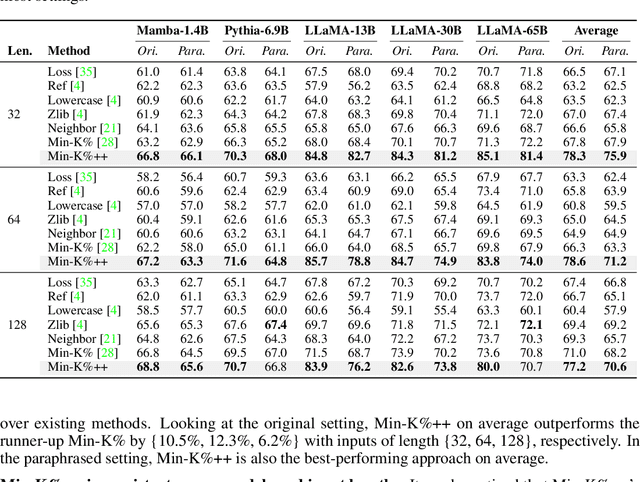
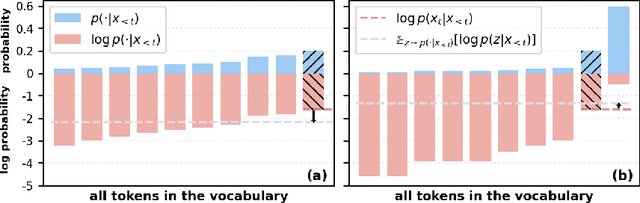
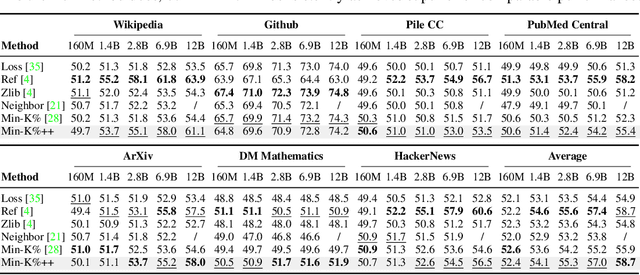
The problem of pre-training data detection for large language models (LLMs) has received growing attention due to its implications in critical issues like copyright violation and test data contamination. The current state-of-the-art approach, Min-K%, measures the raw token probability which we argue may not be the most informative signal. Instead, we propose Min-K%++ to normalize the token probability with statistics of the categorical distribution over the whole vocabulary, which accurately reflects the relative likelihood of the target token compared with other candidate tokens in the vocabulary. Theoretically, we back up our method by showing that the statistic it estimates is explicitly optimized during LLM training, thus serving as a reliable indicator for detecting training data. Empirically, on the WikiMIA benchmark, Min-K%++ outperforms the SOTA Min-K% by 6.2% to 10.5% in detection AUROC averaged over five models. On the more challenging MIMIR benchmark, Min-K%++ consistently improves upon Min-K% and performs on par with reference-based method, despite not requiring an extra reference model.