 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Maximization in Temporal Social Networks with a Cold-Start Problem: A Supervised Approach
Apr 15, 2025Influence Maximization (IM) in temporal graphs focuses on identifying influential "seeds" that are pivotal for maximizing network expansion. We advocate defining these seeds through Influence Propagation Paths (IPPs), which is essential for scaling up the network. Our focus lies in efficiently labeling IPPs and accurately predicting these seeds, while addressing the often-overlooked cold-start issue prevalent in temporal networks. Our strategy introduces a motif-based labeling method and a tensorized Temporal Graph Network (TGN) tailored for multi-relational temporal graphs, bolstering prediction accuracy and computational efficiency. Moreover, we augment cold-start nodes with new neighbors from historical data sharing similar IPPs. The recommendation system within an online team-based gaming environment presents subtle impact on the social network, forming multi-relational (i.e., weak and strong) temporal graphs for our empirical IM study. We conduct offline experiments to assess prediction accuracy and model training efficiency, complemented by online A/B testing to validate practical network growth and the effectiveness in addressing the cold-start issue.
Towards Better Modeling with Missing Data: A Contrastive Learning-based Visual Analytics Perspective
Sep 18, 2023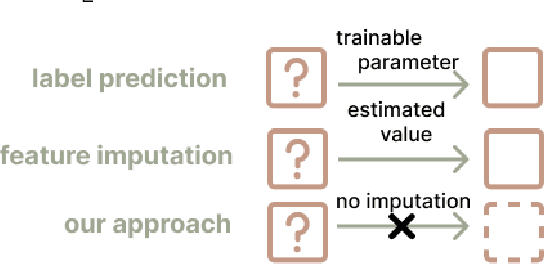
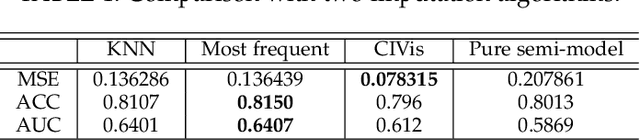
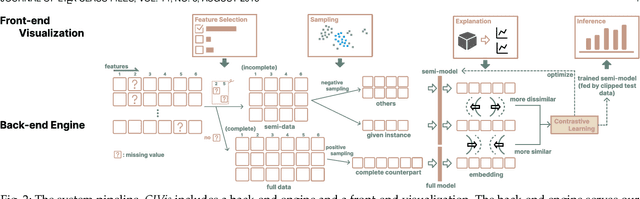
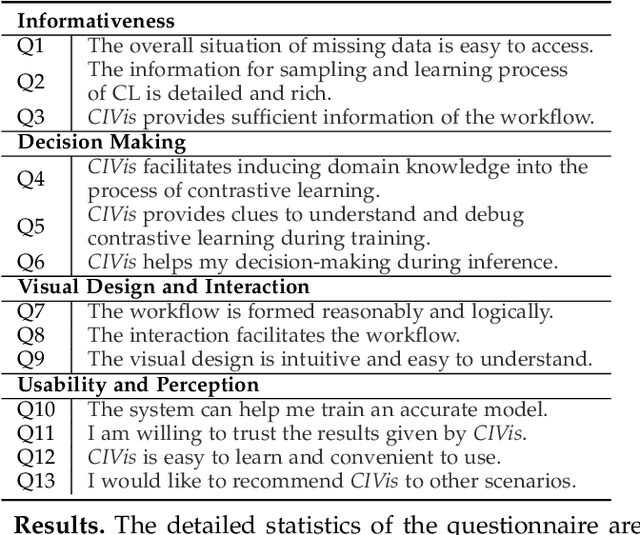
Missing data can pose a challenge for machine learning (ML) modeling. To address this, current approaches are categorized into feature imputation and label prediction and are primarily focused on handling missing data to enhance ML performance. These approaches rely on the observed data to estimate the missing values and therefore encounter three main shortcomings in imputation, including the need for different imputation methods for various missing data mechanisms, heavy dependence on the assumption of data distribution, and potential introduction of bias. This study proposes a Contrastive Learning (CL) framework to model observed data with missing values, where the ML model learns the similarity between an incomplete sample and its complete counterpart and the dissimilarity between other samples. Our proposed approach demonstrates the advantages of CL without requiring any imputation. To enhance interpretability, we introduce CIVis, a visual analytics system that incorporates interpretable techniques to visualize the learning process and diagnose the model status. Users can leverage their domain knowledge through interactive sampling to identify negative and positive pairs in CL. The output of CIVis is an optimized model that takes specified features and predicts downstream tasks. We provide two usage scenarios in regression and classification tasks and conduct quantitative experiments, expert interviews, and a qualitative user study to demonstrate the effectiveness of our approach. In short, this study offers a valuable contribution to addressing the challenges associated with ML modeling in the presence of missing data by providing a practical solution that achieves high predictive accuracy and model interpretability.