 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiF-DTA: Hierarchical Feature Learning Network for Drug-Target Affinity Prediction
Oct 31, 2025Accurate prediction of Drug-Target Affinity (DTA) is crucial for reducing experimental costs and accelerating early screening in computational drug discovery. While sequence-based deep learning methods avoid reliance on costly 3D structures, they still overlook simultaneous modeling of global sequence semantic features and local topological structural features within drugs and proteins, and represent drugs as flat sequences without atomic-level, substructural-level, and molecular-level multi-scale features. We propose HiF-DTA, a hierarchical network that adopts a dual-pathway strategy to extract both global sequence semantic and local topological features from drug and protein sequences, and models drugs multi-scale to learn atomic, substructural, and molecular representations fused via a multi-scale bilinear attention module. Experiments on Davis, KIBA, and Metz datasets show HiF-DTA outperforms state-of-the-art baselines, with ablations confirming the importance of global-local extraction and multi-scale fusion.
Towards Real-World Deepfake Detection: A Diverse In-the-wild Dataset of Forgery Faces
Oct 09, 2025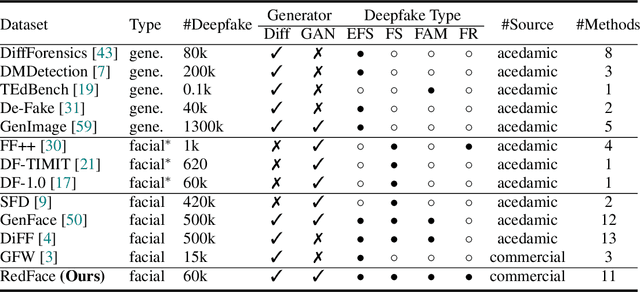


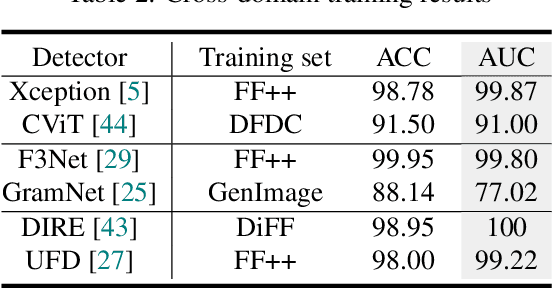
Deepfakes, leveraging advanced AIGC (Artificial Intelligence-Generated Content) techniques, create hyper-realistic synthetic images and videos of human faces, posing a significant threat to the authenticity of social media. While this real-world threat is increasingly prevalent, existing academic evaluations and benchmarks for detecting deepfake forgery often fall short to achieve effective application for their lack of specificity, limited deepfake diversity, restricted manipulation techniques.To address these limitations, we introduce RedFace (Real-world-oriented Deepfake Face), a specialized facial deepfake dataset, comprising over 60,000 forged images and 1,000 manipulated videos derived from authentic facial features, to bridge the gap between academic evaluations and real-world necessity. Unlike prior benchmarks, which typically rely on academic methods to generate deepfakes, RedFace utilizes 9 commercial online platforms to integrate the latest deepfake technologies found "in the wild", effectively simulating real-world black-box scenarios.Moreover, RedFace's deepfakes are synthesized using bespoke algorithms, allowing it to capture diverse and evolving methods used by real-world deepfake creators. Extensive experimental results on RedFace (including cross-domain, intra-domain, and real-world social network dissemination simulations) verify the limited practicality of existing deepfake detection schemes against real-world applications. We further perform a detailed analysis of the RedFace dataset, elucidating the reason of its impact on detection performance compared to conventional datasets. Our dataset is available at: https://github.com/kikyou-220/RedFace.
Transferable Direct Prompt Injection via Activation-Guided MCMC Sampling
Sep 09, 2025Direct Prompt Injection (DPI) attacks pose a critical security threat to Large Language Models (LLMs) due to their low barrier of execution and high potential damage. To address the impracticality of existing white-box/gray-box methods and the poor transferability of black-box methods, we propose an activations-guided prompt injection attack framework. We first construct an Energy-based Model (EBM) using activations from a surrogate model to evaluate the quality of adversarial prompts. Guided by the trained EBM, we employ the token-level Markov Chain Monte Carlo (MCMC) sampling to adaptively optimize adversarial prompts, thereby enabling gradient-free black-box attacks. Experimental results demonstrate our superior cross-model transferability, achieving 49.6% attack success rate (ASR) across five mainstream LLMs and 34.6% improvement over human-crafted prompts, and maintaining 36.6% ASR on unseen task scenarios. Interpretability analysis reveals a correlation between activations and attack effectiveness, highlighting the critical role of semantic patterns in transferable vulnerability exploitation.
Influence Maximization in Temporal Social Networks with a Cold-Start Problem: A Supervised Approach
Apr 15, 2025Influence Maximization (IM) in temporal graphs focuses on identifying influential "seeds" that are pivotal for maximizing network expansion. We advocate defining these seeds through Influence Propagation Paths (IPPs), which is essential for scaling up the network. Our focus lies in efficiently labeling IPPs and accurately predicting these seeds, while addressing the often-overlooked cold-start issue prevalent in temporal networks. Our strategy introduces a motif-based labeling method and a tensorized Temporal Graph Network (TGN) tailored for multi-relational temporal graphs, bolstering prediction accuracy and computational efficiency. Moreover, we augment cold-start nodes with new neighbors from historical data sharing similar IPPs. The recommendation system within an online team-based gaming environment presents subtle impact on the social network, forming multi-relational (i.e., weak and strong) temporal graphs for our empirical IM study. We conduct offline experiments to assess prediction accuracy and model training efficiency, complemented by online A/B testing to validate practical network growth and the effectiveness in addressing the cold-start issue.
ViDTA: Enhanced Drug-Target Affinity Prediction via Virtual Graph Nodes and Attention-based Feature Fusion
Dec 27, 2024



Drug-target interaction is fundamental in understanding how drugs affect biological systems, and accurately predicting drug-target affinity (DTA) is vital for drug discovery. Recently, deep learning methods have emerged as a significant approach for estimating the binding strength between drugs and target proteins. However, existing methods simply utilize the drug's local information from molecular topology rather than global information. Additionally, the features of drugs and proteins are usually fused with a simple concatenation operation, limiting their effectiveness. To address these challenges, we proposed ViDTA, an enhanced DTA prediction framework. We introduce virtual nodes into the Graph Neural Network (GNN)-based drug feature extraction network, which acts as a global memory to exchange messages more efficiently. By incorporating virtual graph nodes, we seamlessly integrate local and global features of drug molecular structures, expanding the GNN's receptive field. Additionally, we propose an attention-based linear feature fusion network for better capturing the interaction information between drugs and proteins. Experimental results evaluated on various benchmarks including Davis, Metz, and KIBA demonstrate that our proposed ViDTA outperforms the state-of-the-art baselines.
NumbOD: A Spatial-Frequency Fusion Attack Against Object Detectors
Dec 22, 2024With the advancement of deep learning, object detectors (ODs) with various architectures have achieved significant success in complex scenarios like autonomous driving. Previous adversarial attacks against ODs have been focused on designing customized attacks targeting their specific structures (e.g., NMS and RPN), yielding some results but simultaneously constraining their scalability. Moreover, most efforts against ODs stem from image-level attacks originally designed for classification tasks, resulting in redundant computations and disturbances in object-irrelevant areas (e.g., background). Consequently, how to design a model-agnostic efficient attack to comprehensively evaluate the vulnerabilities of ODs remains challenging and unresolved. In this paper, we propose NumbOD, a brand-new spatial-frequency fusion attack against various ODs, aimed at disrupting object detection within images. We directly leverage the features output by the OD without relying on its internal structures to craft adversarial examples. Specifically, we first design a dual-track attack target selection strategy to select high-quality bounding boxes from OD outputs for targeting. Subsequently, we employ directional perturbations to shift and compress predicted boxes and change classification results to deceive ODs. Additionally, we focus on manipulating the high-frequency components of images to confuse ODs' attention on critical objects, thereby enhancing the attack efficiency. Our extensive experiments on nine ODs and two datasets show that NumbOD achieves powerful attack performance and high stealthiness.
Breaking Barriers in Physical-World Adversarial Examples: Improving Robustness and Transferability via Robust Feature
Dec 22, 2024



As deep neural networks (DNNs) are widely applied in the physical world, many researches are focusing on physical-world adversarial examples (PAEs), which introduce perturbations to inputs and cause the model's incorrect outputs. However, existing PAEs face two challenges: unsatisfactory attack performance (i.e., poor transferability and insufficient robustness to environment conditions), and difficulty in balancing attack effectiveness with stealthiness, where better attack effectiveness often makes PAEs more perceptible. In this paper, we explore a novel perturbation-based method to overcome the challenges. For the first challenge, we introduce a strategy Deceptive RF injection based on robust features (RFs) that are predictive, robust to perturbations, and consistent across different models. Specifically, it improves the transferability and robustness of PAEs by covering RFs of other classes onto the predictive features in clean images. For the second challenge, we introduce another strategy Adversarial Semantic Pattern Minimization, which removes most perturbations and retains only essential adversarial patterns in AEsBased on the two strategies, we design our method Robust Feature Coverage Attack (RFCoA), comprising Robust Feature Disentanglement and Adversarial Feature Fusion. In the first stage, we extract target class RFs in feature space. In the second stage, we use attention-based feature fusion to overlay these RFs onto predictive features of clean images and remove unnecessary perturbations. Experiments show our method's superior transferability, robustness, and stealthiness compared to existing state-of-the-art methods. Additionally, our method's effectiveness can extend to Large Vision-Language Models (LVLMs), indicating its potential applicability to more complex tasks.
PB-UAP: Hybrid Universal Adversarial Attack For Image Segmentation
Dec 21, 2024



With the rapid advancement of deep learning, the model robustness has become a significant research hotspot, \ie, adversarial attacks on deep neural networks. Existing works primarily focus on image classification tasks, aiming to alter the model's predicted labels. Due to the output complexity and deeper network architectures, research on adversarial examples for segmentation models is still limited, particularly for universal adversarial perturbations. In this paper, we propose a novel universal adversarial attack method designed for segmentation models, which includes dual feature separation and low-frequency scattering modules. The two modules guide the training of adversarial examples in the pixel and frequency space, respectively. Experiments demonstrate that our method achieves high attack success rates surpassing the state-of-the-art methods, and exhibits strong transferability across different models.
TrojanRobot: Backdoor Attacks Against Robotic Manipulation in the Physical World
Nov 18, 2024Robotic manipulation refers to the autonomous handling and interaction of robots with objects using advanced techniques in robotics and artificial intelligence. The advent of powerful tools such as large language models (LLMs) and large vision-language models (LVLMs) has significantly enhanced the capabilities of these robots in environmental perception and decision-making. However, the introduction of these intelligent agents has led to security threats such as jailbreak attacks and adversarial attacks. In this research, we take a further step by proposing a backdoor attack specifically targeting robotic manipulation and, for the first time, implementing backdoor attack in the physical world. By embedding a backdoor visual language model into the visual perception module within the robotic system, we successfully mislead the robotic arm's operation in the physical world, given the presence of common items as triggers. Experimental evaluations in the physical world demonstrate the effectiveness of the proposed backdoor attack.
ECLIPSE: Expunging Clean-label Indiscriminate Poisons via Sparse Diffusion Purification
Jun 25, 2024
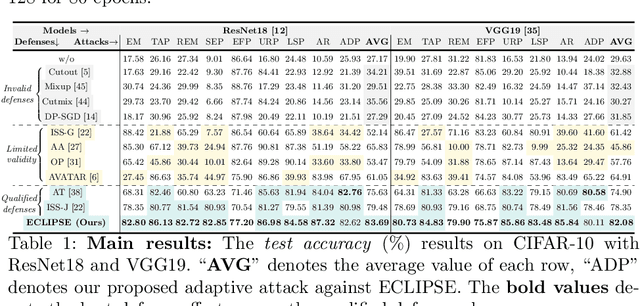
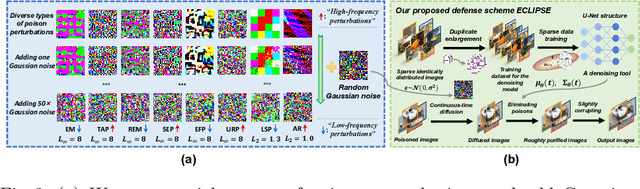
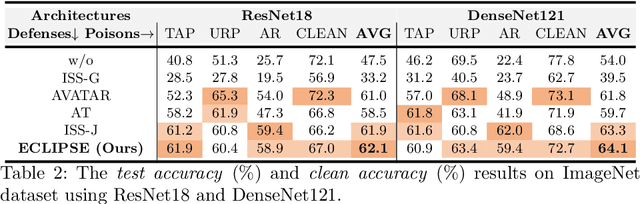
Clean-label indiscriminate poisoning attacks add invisible perturbations to correctly labeled training images, thus dramatically reducing the generalization capability of the victim models. Recently, some defense mechanisms have been proposed such as adversarial training, image transformation techniques, and image purification. However, these schemes are either susceptible to adaptive attacks, built on unrealistic assumptions, or only effective against specific poison types, limiting their universal applicability. In this research, we propose a more universally effective, practical, and robust defense scheme called ECLIPSE. We first investigate the impact of Gaussian noise on the poisons and theoretically prove that any kind of poison will be largely assimilated when imposing sufficient random noise. In light of this, we assume the victim has access to an extremely limited number of clean images (a more practical scene) and subsequently enlarge this sparse set for training a denoising probabilistic model (a universal denoising tool). We then begin by introducing Gaussian noise to absorb the poisons and then apply the model for denoising, resulting in a roughly purified dataset. Finally, to address the trade-off of the inconsistency in the assimilation sensitivity of different poisons by Gaussian noise, we propose a lightweight corruption compensation module to effectively eliminate residual poisons, providing a more universal defense approach. Extensive experiments demonstrate that our defense approach outperforms 10 state-of-the-art defenses. We also propose an adaptive attack against ECLIPSE and verify the robustness of our defense scheme. Our code is available at https://github.com/CGCL-codes/ECLIPSE.