 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurely Fine-tuning Pre-trained Encoders Against Adversarial Examples
Paper and Code
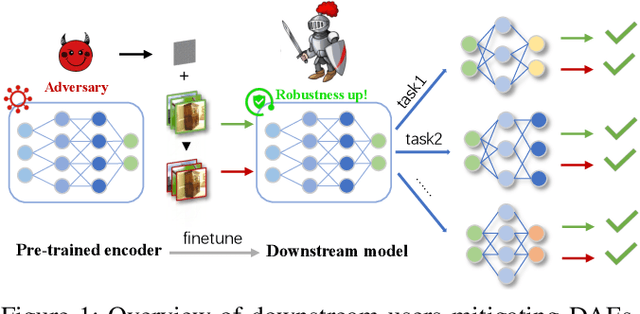
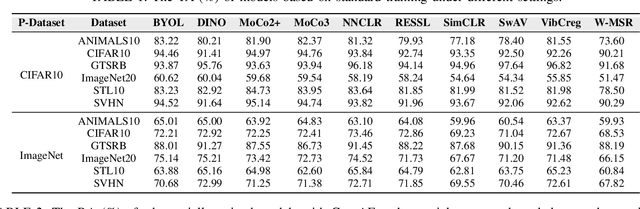
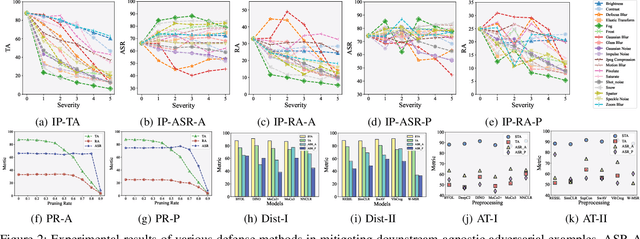

With the evolution of self-supervised learning, the pre-training paradigm has emerged as a predominant solution within the deep learning landscape. Model providers furnish pre-trained encoders designed to function as versatile feature extractors, enabling downstream users to harness the benefits of expansive models with minimal effort through fine-tuning. Nevertheless, recent works have exposed a vulnerability in pre-trained encoders, highlighting their susceptibility to downstream-agnostic adversarial examples (DAEs) meticulously crafted by attackers. The lingering question pertains to the feasibility of fortifying the robustness of downstream models against DAEs, particularly in scenarios where the pre-trained encoders are publicly accessible to the attackers. In this paper, we initially delve into existing defensive mechanisms against adversarial examples within the pre-training paradigm. Our findings reveal that the failure of current defenses stems from the domain shift between pre-training data and downstream tasks, as well as the sensitivity of encoder parameters. In response to these challenges, we propose Genetic Evolution-Nurtured Adversarial Fine-tuning (Gen-AF), a two-stage adversarial fine-tuning approach aimed at enhancing the robustness of downstream models. Our extensive experiments, conducted across ten self-supervised training methods and six datasets, demonstrate that Gen-AF attains high testing accuracy and robust testing accuracy against state-of-the-art DAEs.