 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Physical-World Adversarial Patches Against Object Detection in Autonomous Driving
Apr 25, 2026Deep learning drives major advances in autonomous driving (AD), where object detectors are central to perception. However, adversarial attacks pose significant threats to the reliability and safety of these systems, with physical adversarial patches representing a particularly potent form of attack. Physical adversarial patch attacks pose severe risks but are usually crafted for a single model, yielding poor transferability to unseen detectors. We propose AdvAD, a transfer-based physical attack against object detection in autonomous driving. Instead of targeting a specific detector, AdvAD optimizes adversarial patches over multiple detection models in a unified framework, encouraging the learned perturbations to capture shared vulnerabilities across architectures. The optimization process adaptively balances model contributions and enforces robustness to physical variations. It further employs data augmentation and geometric transformations to maintain patch effectiveness under diverse physical conditions. Experiments in both digital and real-world settings show that AdvAD consistently outperforms state-of-the-art (SOTA) attacks in performance and transferability.
UnlearnShield: Shielding Forgotten Privacy against Unlearning Inversion
Jan 28, 2026Machine unlearning is an emerging technique that aims to remove the influence of specific data from trained models, thereby enhancing privacy protection. However, recent research has uncovered critical privacy vulnerabilities, showing that adversaries can exploit unlearning inversion to reconstruct data that was intended to be erased. Despite the severity of this threat, dedicated defenses remain lacking. To address this gap, we propose UnlearnShield, the first defense specifically tailored to counter unlearning inversion. UnlearnShield introduces directional perturbations in the cosine representation space and regulates them through a constraint module to jointly preserve model accuracy and forgetting efficacy, thereby reducing inversion risk while maintaining utility. Experiments demonstrate that it achieves a good trade-off among privacy protection, accuracy, and forgetting.
Dual-View Inference Attack: Machine Unlearning Amplifies Privacy Exposure
Dec 18, 2025Machine unlearning is a newly popularized technique for removing specific training data from a trained model, enabling it to comply with data deletion requests. While it protects the rights of users requesting unlearning, it also introduces new privacy risks. Prior works have primarily focused on the privacy of data that has been unlearned, while the risks to retained data remain largely unexplored. To address this gap, we focus on the privacy risks of retained data and, for the first time, reveal the vulnerabilities introduced by machine unlearning under the dual-view setting, where an adversary can query both the original and the unlearned models. From an information-theoretic perspective, we introduce the concept of {privacy knowledge gain} and demonstrate that the dual-view setting allows adversaries to obtain more information than querying either model alone, thereby amplifying privacy leakage. To effectively demonstrate this threat, we propose DVIA, a Dual-View Inference Attack, which extracts membership information on retained data using black-box queries to both models. DVIA eliminates the need to train an attack model and employs a lightweight likelihood ratio inference module for efficient inference. Experiments across different datasets and model architectures validate the effectiveness of DVIA and highlight the privacy risks inherent in the dual-view setting.
UFVideo: Towards Unified Fine-Grained Video Cooperative Understanding with Large Language Models
Dec 12, 2025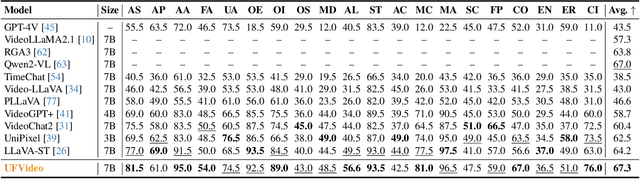
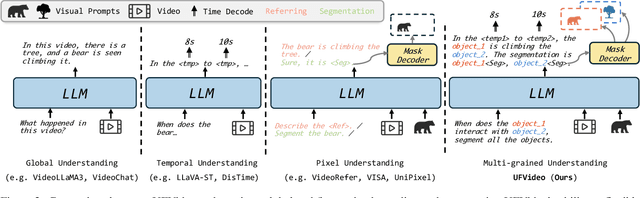
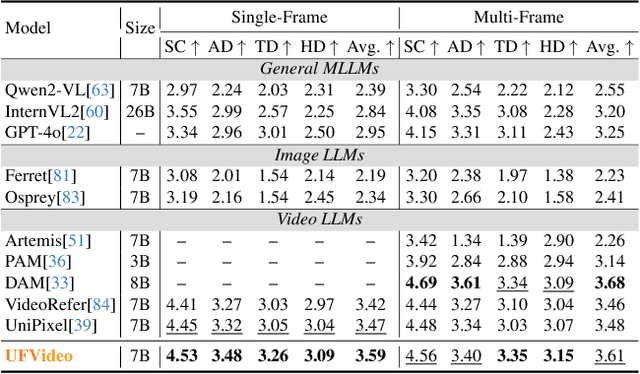
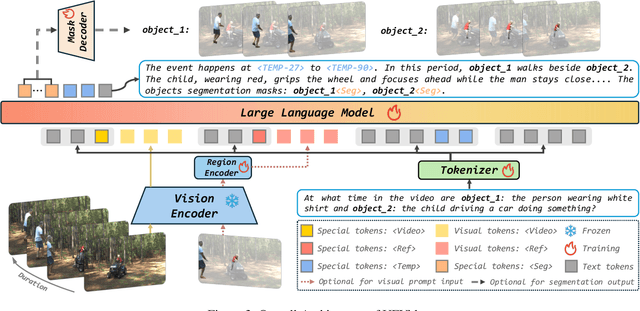
With the advancement of multi-modal Large Language Models (LLMs), Video LLMs have been further developed to perform on holistic and specialized video understanding. However, existing works are limited to specialized video understanding tasks, failing to achieve a comprehensive and multi-grained video perception. To bridge this gap, we introduce UFVideo, the first Video LLM with unified multi-grained cooperative understanding capabilities. Specifically, we design unified visual-language guided alignment to flexibly handle video understanding across global, pixel and temporal scales within a single model. UFVideo dynamically encodes the visual and text inputs of different tasks and generates the textual response, temporal localization, or grounded mask. Additionally, to evaluate challenging multi-grained video understanding tasks, we construct the UFVideo-Bench consisting of three distinct collaborative tasks within the scales, which demonstrates UFVideo's flexibility and advantages over GPT-4o. Furthermore, we validate the effectiveness of our model across 9 public benchmarks covering various common video understanding tasks, providing valuable insights for future Video LLMs.
Towards Reliable Forgetting: A Survey on Machine Unlearning Verification, Challenges, and Future Directions
Jun 18, 2025With growing demands for privacy protection, security, and legal compliance (e.g., GDPR), machine unlearning has emerged as a critical technique for ensuring the controllability and regulatory alignment of machine learning models. However, a fundamental challenge in this field lies in effectively verifying whether unlearning operations have been successfully and thoroughly executed. Despite a growing body of work on unlearning techniques, verification methodologies remain comparatively underexplored and often fragmented. Existing approaches lack a unified taxonomy and a systematic framework for evaluation. To bridge this gap, this paper presents the first structured survey of machine unlearning verification methods. We propose a taxonomy that organizes current techniques into two principal categories -- behavioral verification and parametric verification -- based on the type of evidence used to assess unlearning fidelity. We examine representative methods within each category, analyze their underlying assumptions, strengths, and limitations, and identify potential vulnerabilities in practical deployment. In closing, we articulate a set of open problems in current verification research, aiming to provide a foundation for developing more robust, efficient, and theoretically grounded unlearning verification mechanisms.
TrojanRobot: Backdoor Attacks Against Robotic Manipulation in the Physical World
Nov 18, 2024Robotic manipulation refers to the autonomous handling and interaction of robots with objects using advanced techniques in robotics and artificial intelligence. The advent of powerful tools such as large language models (LLMs) and large vision-language models (LVLMs) has significantly enhanced the capabilities of these robots in environmental perception and decision-making. However, the introduction of these intelligent agents has led to security threats such as jailbreak attacks and adversarial attacks. In this research, we take a further step by proposing a backdoor attack specifically targeting robotic manipulation and, for the first time, implementing backdoor attack in the physical world. By embedding a backdoor visual language model into the visual perception module within the robotic system, we successfully mislead the robotic arm's operation in the physical world, given the presence of common items as triggers. Experimental evaluations in the physical world demonstrate the effectiveness of the proposed backdoor attack.
Securely Fine-tuning Pre-trained Encoders Against Adversarial Examples
Mar 19, 2024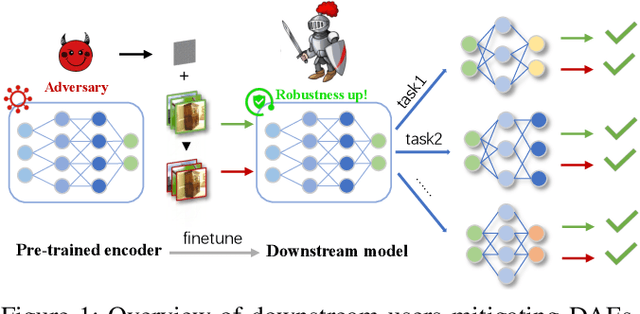
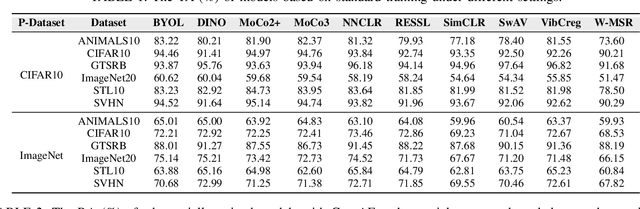
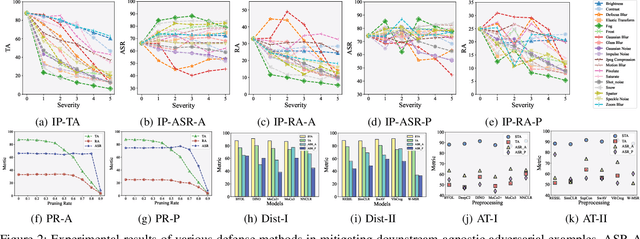

With the evolution of self-supervised learning, the pre-training paradigm has emerged as a predominant solution within the deep learning landscape. Model providers furnish pre-trained encoders designed to function as versatile feature extractors, enabling downstream users to harness the benefits of expansive models with minimal effort through fine-tuning. Nevertheless, recent works have exposed a vulnerability in pre-trained encoders, highlighting their susceptibility to downstream-agnostic adversarial examples (DAEs) meticulously crafted by attackers. The lingering question pertains to the feasibility of fortifying the robustness of downstream models against DAEs, particularly in scenarios where the pre-trained encoders are publicly accessible to the attackers. In this paper, we initially delve into existing defensive mechanisms against adversarial examples within the pre-training paradigm. Our findings reveal that the failure of current defenses stems from the domain shift between pre-training data and downstream tasks, as well as the sensitivity of encoder parameters. In response to these challenges, we propose Genetic Evolution-Nurtured Adversarial Fine-tuning (Gen-AF), a two-stage adversarial fine-tuning approach aimed at enhancing the robustness of downstream models. Our extensive experiments, conducted across ten self-supervised training methods and six datasets, demonstrate that Gen-AF attains high testing accuracy and robust testing accuracy against state-of-the-art DAEs.
Revisiting Gradient Pruning: A Dual Realization for Defending against Gradient Attacks
Jan 30, 2024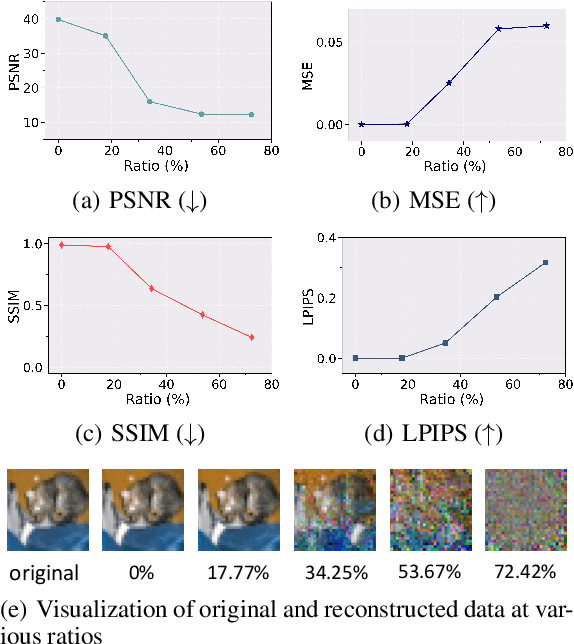
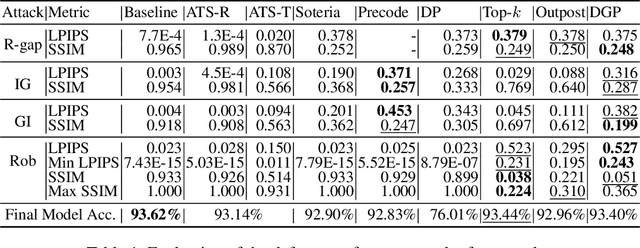
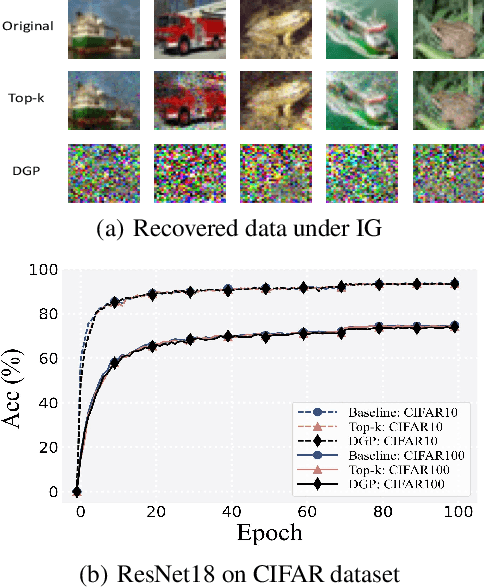
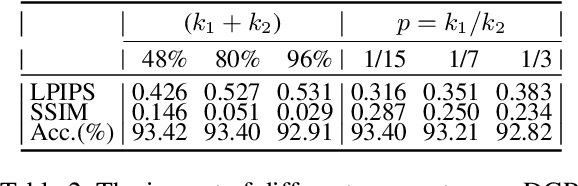
Collaborative learning (CL) is a distributed learning framework that aims to protect user privacy by allowing users to jointly train a model by sharing their gradient updates only. However, gradient inversion attacks (GIAs), which recover users' training data from shared gradients, impose severe privacy threats to CL. Existing defense methods adopt different techniques, e.g., differential privacy, cryptography, and perturbation defenses, to defend against the GIAs. Nevertheless, all current defense methods suffer from a poor trade-off between privacy, utility, and efficiency. To mitigate the weaknesses of existing solutions, we propose a novel defense method, Dual Gradient Pruning (DGP), based on gradient pruning, which can improve communication efficiency while preserving the utility and privacy of CL. Specifically, DGP slightly changes gradient pruning with a stronger privacy guarantee. And DGP can also significantly improve communication efficiency with a theoretical analysis of its convergence and generalization. Our extensive experiments show that DGP can effectively defend against the most powerful GIAs and reduce the communication cost without sacrificing the model's utility.
MISA: Unveiling the Vulnerabilities in Split Federated Learning
Dec 19, 2023\textit{Federated learning} (FL) and \textit{split learning} (SL) are prevailing distributed paradigms in recent years. They both enable shared global model training while keeping data localized on users' devices. The former excels in parallel execution capabilities, while the latter enjoys low dependence on edge computing resources and strong privacy protection. \textit{Split federated learning} (SFL) combines the strengths of both FL and SL, making it one of the most popular distributed architectures. Furthermore, a recent study has claimed that SFL exhibits robustness against poisoning attacks, with a fivefold improvement compared to FL in terms of robustness. In this paper, we present a novel poisoning attack known as MISA. It poisons both the top and bottom models, causing a \textbf{\underline{misa}}lignment in the global model, ultimately leading to a drastic accuracy collapse. This attack unveils the vulnerabilities in SFL, challenging the conventional belief that SFL is robust against poisoning attacks. Extensive experiments demonstrate that our proposed MISA poses a significant threat to the availability of SFL, underscoring the imperative for academia and industry to accord this matter due attention.