 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Gradient Pruning: A Dual Realization for Defending against Gradient Attacks
Jan 30, 2024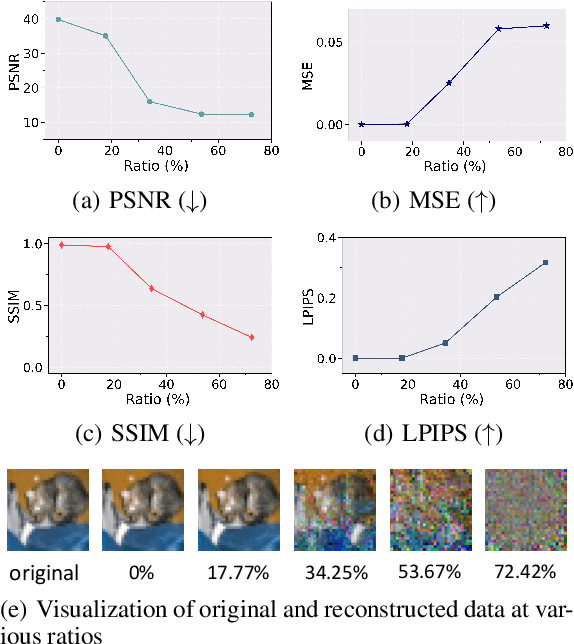
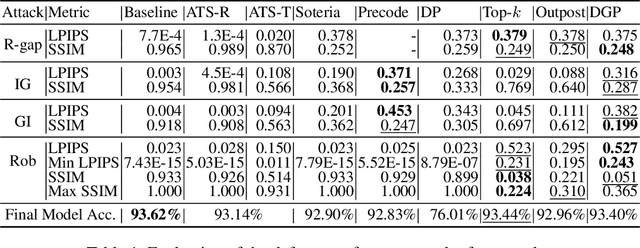
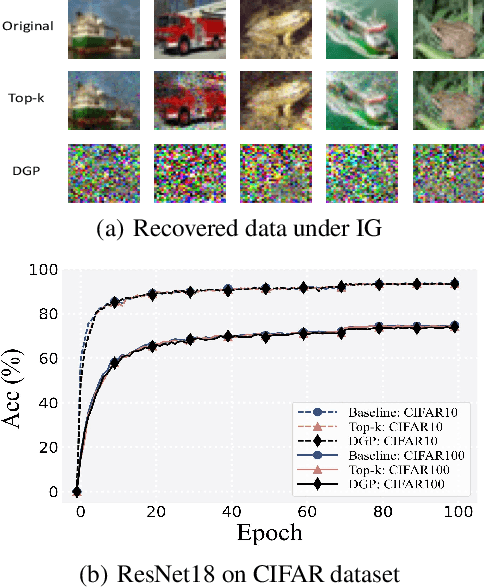
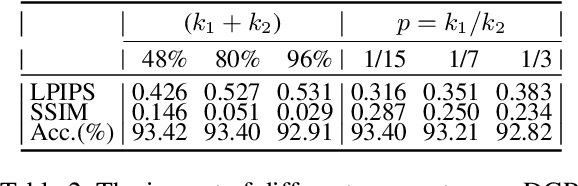
Collaborative learning (CL) is a distributed learning framework that aims to protect user privacy by allowing users to jointly train a model by sharing their gradient updates only. However, gradient inversion attacks (GIAs), which recover users' training data from shared gradients, impose severe privacy threats to CL. Existing defense methods adopt different techniques, e.g., differential privacy, cryptography, and perturbation defenses, to defend against the GIAs. Nevertheless, all current defense methods suffer from a poor trade-off between privacy, utility, and efficiency. To mitigate the weaknesses of existing solutions, we propose a novel defense method, Dual Gradient Pruning (DGP), based on gradient pruning, which can improve communication efficiency while preserving the utility and privacy of CL. Specifically, DGP slightly changes gradient pruning with a stronger privacy guarantee. And DGP can also significantly improve communication efficiency with a theoretical analysis of its convergence and generalization. Our extensive experiments show that DGP can effectively defend against the most powerful GIAs and reduce the communication cost without sacrificing the model's utility.
Downstream-agnostic Adversarial Examples
Aug 14, 2023Self-supervised learning usually uses a large amount of unlabeled data to pre-train an encoder which can be used as a general-purpose feature extractor, such that downstream users only need to perform fine-tuning operations to enjoy the benefit of "large model". Despite this promising prospect, the security of pre-trained encoder has not been thoroughly investigated yet, especially when the pre-trained encoder is publicly available for commercial use. In this paper, we propose AdvEncoder, the first framework for generating downstream-agnostic universal adversarial examples based on the pre-trained encoder. AdvEncoder aims to construct a universal adversarial perturbation or patch for a set of natural images that can fool all the downstream tasks inheriting the victim pre-trained encoder. Unlike traditional adversarial example works, the pre-trained encoder only outputs feature vectors rather than classification labels. Therefore, we first exploit the high frequency component information of the image to guide the generation of adversarial examples. Then we design a generative attack framework to construct adversarial perturbations/patches by learning the distribution of the attack surrogate dataset to improve their attack success rates and transferability. Our results show that an attacker can successfully attack downstream tasks without knowing either the pre-training dataset or the downstream dataset. We also tailor four defenses for pre-trained encoders, the results of which further prove the attack ability of AdvEncoder.