 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimestep-Aware SVDQuant-GPTQ for W4A4 Quantization of Wan2.2-I2V
May 26, 2026W4A4 quantization of large video diffusion Transformers offers substantial memory savings but is hindered by two main challenges: sparse large-magnitude activation outliers, and strongly timestep-dependent activation distributions across the multi-step denoising trajectory. These difficulties are compounded by Wan2.2-I2V's two-expert Mixture-of-Experts DiT design, whose high-noise and low-noise experts exhibit distinct quantization sensitivities that a single global calibration policy cannot capture. We propose a post-training quantization framework combining SVDQuant-based low-rank outlier compensation, GPTQ-based reconstruction-aware residual weight quantization, and timestep-bin-wise per-layer activation clipping-ratio search conducted independently for each expert. On the OpenS2V-Eval benchmark, our method reduces peak GPU memory by 59.3\% relative to the BF16 baseline while incurring only a 0.9\% drop in VBench average score and a 2.3\% drop in Imaging Quality, demonstrating that expert- and timestep-aware calibration is essential for high-fidelity W4A4 inference on MoE video DiTs.
Reconstructing Spiking Neural Networks Using a Single Neuron with Autapses
Mar 25, 2026Spiking neural networks (SNNs) are promising for neuromorphic computing, but high-performing models still rely on dense multilayer architectures with substantial communication and state-storage costs. Inspired by autapses, we propose time-delayed autapse SNN (TDA-SNN), a framework that reconstructs SNNs with a single leaky integrate-and-fire neuron and a prototype-learning-based training strategy. By reorganizing internal temporal states, TDA-SNN can realize reservoir, multilayer perceptron, and convolution-like spiking architectures within a unified framework. Experiments on sequential, event-based, and image benchmarks show competitive performance in reservoir and MLP settings, while convolutional results reveal a clear space--time trade-off. Compared with standard SNNs, TDA-SNN greatly reduces neuron count and state memory while increasing per-neuron information capacity, at the cost of additional temporal latency in extreme single-neuron settings. These findings highlight the potential of temporally multiplexed single-neuron models as compact computational units for brain-inspired computing.
SPECTRE: Spectral Pre-training Embeddings with Cylindrical Temporal Rotary Position Encoding for Fine-Grained sEMG-Based Movement Decoding
Dec 27, 2025Decoding fine-grained movement from non-invasive surface Electromyography (sEMG) is a challenge for prosthetic control due to signal non-stationarity and low signal-to-noise ratios. Generic self-supervised learning (SSL) frameworks often yield suboptimal results on sEMG as they attempt to reconstruct noisy raw signals and lack the inductive bias to model the cylindrical topology of electrode arrays. To overcome these limitations, we introduce SPECTRE, a domain-specific SSL framework. SPECTRE features two primary contributions: a physiologically-grounded pre-training task and a novel positional encoding. The pre-training involves masked prediction of discrete pseudo-labels from clustered Short-Time Fourier Transform (STFT) representations, compelling the model to learn robust, physiologically relevant frequency patterns. Additionally, our Cylindrical Rotary Position Embedding (CyRoPE) factorizes embeddings along linear temporal and annular spatial dimensions, explicitly modeling the forearm sensor topology to capture muscle synergies. Evaluations on multiple datasets, including challenging data from individuals with amputation, demonstrate that SPECTRE establishes a new state-of-the-art for movement decoding, significantly outperforming both supervised baselines and generic SSL approaches. Ablation studies validate the critical roles of both spectral pre-training and CyRoPE. SPECTRE provides a robust foundation for practical myoelectric interfaces capable of handling real-world sEMG complexities.
WAR-Re: Web API Recommendation with Semantic Reasoning
Nov 08, 2025With the development of cloud computing, the number of Web APIs has increased dramatically, further intensifying the demand for efficient Web API recommendation. Despite the demonstrated success of previous Web API recommendation solutions, two critical challenges persist: 1) a fixed top-N recommendation that cannot accommodate the varying API cardinality requirements of different mashups, and 2) these methods output only ranked API lists without accompanying reasons, depriving users of understanding the recommendation. To address these challenges, we propose WAR-Re, an LLM-based model for Web API recommendation with semantic reasoning for justification. WAR-Re leverages special start and stop tokens to handle the first challenge and uses two-stage training: supervised fine-tuning and reinforcement learning via Group Relative Policy Optimization (GRPO) to enhance the model's ability in both tasks. Comprehensive experimental evaluations on the ProgrammableWeb dataset demonstrate that WAR-Re achieves a gain of up to 21.59\% over the state-of-the-art baseline model in recommendation accuracy, while consistently producing high-quality semantic reasons for recommendations.
NSPDI-SNN: An efficient lightweight SNN based on nonlinear synaptic pruning and dendritic integration
Aug 29, 2025Spiking neural networks (SNNs) are artificial neural networks based on simulated biological neurons and have attracted much attention in recent artificial intelligence technology studies. The dendrites in biological neurons have efficient information processing ability and computational power; however, the neurons of SNNs rarely match the complex structure of the dendrites. Inspired by the nonlinear structure and highly sparse properties of neuronal dendrites, in this study, we propose an efficient, lightweight SNN method with nonlinear pruning and dendritic integration (NSPDI-SNN). In this method, we introduce nonlinear dendritic integration (NDI) to improve the representation of the spatiotemporal information of neurons. We implement heterogeneous state transition ratios of dendritic spines and construct a new and flexible nonlinear synaptic pruning (NSP) method to achieve the high sparsity of SNN. We conducted systematic experiments on three benchmark datasets (DVS128 Gesture, CIFAR10-DVS, and CIFAR10) and extended the evaluation to two complex tasks (speech recognition and reinforcement learning-based maze navigation task). Across all tasks, NSPDI-SNN consistently achieved high sparsity with minimal performance degradation. In particular, our method achieved the best experimental results on all three event stream datasets. Further analysis showed that NSPDI significantly improved the efficiency of synaptic information transfer as sparsity increased. In conclusion, our results indicate that the complex structure and nonlinear computation of neuronal dendrites provide a promising approach for developing efficient SNN methods.
ST-FlowNet: An Efficient Spiking Neural Network for Event-Based Optical Flow Estimation
Mar 13, 2025Spiking Neural Networks (SNNs) have emerged as a promising tool for event-based optical flow estimation tasks due to their ability to leverage spatio-temporal information and low-power capabilities. However, the performance of SNN models is often constrained, limiting their application in real-world scenarios. In this work, we address this gap by proposing a novel neural network architecture, ST-FlowNet, specifically tailored for optical flow estimation from event-based data. The ST-FlowNet architecture integrates ConvGRU modules to facilitate cross-modal feature augmentation and temporal alignment of the predicted optical flow, improving the network's ability to capture complex motion dynamics. Additionally, to overcome the challenges associated with training SNNs, we introduce a novel approach to derive SNN models from pre-trained artificial neural networks (ANNs) through ANN-to-SNN conversion or our proposed BISNN method. Notably, the BISNN method alleviates the complexities involved in biological parameter selection, further enhancing the robustness of SNNs in optical flow estimation tasks. Extensive evaluations on three benchmark event-based datasets demonstrate that the SNN-based ST-FlowNet model outperforms state-of-the-art methods, delivering superior performance in accurate optical flow estimation across a diverse range of dynamic visual scenes. Furthermore, the inherent energy efficiency of SNN models is highlighted, establishing a compelling advantage for their practical deployment. Overall, our work presents a novel framework for optical flow estimation using SNNs and event-based data, contributing to the advancement of neuromorphic vision applications.
FedMHO: Heterogeneous One-Shot Federated Learning Towards Resource-Constrained Edge Devices
Feb 12, 2025



Federated Learning (FL) is increasingly adopted in edge computing scenarios, where a large number of heterogeneous clients operate under constrained or sufficient resources. The iterative training process in conventional FL introduces significant computation and communication overhead, which is unfriendly for resource-constrained edge devices. One-shot FL has emerged as a promising approach to mitigate communication overhead, and model-heterogeneous FL solves the problem of diverse computing resources across clients. However, existing methods face challenges in effectively managing model-heterogeneous one-shot FL, often leading to unsatisfactory global model performance or reliance on auxiliary datasets. To address these challenges, we propose a novel FL framework named FedMHO, which leverages deep classification models on resource-sufficient clients and lightweight generative models on resource-constrained devices. On the server side, FedMHO involves a two-stage process that includes data generation and knowledge fusion. Furthermore, we introduce FedMHO-MD and FedMHO-SD to mitigate the knowledge-forgetting problem during the knowledge fusion stage, and an unsupervised data optimization solution to improve the quality of synthetic samples. Comprehensive experiments demonstrate the effectiveness of our methods, as they outperform state-of-the-art baselines in various experimental setups.
NumbOD: A Spatial-Frequency Fusion Attack Against Object Detectors
Dec 22, 2024With the advancement of deep learning, object detectors (ODs) with various architectures have achieved significant success in complex scenarios like autonomous driving. Previous adversarial attacks against ODs have been focused on designing customized attacks targeting their specific structures (e.g., NMS and RPN), yielding some results but simultaneously constraining their scalability. Moreover, most efforts against ODs stem from image-level attacks originally designed for classification tasks, resulting in redundant computations and disturbances in object-irrelevant areas (e.g., background). Consequently, how to design a model-agnostic efficient attack to comprehensively evaluate the vulnerabilities of ODs remains challenging and unresolved. In this paper, we propose NumbOD, a brand-new spatial-frequency fusion attack against various ODs, aimed at disrupting object detection within images. We directly leverage the features output by the OD without relying on its internal structures to craft adversarial examples. Specifically, we first design a dual-track attack target selection strategy to select high-quality bounding boxes from OD outputs for targeting. Subsequently, we employ directional perturbations to shift and compress predicted boxes and change classification results to deceive ODs. Additionally, we focus on manipulating the high-frequency components of images to confuse ODs' attention on critical objects, thereby enhancing the attack efficiency. Our extensive experiments on nine ODs and two datasets show that NumbOD achieves powerful attack performance and high stealthiness.
DarkSAM: Fooling Segment Anything Model to Segment Nothing
Sep 26, 2024

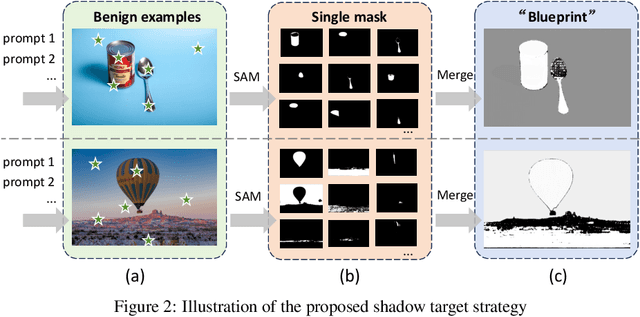
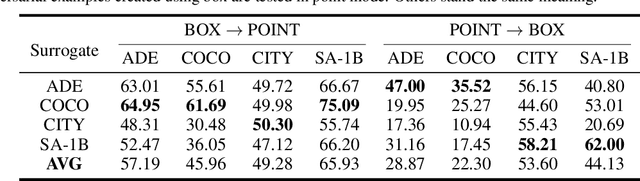
Segment Anything Model (SAM) has recently gained much attention for its outstanding generalization to unseen data and tasks. Despite its promising prospect, the vulnerabilities of SAM, especially to universal adversarial perturbation (UAP) have not been thoroughly investigated yet. In this paper, we propose DarkSAM, the first prompt-free universal attack framework against SAM, including a semantic decoupling-based spatial attack and a texture distortion-based frequency attack. We first divide the output of SAM into foreground and background. Then, we design a shadow target strategy to obtain the semantic blueprint of the image as the attack target. DarkSAM is dedicated to fooling SAM by extracting and destroying crucial object features from images in both spatial and frequency domains. In the spatial domain, we disrupt the semantics of both the foreground and background in the image to confuse SAM. In the frequency domain, we further enhance the attack effectiveness by distorting the high-frequency components (i.e., texture information) of the image. Consequently, with a single UAP, DarkSAM renders SAM incapable of segmenting objects across diverse images with varying prompts. Experimental results on four datasets for SAM and its two variant models demonstrate the powerful attack capability and transferability of DarkSAM.
Reliable Object Tracking by Multimodal Hybrid Feature Extraction and Transformer-Based Fusion
May 28, 2024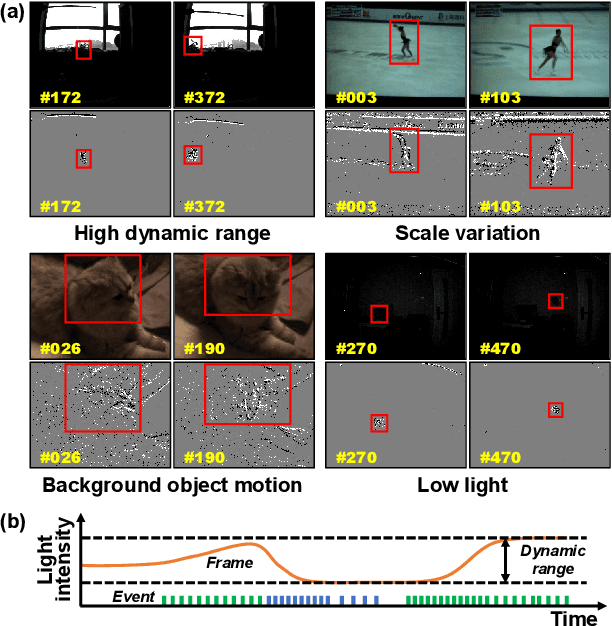

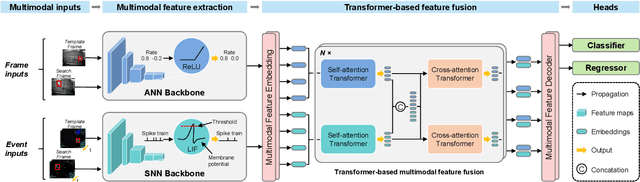
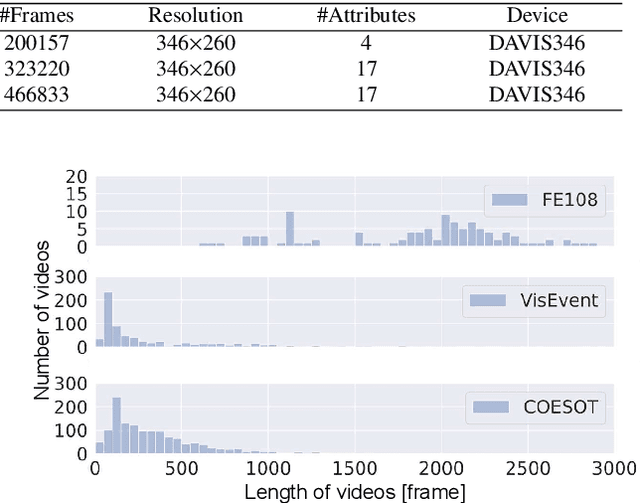
Visual object tracking, which is primarily based on visible light image sequences, encounters numerous challenges in complicated scenarios, such as low light conditions, high dynamic ranges, and background clutter. To address these challenges, incorporating the advantages of multiple visual modalities is a promising solution for achieving reliable object tracking. However, the existing approaches usually integrate multimodal inputs through adaptive local feature interactions, which cannot leverage the full potential of visual cues, thus resulting in insufficient feature modeling. In this study, we propose a novel multimodal hybrid tracker (MMHT) that utilizes frame-event-based data for reliable single object tracking. The MMHT model employs a hybrid backbone consisting of an artificial neural network (ANN) and a spiking neural network (SNN) to extract dominant features from different visual modalities and then uses a unified encoder to align the features across different domains. Moreover, we propose an enhanced transformer-based module to fuse multimodal features using attention mechanisms. With these methods, the MMHT model can effectively construct a multiscale and multidimensional visual feature space and achieve discriminative feature modeling. Extensive experiments demonstrate that the MMHT model exhibits competitive performance in comparison with that of other state-of-the-art methods. Overall, our results highlight the effectiveness of the MMHT model in terms of addressing the challenges faced in visual object tracking tasks.