 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentMeter: Evaluating Model-CLI Matching for CLI-Based Local Task-Solving Agents
Jun 19, 2026LLM agents increasingly solve local tasks through command-line and CLI-based harness interfaces, including code editing, repository inspection, data analysis, and file workflows. Existing evaluations often emphasize task success, but deployed local agents are not models alone: the CLI mediates prompts, context replay, tool outputs, file access, terminal observations, and stopping behavior. As a result, the same model can produce different success, token, and cost profiles under different CLIs. We introduce AGENTMETER, a benchmark for evaluating model-CLI matching in CLI-mediated local task-solving agents, together with AgentMeter Score (AMS), a success-anchored, cost-aware metric over calibrated task-effort tiers. AgentMeter uses Benchmark90 as the full validation set and Core30 as a lower-cost subset for expanded comparison across 24 complete model-CLI configurations. On Core30, common deployment criteria select different configurations: highest Pass/30 selects GLM-5.1 with qwen-coder, lowest Tok./Pass selects GPT-5.3-Codex with kimi-cli, lowest billable USD/Pass selects Qwen3.6+ with Codex, while highest AMS selects Qwen3.6+ with kimi-cli. Benchmark90 validation preserves the Top-1 configuration and Top-3 set, with Spearman correlation 0.765, Kendall correlation 0.567, and AMS MAE 0.0383. These results show that model choice and CLI choice should not be decoupled, and that model-CLI configurations should be evaluated as the deployed unit.
Revisiting Unknowns: Towards Effective and Efficient Open-Set Active Learning
Mar 09, 2026Open-set active learning (OSAL) aims to identify informative samples for annotation when unlabeled data may contain previously unseen classes-a common challenge in safety-critical and open-world scenarios. Existing approaches typically rely on separately trained open-set detectors, introducing substantial training overhead and overlooking the supervisory value of labeled unknowns for improving known-class learning. In this paper, we propose E$^2$OAL (Effective and Efficient Open-set Active Learning), a unified and detector-free framework that fully exploits labeled unknowns for both stronger supervision and more reliable querying. E$^2$OAL first uncovers the latent class structure of unknowns through label-guided clustering in a frozen contrastively pre-trained feature space, optimized by a structure-aware F1-product objective. To leverage labeled unknowns, it employs a Dirichlet-calibrated auxiliary head that jointly models known and unknown categories, improving both confidence calibration and known-class discrimination. Building on this, a logit-margin purity score estimates the likelihood of known classes to construct a high-purity candidate pool, while an OSAL-specific informativeness metric prioritizes partially ambiguous yet reliable samples. These components together form a flexible two-stage query strategy with adaptive precision control and minimal hyperparameter sensitivity. Extensive experiments across multiple OSAL benchmarks demonstrate that E$^2$OAL consistently surpasses state-of-the-art methods in accuracy, efficiency, and query precision, highlighting its effectiveness and practicality for real-world applications. The code is available at github.com/chenchenzong/E2OAL.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Adaptive Multi-Scale Integration Unlocks Robust Cell Annotation in Histopathology Images
Nov 18, 2025Identifying cell types and subtypes in routine histopathology is fundamental for understanding disease. Existing tile-based models capture nuclear detail but miss the broader tissue context that influences cell identity. Current human annotations are coarse-grained and uneven across studies, making fine-grained, subtype-level classification difficult. In this study, we build a marker-guided dataset from Xenium spatial transcriptomics with single-cell resolution labels for more than two million cells across eight organs and 16 classes to address the lack of high-quality annotations. Leveraging this data resource, we introduce NuClass, a pathologist workflow inspired framework for cell-wise multi-scale integration of nuclear morphology and microenvironmental context. It combines Path local, which focuses on nuclear morphology from 224x224 pixel crops, and Path global, which models the surrounding 1024x1024 pixel neighborhood, through a learnable gating module that balances local and global information. An uncertainty-guided objective directs the global path to prioritize regions where the local path is uncertain, and we provide calibrated confidence estimates and Grad-CAM maps for interpretability. Evaluated on three fully held-out cohorts, NuClass achieves up to 96 percent F1 for its best-performing class, outperforming strong baselines. Our results demonstrate that multi-scale, uncertainty-aware fusion can bridge the gap between slide-level pathological foundation models and reliable, cell-level phenotype prediction.
Gene Incremental Learning for Single-Cell Transcriptomics
Nov 14, 2025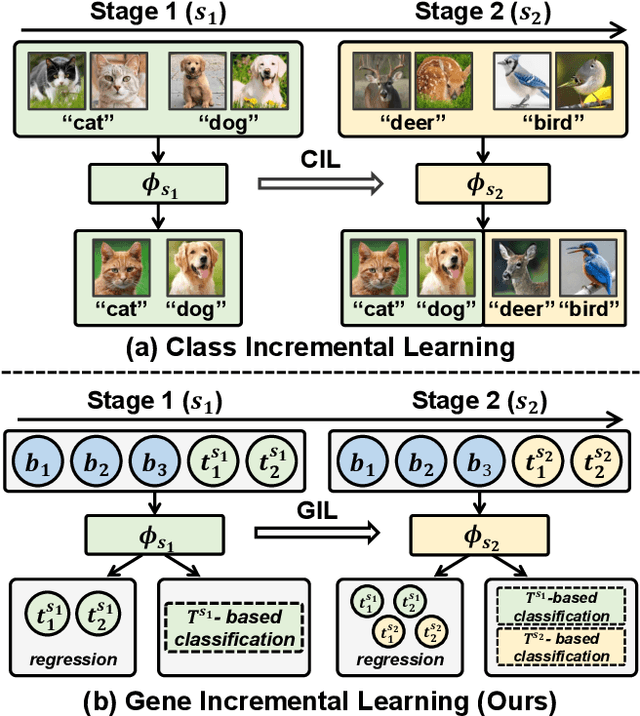
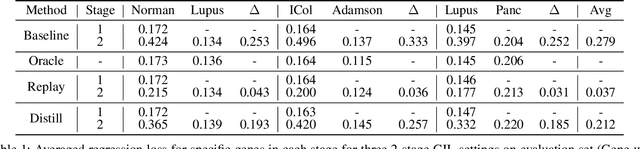
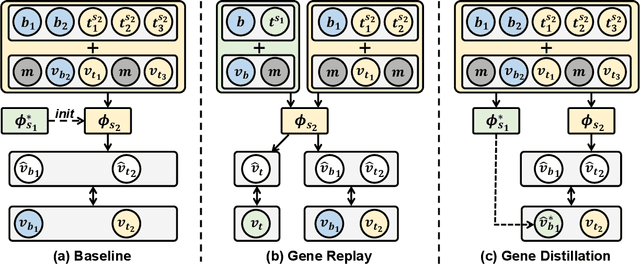
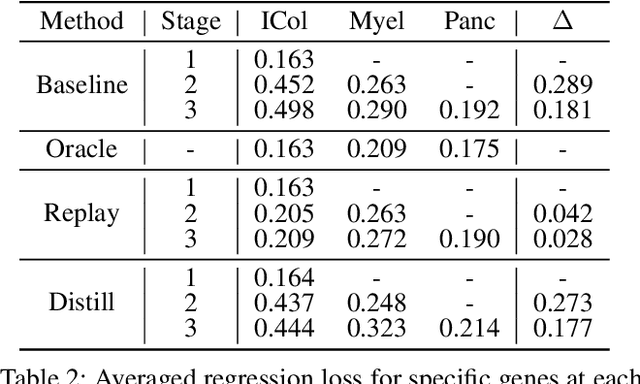
Classes, as fundamental elements of Computer Vision, have been extensively studied within incremental learning frameworks. In contrast, tokens, which play essential roles in many research fields, exhibit similar characteristics of growth, yet investigations into their incremental learning remain significantly scarce. This research gap primarily stems from the holistic nature of tokens in language, which imposes significant challenges on the design of incremental learning frameworks for them. To overcome this obstacle, in this work, we turn to a type of token, gene, for a large-scale biological dataset--single-cell transcriptomics--to formulate a pipeline for gene incremental learning and establish corresponding evaluations. We found that the forgetting problem also exists in gene incremental learning, thus we adapted existing class incremental learning methods to mitigate the forgetting of genes. Through extensive experiments, we demonstrated the soundness of our framework design and evaluations, as well as the effectiveness of our method adaptations. Finally, we provide a complete benchmark for gene incremental learning in single-cell transcriptomics.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
ST-FlowNet: An Efficient Spiking Neural Network for Event-Based Optical Flow Estimation
Mar 13, 2025Spiking Neural Networks (SNNs) have emerged as a promising tool for event-based optical flow estimation tasks due to their ability to leverage spatio-temporal information and low-power capabilities. However, the performance of SNN models is often constrained, limiting their application in real-world scenarios. In this work, we address this gap by proposing a novel neural network architecture, ST-FlowNet, specifically tailored for optical flow estimation from event-based data. The ST-FlowNet architecture integrates ConvGRU modules to facilitate cross-modal feature augmentation and temporal alignment of the predicted optical flow, improving the network's ability to capture complex motion dynamics. Additionally, to overcome the challenges associated with training SNNs, we introduce a novel approach to derive SNN models from pre-trained artificial neural networks (ANNs) through ANN-to-SNN conversion or our proposed BISNN method. Notably, the BISNN method alleviates the complexities involved in biological parameter selection, further enhancing the robustness of SNNs in optical flow estimation tasks. Extensive evaluations on three benchmark event-based datasets demonstrate that the SNN-based ST-FlowNet model outperforms state-of-the-art methods, delivering superior performance in accurate optical flow estimation across a diverse range of dynamic visual scenes. Furthermore, the inherent energy efficiency of SNN models is highlighted, establishing a compelling advantage for their practical deployment. Overall, our work presents a novel framework for optical flow estimation using SNNs and event-based data, contributing to the advancement of neuromorphic vision applications.
Reliable Object Tracking by Multimodal Hybrid Feature Extraction and Transformer-Based Fusion
May 28, 2024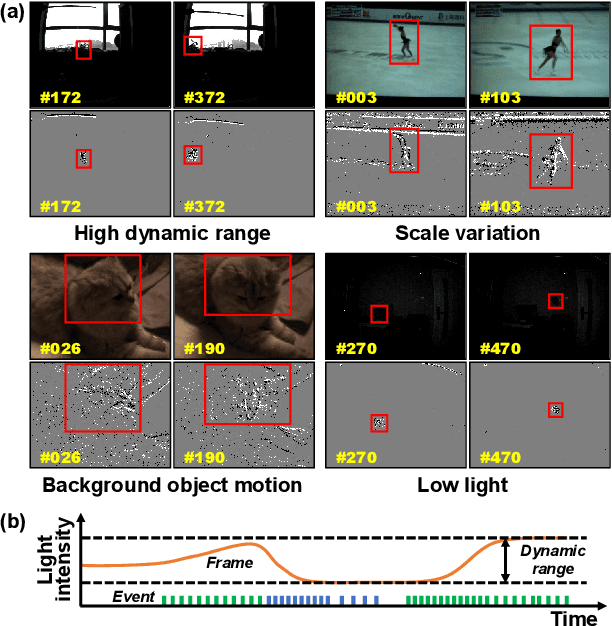

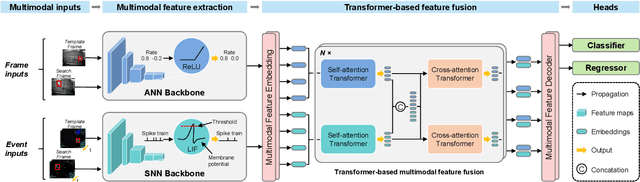
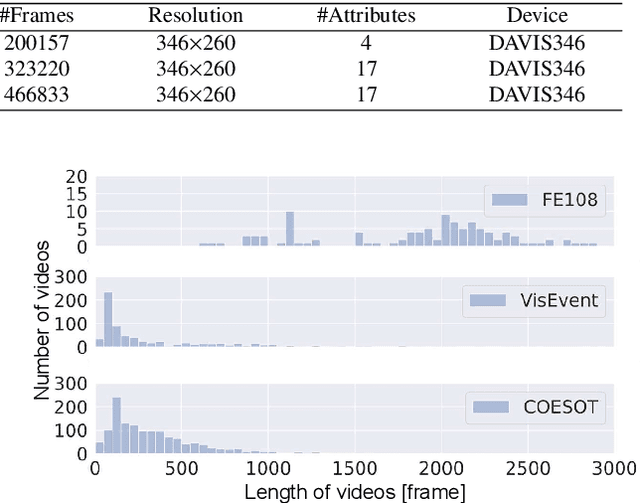
Visual object tracking, which is primarily based on visible light image sequences, encounters numerous challenges in complicated scenarios, such as low light conditions, high dynamic ranges, and background clutter. To address these challenges, incorporating the advantages of multiple visual modalities is a promising solution for achieving reliable object tracking. However, the existing approaches usually integrate multimodal inputs through adaptive local feature interactions, which cannot leverage the full potential of visual cues, thus resulting in insufficient feature modeling. In this study, we propose a novel multimodal hybrid tracker (MMHT) that utilizes frame-event-based data for reliable single object tracking. The MMHT model employs a hybrid backbone consisting of an artificial neural network (ANN) and a spiking neural network (SNN) to extract dominant features from different visual modalities and then uses a unified encoder to align the features across different domains. Moreover, we propose an enhanced transformer-based module to fuse multimodal features using attention mechanisms. With these methods, the MMHT model can effectively construct a multiscale and multidimensional visual feature space and achieve discriminative feature modeling. Extensive experiments demonstrate that the MMHT model exhibits competitive performance in comparison with that of other state-of-the-art methods. Overall, our results highlight the effectiveness of the MMHT model in terms of addressing the challenges faced in visual object tracking tasks.
Better Explain Transformers by Illuminating Important Information
Jan 26, 2024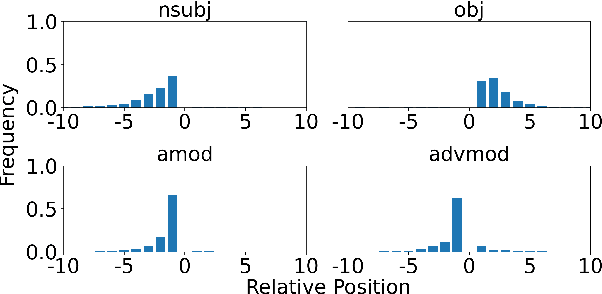
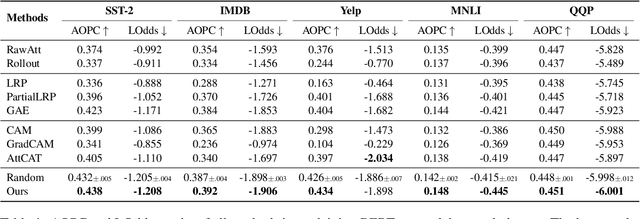
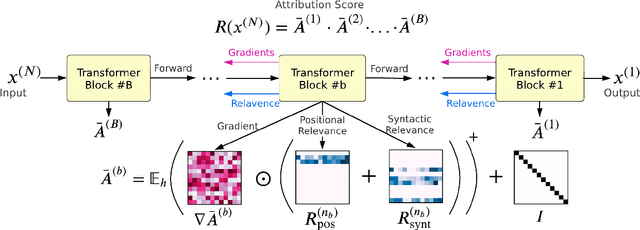
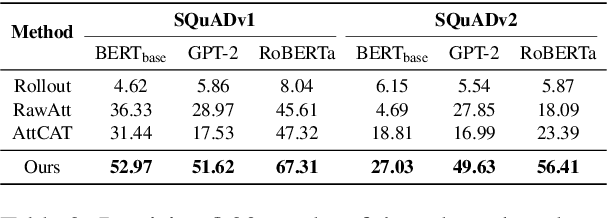
Transformer-based models excel in various natural language processing (NLP) tasks, attracting countless efforts to explain their inner workings. Prior methods explain Transformers by focusing on the raw gradient and attention as token attribution scores, where non-relevant information is often considered during explanation computation, resulting in confusing results. In this work, we propose highlighting the important information and eliminating irrelevant information by a refined information flow on top of the layer-wise relevance propagation (LRP) method. Specifically, we consider identifying syntactic and positional heads as important attention heads and focus on the relevance obtained from these important heads. Experimental results demonstrate that irrelevant information does distort output attribution scores and then should be masked during explanation computation. Compared to eight baselines on both classification and question-answering datasets, our method consistently outperforms with over 3\% to 33\% improvement on explanation metrics, providing superior explanation performance. Our anonymous code repository is available at: https://github.com/LinxinS97/Mask-LRP
CEIR: Concept-based Explainable Image Representation Learning
Dec 17, 2023In modern machine learning, the trend of harnessing self-supervised learning to derive high-quality representations without label dependency has garnered significant attention. However, the absence of label information, coupled with the inherently high-dimensional nature, improves the difficulty for the interpretation of learned representations. Consequently, indirect evaluations become the popular metric for evaluating the quality of these features, leading to a biased validation of the learned representation rationale. To address these challenges, we introduce a novel approach termed Concept-based Explainable Image Representation (CEIR). Initially, using the Concept-based Model (CBM) incorporated with pretrained CLIP and concepts generated by GPT-4, we project input images into a concept vector space. Subsequently, a Variational Autoencoder (VAE) learns the latent representation from these projected concepts, which serves as the final image representation. Due to the capability of the representation to encapsulate high-level, semantically relevant concepts, the model allows for attributions to a human-comprehensible concept space. This not only enhances interpretability but also preserves the robustness essential for downstream tasks. For instance, our method exhibits state-of-the-art unsupervised clustering performance on benchmarks such as CIFAR10, CIFAR100, and STL10. Furthermore, capitalizing on the universality of human conceptual understanding, CEIR can seamlessly extract the related concept from open-world images without fine-tuning. This offers a fresh approach to automatic label generation and label manipulation.