 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSPDI-SNN: An efficient lightweight SNN based on nonlinear synaptic pruning and dendritic integration
Aug 29, 2025Spiking neural networks (SNNs) are artificial neural networks based on simulated biological neurons and have attracted much attention in recent artificial intelligence technology studies. The dendrites in biological neurons have efficient information processing ability and computational power; however, the neurons of SNNs rarely match the complex structure of the dendrites. Inspired by the nonlinear structure and highly sparse properties of neuronal dendrites, in this study, we propose an efficient, lightweight SNN method with nonlinear pruning and dendritic integration (NSPDI-SNN). In this method, we introduce nonlinear dendritic integration (NDI) to improve the representation of the spatiotemporal information of neurons. We implement heterogeneous state transition ratios of dendritic spines and construct a new and flexible nonlinear synaptic pruning (NSP) method to achieve the high sparsity of SNN. We conducted systematic experiments on three benchmark datasets (DVS128 Gesture, CIFAR10-DVS, and CIFAR10) and extended the evaluation to two complex tasks (speech recognition and reinforcement learning-based maze navigation task). Across all tasks, NSPDI-SNN consistently achieved high sparsity with minimal performance degradation. In particular, our method achieved the best experimental results on all three event stream datasets. Further analysis showed that NSPDI significantly improved the efficiency of synaptic information transfer as sparsity increased. In conclusion, our results indicate that the complex structure and nonlinear computation of neuronal dendrites provide a promising approach for developing efficient SNN methods.
ST-FlowNet: An Efficient Spiking Neural Network for Event-Based Optical Flow Estimation
Mar 13, 2025Spiking Neural Networks (SNNs) have emerged as a promising tool for event-based optical flow estimation tasks due to their ability to leverage spatio-temporal information and low-power capabilities. However, the performance of SNN models is often constrained, limiting their application in real-world scenarios. In this work, we address this gap by proposing a novel neural network architecture, ST-FlowNet, specifically tailored for optical flow estimation from event-based data. The ST-FlowNet architecture integrates ConvGRU modules to facilitate cross-modal feature augmentation and temporal alignment of the predicted optical flow, improving the network's ability to capture complex motion dynamics. Additionally, to overcome the challenges associated with training SNNs, we introduce a novel approach to derive SNN models from pre-trained artificial neural networks (ANNs) through ANN-to-SNN conversion or our proposed BISNN method. Notably, the BISNN method alleviates the complexities involved in biological parameter selection, further enhancing the robustness of SNNs in optical flow estimation tasks. Extensive evaluations on three benchmark event-based datasets demonstrate that the SNN-based ST-FlowNet model outperforms state-of-the-art methods, delivering superior performance in accurate optical flow estimation across a diverse range of dynamic visual scenes. Furthermore, the inherent energy efficiency of SNN models is highlighted, establishing a compelling advantage for their practical deployment. Overall, our work presents a novel framework for optical flow estimation using SNNs and event-based data, contributing to the advancement of neuromorphic vision applications.
Reliable Object Tracking by Multimodal Hybrid Feature Extraction and Transformer-Based Fusion
May 28, 2024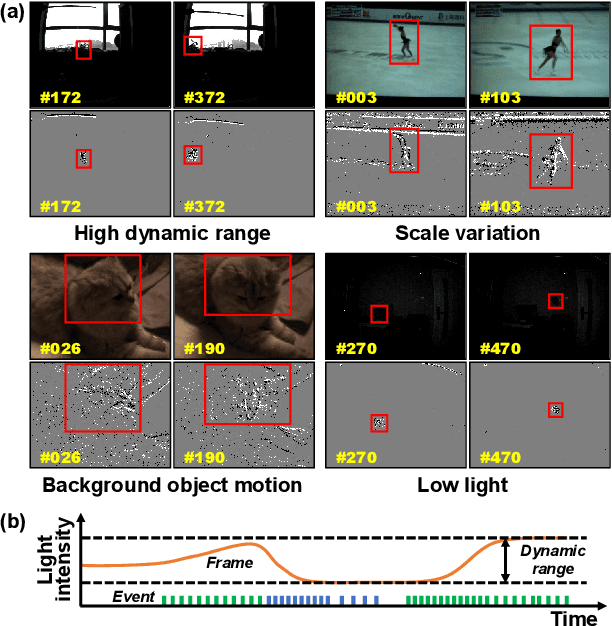

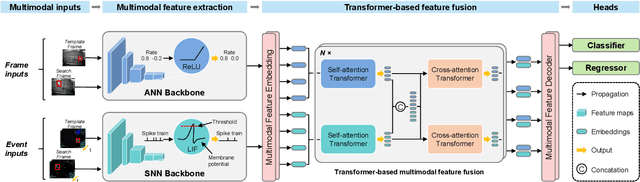
Visual object tracking, which is primarily based on visible light image sequences, encounters numerous challenges in complicated scenarios, such as low light conditions, high dynamic ranges, and background clutter. To address these challenges, incorporating the advantages of multiple visual modalities is a promising solution for achieving reliable object tracking. However, the existing approaches usually integrate multimodal inputs through adaptive local feature interactions, which cannot leverage the full potential of visual cues, thus resulting in insufficient feature modeling. In this study, we propose a novel multimodal hybrid tracker (MMHT) that utilizes frame-event-based data for reliable single object tracking. The MMHT model employs a hybrid backbone consisting of an artificial neural network (ANN) and a spiking neural network (SNN) to extract dominant features from different visual modalities and then uses a unified encoder to align the features across different domains. Moreover, we propose an enhanced transformer-based module to fuse multimodal features using attention mechanisms. With these methods, the MMHT model can effectively construct a multiscale and multidimensional visual feature space and achieve discriminative feature modeling. Extensive experiments demonstrate that the MMHT model exhibits competitive performance in comparison with that of other state-of-the-art methods. Overall, our results highlight the effectiveness of the MMHT model in terms of addressing the challenges faced in visual object tracking tasks.
A Spatial-channel-temporal-fused Attention for Spiking Neural Networks
Sep 22, 2022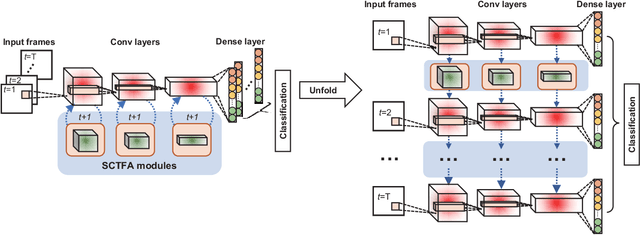
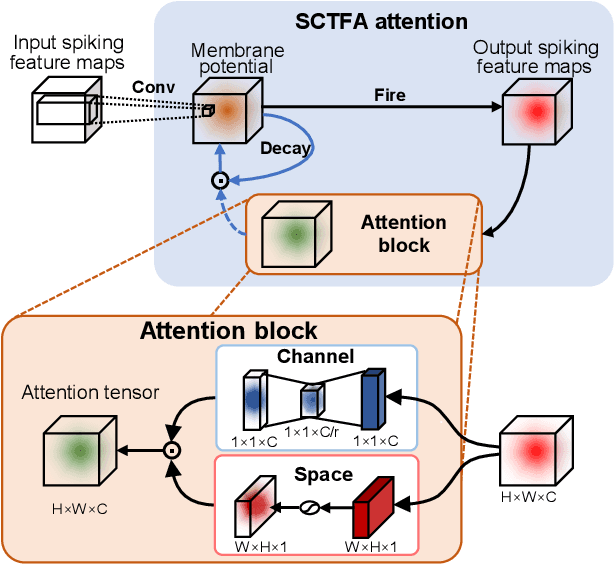
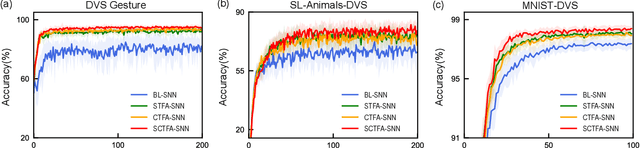
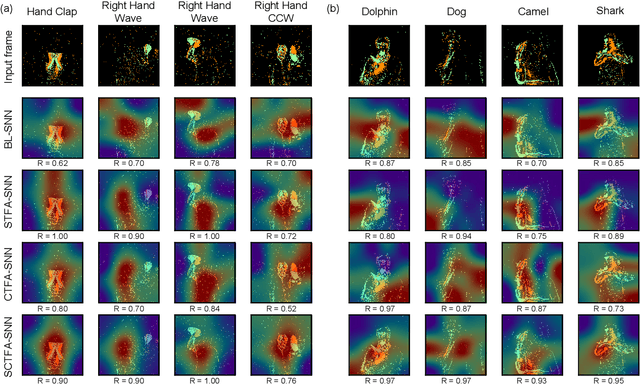
Spiking neural networks (SNNs) mimic brain computational strategies, and exhibit substantial capabilities in spatiotemporal information processing. As an essential factor for human perception, visual attention refers to the dynamic selection process of salient regions in biological vision systems. Although mechanisms of visual attention have achieved great success in computer vision, they are rarely introduced into SNNs. Inspired by experimental observations on predictive attentional remapping, we here propose a new spatial-channel-temporal-fused attention (SCTFA) module that can guide SNNs to efficiently capture underlying target regions by utilizing historically accumulated spatial-channel information. Through a systematic evaluation on three event stream datasets (DVS Gesture, SL-Animals-DVS and MNIST-DVS), we demonstrate that the SNN with the SCTFA module (SCTFA-SNN) not only significantly outperforms the baseline SNN (BL-SNN) and other two SNN models with degenerated attention modules, but also achieves competitive accuracy with existing state-of-the-art methods. Additionally, our detailed analysis shows that the proposed SCTFA-SNN model has strong robustness to noise and outstanding stability to incomplete data, while maintaining acceptable complexity and efficiency. Overall, these findings indicate that appropriately incorporating cognitive mechanisms of the brain may provide a promising approach to elevate the capability of SNNs.
A Synapse-Threshold Synergistic Learning Approach for Spiking Neural Networks
Jun 10, 2022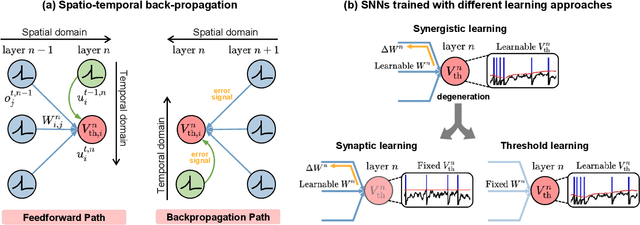
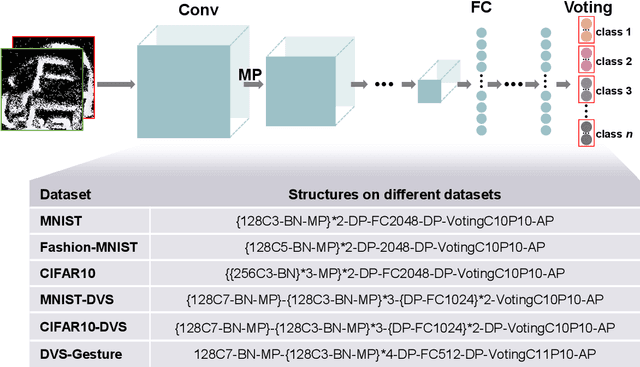
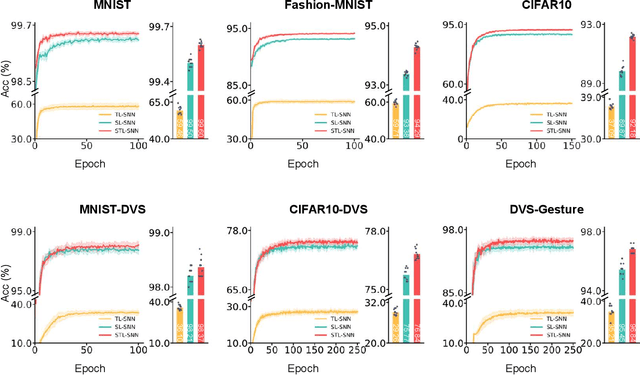
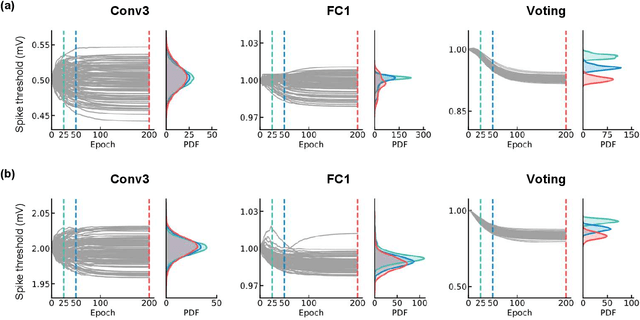
Spiking neural networks (SNNs) have demonstrated excellent capabilities in various intelligent scenarios. Most existing methods for training SNNs are based on the concept of synaptic plasticity; however, learning in the realistic brain also utilizes intrinsic non-synaptic mechanisms of neurons. The spike threshold of biological neurons is a critical intrinsic neuronal feature that exhibits rich dynamics on a millisecond timescale and has been proposed as an underlying mechanism that facilitates neural information processing. In this study, we develop a novel synergistic learning approach that simultaneously trains synaptic weights and spike thresholds in SNNs. SNNs trained with synapse-threshold synergistic learning (STL-SNNs) achieve significantly higher accuracies on various static and neuromorphic datasets than SNNs trained with two single-learning models of the synaptic learning (SL) and the threshold learning (TL). During training, the synergistic learning approach optimizes neural thresholds, providing the network with stable signal transmission via appropriate firing rates. Further analysis indicates that STL-SNNs are robust to noisy data and exhibit low energy consumption for deep network structures. Additionally, the performance of STL-SNN can be further improved by introducing a generalized joint decision framework (JDF). Overall, our findings indicate that biologically plausible synergies between synaptic and intrinsic non-synaptic mechanisms may provide a promising approach for developing highly efficient SNN learning methods.