 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatial-channel-temporal-fused Attention for Spiking Neural Networks
Paper and Code
Sep 22, 2022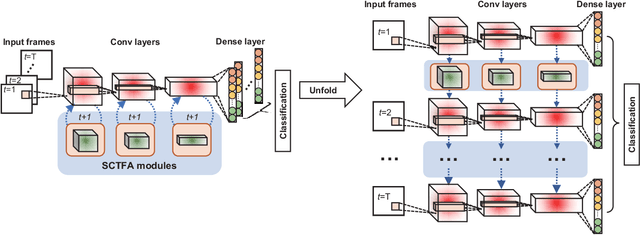
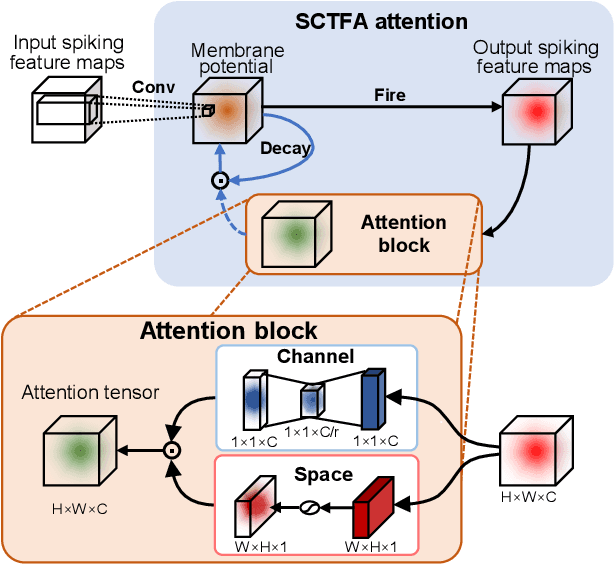
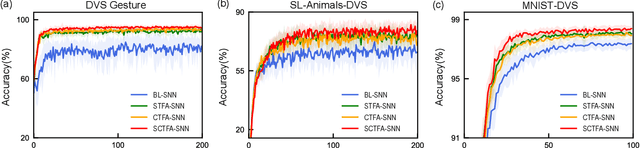
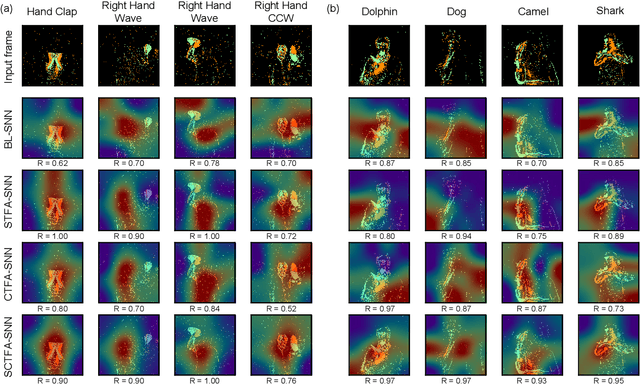
Spiking neural networks (SNNs) mimic brain computational strategies, and exhibit substantial capabilities in spatiotemporal information processing. As an essential factor for human perception, visual attention refers to the dynamic selection process of salient regions in biological vision systems. Although mechanisms of visual attention have achieved great success in computer vision, they are rarely introduced into SNNs. Inspired by experimental observations on predictive attentional remapping, we here propose a new spatial-channel-temporal-fused attention (SCTFA) module that can guide SNNs to efficiently capture underlying target regions by utilizing historically accumulated spatial-channel information. Through a systematic evaluation on three event stream datasets (DVS Gesture, SL-Animals-DVS and MNIST-DVS), we demonstrate that the SNN with the SCTFA module (SCTFA-SNN) not only significantly outperforms the baseline SNN (BL-SNN) and other two SNN models with degenerated attention modules, but also achieves competitive accuracy with existing state-of-the-art methods. Additionally, our detailed analysis shows that the proposed SCTFA-SNN model has strong robustness to noise and outstanding stability to incomplete data, while maintaining acceptable complexity and efficiency. Overall, these findings indicate that appropriately incorporating cognitive mechanisms of the brain may provide a promising approach to elevate the capability of SNNs.