 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Spiking Neural Networks Using a Single Neuron with Autapses
Mar 25, 2026Spiking neural networks (SNNs) are promising for neuromorphic computing, but high-performing models still rely on dense multilayer architectures with substantial communication and state-storage costs. Inspired by autapses, we propose time-delayed autapse SNN (TDA-SNN), a framework that reconstructs SNNs with a single leaky integrate-and-fire neuron and a prototype-learning-based training strategy. By reorganizing internal temporal states, TDA-SNN can realize reservoir, multilayer perceptron, and convolution-like spiking architectures within a unified framework. Experiments on sequential, event-based, and image benchmarks show competitive performance in reservoir and MLP settings, while convolutional results reveal a clear space--time trade-off. Compared with standard SNNs, TDA-SNN greatly reduces neuron count and state memory while increasing per-neuron information capacity, at the cost of additional temporal latency in extreme single-neuron settings. These findings highlight the potential of temporally multiplexed single-neuron models as compact computational units for brain-inspired computing.
BreathNet: Generalizable Audio Deepfake Detection via Breath-Cue-Guided Feature Refinement
Feb 14, 2026As deepfake audio becomes more realistic and diverse, developing generalizable countermeasure systems has become crucial. Existing detection methods primarily depend on XLS-R front-end features to improve generalization. Nonetheless, their performance remains limited, partly due to insufficient attention to fine-grained information, such as physiological cues or frequency-domain features. In this paper, we propose BreathNet, a novel audio deepfake detection framework that integrates fine-grained breath information to improve generalization. Specifically, we design BreathFiLM, a feature-wise linear modulation mechanism that selectively amplifies temporal representations based on the presence of breathing sounds. BreathFiLM is trained jointly with the XLS-R extractor, in turn encouraging the extractor to learn and encode breath-related cues into the temporal features. Then, we use the frequency front-end to extract spectral features, which are then fused with temporal features to provide complementary information introduced by vocoders or compression artifacts. Additionally, we propose a group of feature losses comprising Positive-only Supervised Contrastive Loss (PSCL), center loss, and contrast loss. These losses jointly enhance the discriminative ability, encouraging the model to separate bona fide and deepfake samples more effectively in the feature space. Extensive experiments on five benchmark datasets demonstrate state-of-the-art (SOTA) performance. Using the ASVspoof 2019 LA training set, our method attains 1.99% average EER across four related eval benchmarks, with particularly strong performance on the In-the-Wild dataset, where it achieves 4.70% EER. Moreover, under the ASVspoof5 evaluation protocol, our method achieves an EER of 4.94% on this latest benchmark.
Cross-reality Location Privacy Protection in 6G-enabled Vehicular Metaverses: An LLM-enhanced Hybrid Generative Diffusion Model-based Approach
Jan 18, 2026The emergence of 6G-enabled vehicular metaverses enables Autonomous Vehicles (AVs) to operate across physical and virtual spaces through space-air-ground-sea integrated networks. The AVs can deploy AI agents powered by large AI models as personalized assistants, on edge servers to support intelligent driving decision making and enhanced on-board experiences. However, such cross-reality interactions may cause serious location privacy risks, as adversaries can infer AV trajectories by correlating the location reported when AVs request LBS in reality with the location of the edge servers on which their corresponding AI agents are deployed in virtuality. To address this challenge, we design a cross-reality location privacy protection framework based on hybrid actions, including continuous location perturbation in reality and discrete privacy-aware AI agent migration in virtuality. In this framework, a new privacy metric, termed cross-reality location entropy, is proposed to effectively quantify the privacy levels of AVs. Based on this metric, we formulate an optimization problem to optimize the hybrid action, focusing on achieving a balance between location protection, service latency reduction, and quality of service maintenance. To solve the complex mixed-integer problem, we develop a novel LLM-enhanced Hybrid Diffusion Proximal Policy Optimization (LHDPPO) algorithm, which integrates LLM-driven informative reward design to enhance environment understanding with double Generative Diffusion Models-based policy exploration to handle high-dimensional action spaces, thereby enabling reliable determination of optimal hybrid actions. Extensive experiments on real-world datasets demonstrate that the proposed framework effectively mitigates cross-reality location privacy leakage for AVs while maintaining strong user immersion within 6G-enabled vehicular metaverse scenarios.
MedFact: Benchmarking the Fact-Checking Capabilities of Large Language Models on Chinese Medical Texts
Sep 15, 2025The increasing deployment of Large Language Models (LLMs) in healthcare necessitates a rigorous evaluation of their factual reliability. However, existing benchmarks are often limited by narrow domains of data, failing to capture the complexity of real-world medical information. To address this critical gap, we introduce MedFact, a new and challenging benchmark for Chinese medical fact-checking. MedFact comprises 2,116 expert-annotated instances curated from diverse real-world texts, spanning 13 medical specialties, 8 fine-grained error types, 4 writing styles, and multiple difficulty levels. Its construction employs a hybrid AI-human framework where iterative expert feedback refines an AI-driven, multi-criteria filtering process, ensuring both high data quality and difficulty. We conduct a comprehensive evaluation of 20 leading LLMs, benchmarking their performance on veracity classification and error localization against a human expert baseline. Our results reveal that while models can often determine if a text contains an error, precisely localizing it remains a substantial challenge, with even top-performing models falling short of human performance. Furthermore, our analysis uncovers a frequent ``over-criticism'' phenomenon, a tendency for models to misidentify correct information as erroneous, which is exacerbated by advanced reasoning techniques such as multi-agent collaboration and inference-time scaling. By highlighting these critical challenges for deploying LLMs in medical applications, MedFact provides a robust resource to drive the development of more factually reliable and medically aware models.
NSPDI-SNN: An efficient lightweight SNN based on nonlinear synaptic pruning and dendritic integration
Aug 29, 2025Spiking neural networks (SNNs) are artificial neural networks based on simulated biological neurons and have attracted much attention in recent artificial intelligence technology studies. The dendrites in biological neurons have efficient information processing ability and computational power; however, the neurons of SNNs rarely match the complex structure of the dendrites. Inspired by the nonlinear structure and highly sparse properties of neuronal dendrites, in this study, we propose an efficient, lightweight SNN method with nonlinear pruning and dendritic integration (NSPDI-SNN). In this method, we introduce nonlinear dendritic integration (NDI) to improve the representation of the spatiotemporal information of neurons. We implement heterogeneous state transition ratios of dendritic spines and construct a new and flexible nonlinear synaptic pruning (NSP) method to achieve the high sparsity of SNN. We conducted systematic experiments on three benchmark datasets (DVS128 Gesture, CIFAR10-DVS, and CIFAR10) and extended the evaluation to two complex tasks (speech recognition and reinforcement learning-based maze navigation task). Across all tasks, NSPDI-SNN consistently achieved high sparsity with minimal performance degradation. In particular, our method achieved the best experimental results on all three event stream datasets. Further analysis showed that NSPDI significantly improved the efficiency of synaptic information transfer as sparsity increased. In conclusion, our results indicate that the complex structure and nonlinear computation of neuronal dendrites provide a promising approach for developing efficient SNN methods.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Motion is the Choreographer: Learning Latent Pose Dynamics for Seamless Sign Language Generation
Aug 06, 2025Sign language video generation requires producing natural signing motions with realistic appearances under precise semantic control, yet faces two critical challenges: excessive signer-specific data requirements and poor generalization. We propose a new paradigm for sign language video generation that decouples motion semantics from signer identity through a two-phase synthesis framework. First, we construct a signer-independent multimodal motion lexicon, where each gloss is stored as identity-agnostic pose, gesture, and 3D mesh sequences, requiring only one recording per sign. This compact representation enables our second key innovation: a discrete-to-continuous motion synthesis stage that transforms retrieved gloss sequences into temporally coherent motion trajectories, followed by identity-aware neural rendering to produce photorealistic videos of arbitrary signers. Unlike prior work constrained by signer-specific datasets, our method treats motion as a first-class citizen: the learned latent pose dynamics serve as a portable "choreography layer" that can be visually realized through different human appearances. Extensive experiments demonstrate that disentangling motion from identity is not just viable but advantageous - enabling both high-quality synthesis and unprecedented flexibility in signer personalization.
StgcDiff: Spatial-Temporal Graph Condition Diffusion for Sign Language Transition Generation
Jun 16, 2025Sign language transition generation seeks to convert discrete sign language segments into continuous sign videos by synthesizing smooth transitions. However,most existing methods merely concatenate isolated signs, resulting in poor visual coherence and semantic accuracy in the generated videos. Unlike textual languages,sign language is inherently rich in spatial-temporal cues, making it more complex to model. To address this,we propose StgcDiff, a graph-based conditional diffusion framework that generates smooth transitions between discrete signs by capturing the unique spatial-temporal dependencies of sign language. Specifically, we first train an encoder-decoder architecture to learn a structure-aware representation of spatial-temporal skeleton sequences. Next, we optimize a diffusion denoiser conditioned on the representations learned by the pre-trained encoder, which is tasked with predicting transition frames from noise. Additionally, we design the Sign-GCN module as the key component in our framework, which effectively models the spatial-temporal features. Extensive experiments conducted on the PHOENIX14T, USTC-CSL100,and USTC-SLR500 datasets demonstrate the superior performance of our method.
$\mathcal{A}LLM4ADD$: Unlocking the Capabilities of Audio Large Language Models for Audio Deepfake Detection
May 16, 2025
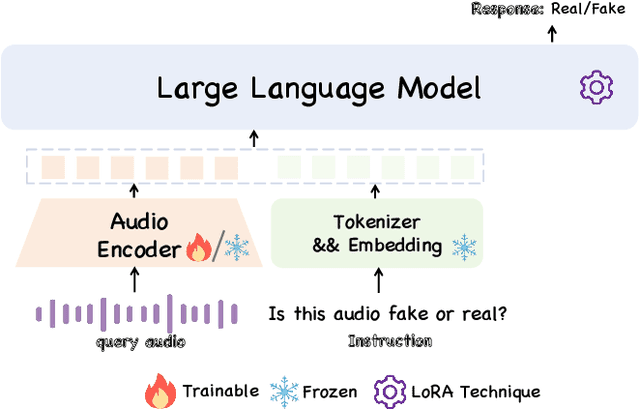

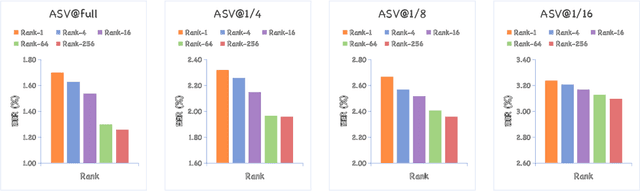
Audio deepfake detection (ADD) has grown increasingly important due to the rise of high-fidelity audio generative models and their potential for misuse. Given that audio large language models (ALLMs) have made significant progress in various audio processing tasks, a heuristic question arises: Can ALLMs be leveraged to solve ADD?. In this paper, we first conduct a comprehensive zero-shot evaluation of ALLMs on ADD, revealing their ineffectiveness in detecting fake audio. To enhance their performance, we propose $\mathcal{A}LLM4ADD$, an ALLM-driven framework for ADD. Specifically, we reformulate ADD task as an audio question answering problem, prompting the model with the question: "Is this audio fake or real?". We then perform supervised fine-tuning to enable the ALLM to assess the authenticity of query audio. Extensive experiments are conducted to demonstrate that our ALLM-based method can achieve superior performance in fake audio detection, particularly in data-scarce scenarios. As a pioneering study, we anticipate that this work will inspire the research community to leverage ALLMs to develop more effective ADD systems.
Text-Driven Diffusion Model for Sign Language Production
Mar 20, 2025We introduce the hfut-lmc team's solution to the SLRTP Sign Production Challenge. The challenge aims to generate semantically aligned sign language pose sequences from text inputs. To this end, we propose a Text-driven Diffusion Model (TDM) framework. During the training phase, TDM utilizes an encoder to encode text sequences and incorporates them into the diffusion model as conditional input to generate sign pose sequences. To guarantee the high quality and accuracy of the generated pose sequences, we utilize two key loss functions. The joint loss function L_{joint} is used to precisely measure and minimize the differences between the joint positions of the generated pose sequences and those of the ground truth. Similarly, the bone orientation loss function L_{bone} is instrumental in ensuring that the orientation of the bones in the generated poses aligns with the actual, correct orientations. In the inference stage, the TDM framework takes on a different yet equally important task. It starts with noisy sequences and, under the strict constraints of the text conditions, gradually refines and generates semantically consistent sign language pose sequences. Our carefully designed framework performs well on the sign language production task, and our solution achieves a BLEU-1 score of 20.17, placing second in the challenge.