 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftCap: Soft-Budget Control for Diffusion Transformer Acceleration
May 26, 2026Diffusion Transformers (DiTs) achieve strong visual quality, but their iterative denoising process requires many costly Transformer evaluations. Training-free acceleration methods reduce this cost by caching, forecasting, or verifying intermediate features, yet the runtime decision of when to execute a Full step is often driven by fixed schedules or hand-tuned thresholds. We propose \textbf{SoftCap}, a training-free control layer for cache-based DiT inference. SoftCap couples a Trajectory Drift Observer, which estimates local cache risk from lightweight hidden-state statistics, with a Soft-Budget PI Controller, which adjusts the Full-triggering threshold from realized compute relative to a fixed reference profile. The budget is a soft ceiling: it shapes the threshold but does not require a run to spend a prescribed number of Full evaluations. On FLUX.1-dev, SoftCap improves over SpeCa at a comparable middle-compute operating point, raising ImageReward from 0.967 to 0.981 and reducing LPIPS-Full from 0.518 to 0.498 at nearly identical FLOPs, while target-sweep diagnostics show the intended soft-ceiling behavior as the budget is relaxed.
Accelerating Controllable Generation via Hybrid-grained Cache
Nov 14, 2025Controllable generative models have been widely used to improve the realism of synthetic visual content. However, such models must handle control conditions and content generation computational requirements, resulting in generally low generation efficiency. To address this issue, we propose a Hybrid-Grained Cache (HGC) approach that reduces computational overhead by adopting cache strategies with different granularities at different computational stages. Specifically, (1) we use a coarse-grained cache (block-level) based on feature reuse to dynamically bypass redundant computations in encoder-decoder blocks between each step of model reasoning. (2) We design a fine-grained cache (prompt-level) that acts within a module, where the fine-grained cache reuses cross-attention maps within consecutive reasoning steps and extends them to the corresponding module computations of adjacent steps. These caches of different granularities can be seamlessly integrated into each computational link of the controllable generation process. We verify the effectiveness of HGC on four benchmark datasets, especially its advantages in balancing generation efficiency and visual quality. For example, on the COCO-Stuff segmentation benchmark, our HGC significantly reduces the computational cost (MACs) by 63% (from 18.22T to 6.70T), while keeping the loss of semantic fidelity (quantized performance degradation) within 1.5%.
StgcDiff: Spatial-Temporal Graph Condition Diffusion for Sign Language Transition Generation
Jun 16, 2025Sign language transition generation seeks to convert discrete sign language segments into continuous sign videos by synthesizing smooth transitions. However,most existing methods merely concatenate isolated signs, resulting in poor visual coherence and semantic accuracy in the generated videos. Unlike textual languages,sign language is inherently rich in spatial-temporal cues, making it more complex to model. To address this,we propose StgcDiff, a graph-based conditional diffusion framework that generates smooth transitions between discrete signs by capturing the unique spatial-temporal dependencies of sign language. Specifically, we first train an encoder-decoder architecture to learn a structure-aware representation of spatial-temporal skeleton sequences. Next, we optimize a diffusion denoiser conditioned on the representations learned by the pre-trained encoder, which is tasked with predicting transition frames from noise. Additionally, we design the Sign-GCN module as the key component in our framework, which effectively models the spatial-temporal features. Extensive experiments conducted on the PHOENIX14T, USTC-CSL100,and USTC-SLR500 datasets demonstrate the superior performance of our method.
Hierarchical Space-Time Attention for Micro-Expression Recognition
May 06, 2024



Micro-expression recognition (MER) aims to recognize the short and subtle facial movements from the Micro-expression (ME) video clips, which reveal real emotions. Recent MER methods mostly only utilize special frames from ME video clips or extract optical flow from these special frames. However, they neglect the relationship between movements and space-time, while facial cues are hidden within these relationships. To solve this issue, we propose the Hierarchical Space-Time Attention (HSTA). Specifically, we first process ME video frames and special frames or data parallelly by our cascaded Unimodal Space-Time Attention (USTA) to establish connections between subtle facial movements and specific facial areas. Then, we design Crossmodal Space-Time Attention (CSTA) to achieve a higher-quality fusion for crossmodal data. Finally, we hierarchically integrate USTA and CSTA to grasp the deeper facial cues. Our model emphasizes temporal modeling without neglecting the processing of special data, and it fuses the contents in different modalities while maintaining their respective uniqueness. Extensive experiments on the four benchmarks show the effectiveness of our proposed HSTA. Specifically, compared with the latest method on the CASME3 dataset, it achieves about 3% score improvement in seven-category classification.
Compact Bidirectional Transformer for Image Captioning
Jan 06, 2022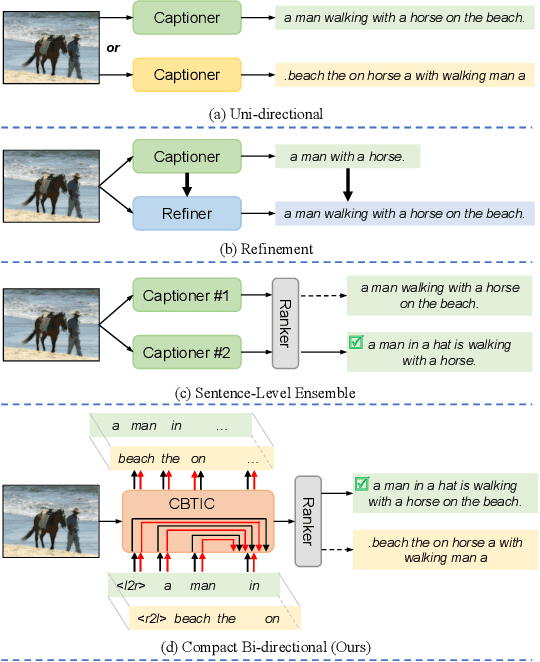



Most current image captioning models typically generate captions from left to right. This unidirectional property makes them can only leverage past context but not future context. Though recent refinement-based models can exploit both past and future context by generating a new caption in the second stage based on pre-retrieved or pre-generated captions in the first stage, the decoder of these models generally consists of two networks~(i.e. a retriever or captioner in the first stage and a refiner in the second stage), which can only be executed sequentially. In this paper, we introduce a Compact Bidirectional Transformer model for image captioning that can leverage bidirectional context implicitly and explicitly while the decoder can be executed parallelly. Specifically, it is implemented by tightly coupling left-to-right(L2R) and right-to-left(R2L) flows into a single compact model~(i.e. implicitly) and optionally allowing interaction of the two flows(i.e. explicitly), while the final caption is chosen from either L2R or R2L flow in a sentence-level ensemble manner. We conduct extensive ablation studies on the MSCOCO benchmark and find that the compact architecture, which serves as a regularization for implicitly exploiting bidirectional context, and the sentence-level ensemble play more important roles than the explicit interaction mechanism. By combining with word-level ensemble seamlessly, the effect of the sentence-level ensemble is further enlarged. We further extend the conventional one-flow self-critical training to the two-flows version under this architecture and achieve new state-of-the-art results in comparison with non-vision-language-pretraining models. Source code is available at {\color{magenta}\url{https://github.com/YuanEZhou/CBTrans}}.