 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Bidirectional Transformer for Image Captioning
Jan 06, 2022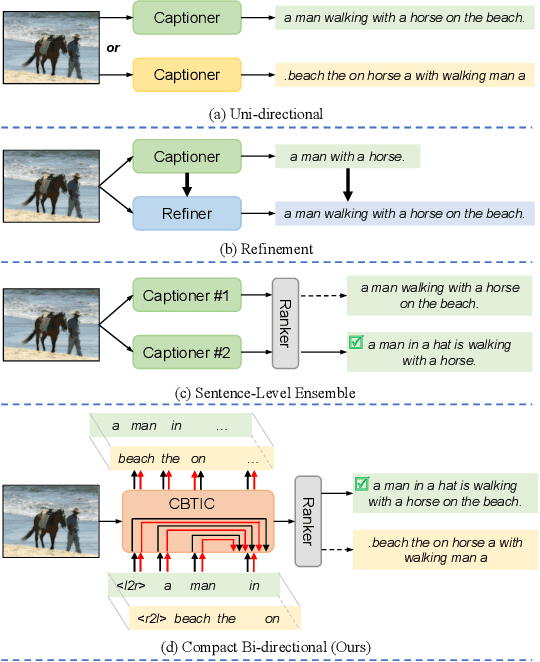



Most current image captioning models typically generate captions from left to right. This unidirectional property makes them can only leverage past context but not future context. Though recent refinement-based models can exploit both past and future context by generating a new caption in the second stage based on pre-retrieved or pre-generated captions in the first stage, the decoder of these models generally consists of two networks~(i.e. a retriever or captioner in the first stage and a refiner in the second stage), which can only be executed sequentially. In this paper, we introduce a Compact Bidirectional Transformer model for image captioning that can leverage bidirectional context implicitly and explicitly while the decoder can be executed parallelly. Specifically, it is implemented by tightly coupling left-to-right(L2R) and right-to-left(R2L) flows into a single compact model~(i.e. implicitly) and optionally allowing interaction of the two flows(i.e. explicitly), while the final caption is chosen from either L2R or R2L flow in a sentence-level ensemble manner. We conduct extensive ablation studies on the MSCOCO benchmark and find that the compact architecture, which serves as a regularization for implicitly exploiting bidirectional context, and the sentence-level ensemble play more important roles than the explicit interaction mechanism. By combining with word-level ensemble seamlessly, the effect of the sentence-level ensemble is further enlarged. We further extend the conventional one-flow self-critical training to the two-flows version under this architecture and achieve new state-of-the-art results in comparison with non-vision-language-pretraining models. Source code is available at {\color{magenta}\url{https://github.com/YuanEZhou/CBTrans}}.
Semi-Autoregressive Transformer for Image Captioning
Jun 17, 2021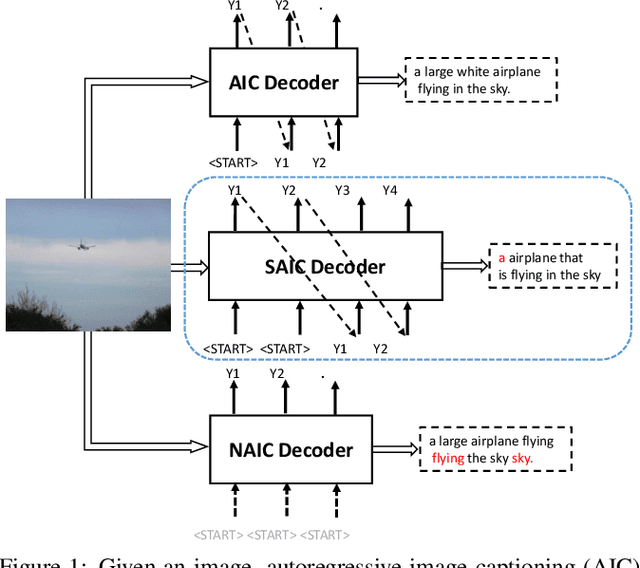

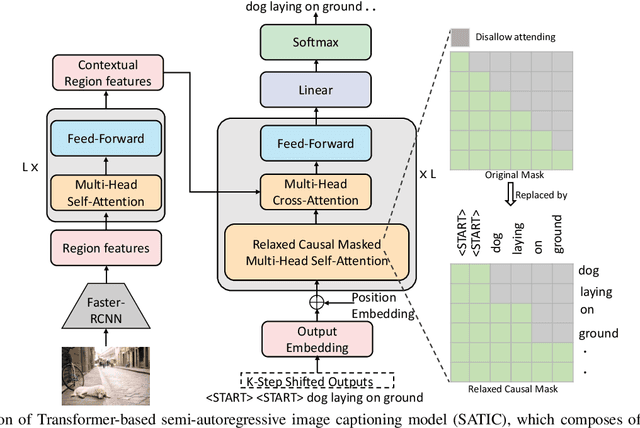
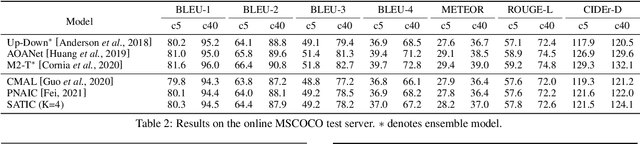
Current state-of-the-art image captioning models adopt autoregressive decoders, \ie they generate each word by conditioning on previously generated words, which leads to heavy latency during inference. To tackle this issue, non-autoregressive image captioning models have recently been proposed to significantly accelerate the speed of inference by generating all words in parallel. However, these non-autoregressive models inevitably suffer from large generation quality degradation since they remove words dependence excessively. To make a better trade-off between speed and quality, we introduce a semi-autoregressive model for image captioning~(dubbed as SATIC), which keeps the autoregressive property in global but generates words parallelly in local. Based on Transformer, there are only a few modifications needed to implement SATIC. Extensive experiments on the MSCOCO image captioning benchmark show that SATIC can achieve a better trade-off without bells and whistles. Code is available at {\color{magenta}\url{https://github.com/YuanEZhou/satic}}.
More Grounded Image Captioning by Distilling Image-Text Matching Model
Apr 01, 2020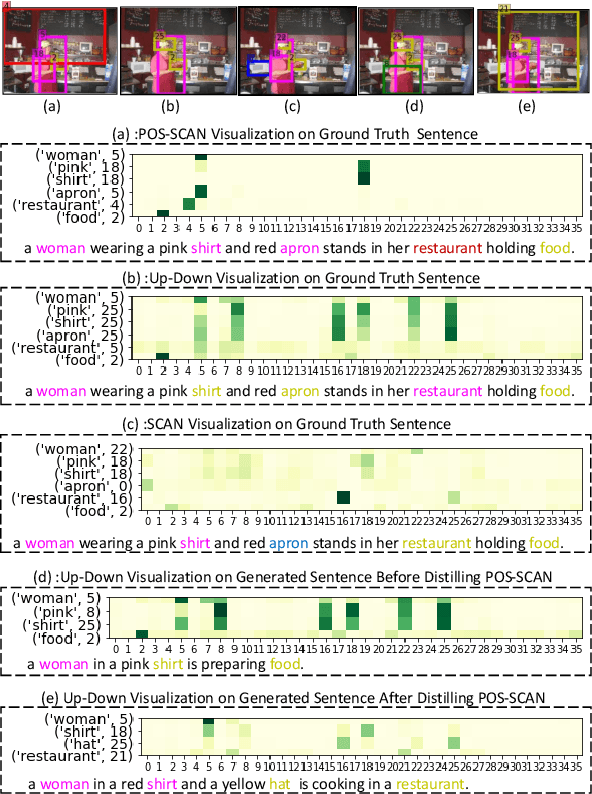

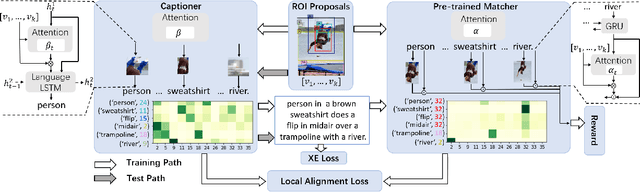

Visual attention not only improves the performance of image captioners, but also serves as a visual interpretation to qualitatively measure the caption rationality and model transparency. Specifically, we expect that a captioner can fix its attentive gaze on the correct objects while generating the corresponding words. This ability is also known as grounded image captioning. However, the grounding accuracy of existing captioners is far from satisfactory. To improve the grounding accuracy while retaining the captioning quality, it is expensive to collect the word-region alignment as strong supervision. To this end, we propose a Part-of-Speech (POS) enhanced image-text matching model (SCAN \cite{lee2018stacked}): POS-SCAN, as the effective knowledge distillation for more grounded image captioning. The benefits are two-fold: 1) given a sentence and an image, POS-SCAN can ground the objects more accurately than SCAN; 2) POS-SCAN serves as a word-region alignment regularization for the captioner's visual attention module. By showing benchmark experimental results, we demonstrate that conventional image captioners equipped with POS-SCAN can significantly improve the grounding accuracy without strong supervision. Last but not the least, we explore the indispensable Self-Critical Sequence Training (SCST) \cite{Rennie_2017_CVPR} in the context of grounded image captioning and show that the image-text matching score can serve as a reward for more grounded captioning \footnote{https://github.com/YuanEZhou/Grounded-Image-Captioning}.